
Los datos se han vuelto cada vez más importantes para construir modelos de aprendizaje automático, probar aplicaciones y obtener información comercial.
Sin embargo, para cumplir con las muchas regulaciones de datos, a menudo se guardan y se protegen estrictamente. Acceder a dichos datos podría llevar meses para obtener las aprobaciones necesarias. Alternativamente, las empresas pueden usar datos sintéticos.
Tabla de contenido
¿Qué son los datos sintéticos?
Crédito de la foto: Twinify
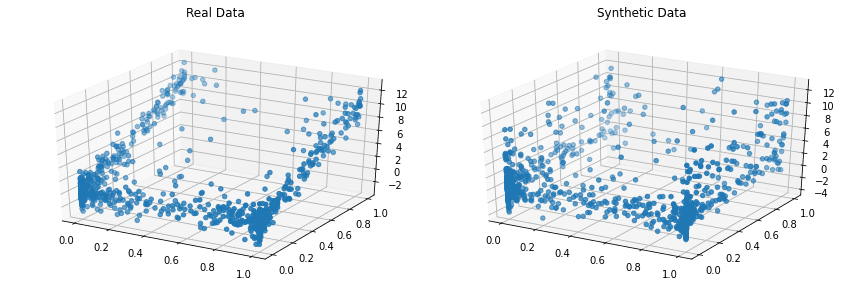
Los datos sintéticos son datos generados artificialmente que estadísticamente se asemejan al antiguo conjunto de datos. Se puede usar con datos reales para respaldar y mejorar los modelos de IA o se puede usar como un sustituto por completo.
Debido a que no pertenece a ningún sujeto de datos y no contiene información de identificación personal ni datos confidenciales, como números de seguro social, se puede utilizar como una alternativa de protección de la privacidad a los datos de producción reales.
Diferencias entre datos reales y sintéticos
- La diferencia más crucial está en cómo se generan los dos tipos de datos. Los datos reales provienen de sujetos reales cuyos datos se recopilaron durante encuestas o mientras usaban su aplicación. Por otro lado, los datos sintéticos se generan artificialmente pero aún se parecen al conjunto de datos original.
- La segunda diferencia está en la normativa de protección de datos que afecta a los datos reales y sintéticos. Con datos reales, los sujetos deberían poder saber qué datos sobre ellos se recopilan y por qué se recopilan, y existen límites sobre cómo se pueden usar. Sin embargo, esas regulaciones ya no se aplican a los datos sintéticos porque los datos no se pueden atribuir a un sujeto y no contienen información personal.
- La tercera diferencia está en la cantidad de datos disponibles. Con datos reales, solo puedes tener tanto como los usuarios te dan. Por otro lado, puede generar tantos datos sintéticos como desee.
Por qué debería considerar el uso de datos sintéticos
- Es relativamente más barato de producir porque puede generar conjuntos de datos mucho más grandes que se asemejan al conjunto de datos más pequeño que ya tiene. Esto significa que sus modelos de aprendizaje automático tendrán más datos para entrenar.
- Los datos generados se etiquetan y limpian automáticamente para usted. Esto significa que no tiene que dedicar tiempo a preparar los datos para el aprendizaje automático o el análisis.
- No hay problemas de privacidad ya que los datos no son de identificación personal y no pertenecen a un sujeto de datos. Esto significa que puede usarlo y compartirlo libremente.
- Puede superar el sesgo de la IA asegurándose de que las clases minoritarias estén bien representadas. Esto lo ayuda a construir una IA justa y responsable.
Cómo generar datos sintéticos
Si bien el proceso de generación varía según la herramienta que esté utilizando, generalmente, el proceso comienza con la conexión de un generador a un conjunto de datos existente. Después de lo cual, identifica los campos de identificación personal en su conjunto de datos y los etiqueta para su exclusión u ofuscación.
Luego, el generador comienza a identificar los tipos de datos de las columnas restantes y los patrones estadísticos en esas columnas. A partir de entonces, puede generar tantos datos sintéticos como necesite.
Por lo general, puede comparar los datos generados con el conjunto de datos original para ver qué tan bien se parecen los datos sintéticos a los datos reales.
Ahora, exploraremos las herramientas para la generación de datos sintéticos para entrenar modelos de aprendizaje automático.
Mayormente IA

Mostly AI tiene un generador de datos sintéticos alimentado por IA que aprende de los patrones estadísticos del conjunto de datos original. Luego, la IA genera personajes ficticios que se ajustan a los patrones aprendidos.
Con Mostly AI, puede generar bases de datos completas con integridad referencial. Puede sintetizar todo tipo de datos para ayudarlo a construir mejores modelos de IA.
Sintetizado.io

Synthesized.io es utilizado por empresas líderes para sus iniciativas de IA. Para usar sintetizar.io, especifica los requisitos de datos en un archivo de configuración YAML.
A continuación, crea un trabajo y lo ejecuta como parte de una canalización de datos. También tiene un nivel gratuito muy generoso que le permite experimentar y ver si se ajusta a sus necesidades de datos.
YData

Con YData, puede generar datos tabulares, de series temporales, transaccionales, de tablas múltiples y relacionales. Esto le permite esquivar los problemas asociados con la recopilación, el intercambio y la calidad de los datos.
Viene con una IA y SDK para usar para interactuar con su plataforma. Además, tienen un generoso nivel gratuito que puede usar para hacer una demostración del producto.
Gretel IA

Gretel AI ofrece API para generar cantidades ilimitadas de datos sintéticos. Gretel tiene un generador de datos de código abierto que puedes instalar y usar.
Alternativamente, puede usar su API REST o CLI, que tendrá un costo. Sin embargo, su precio es razonable y escala con el tamaño del negocio.
Cópulas
Copulas es una biblioteca Python de código abierto para modelar distribuciones multivariadas utilizando funciones de cópula y generando datos sintéticos que siguen las mismas propiedades estadísticas.
El proyecto comenzó en 2018 en el MIT como parte del Proyecto de Bóveda de Datos Sintéticos.
CTGAN
CTGAN consta de generadores que pueden aprender de datos reales de una sola tabla y generar datos sintéticos a partir de los patrones identificados.
Se implementa como una biblioteca Python de código abierto. CTGAN, junto con Copulas, es parte del Proyecto de Bóveda de Datos Sintéticos.
DoppelGANger
DoppelGANger es una implementación de código abierto de Generative Adversarial Networks para generar datos sintéticos.
DoppelGANger es útil para generar datos de series temporales y lo utilizan empresas como Gretel AI. La biblioteca de Python está disponible de forma gratuita y es de código abierto.
sintetizador

Synth es un generador de datos de código abierto que lo ayuda a crear datos realistas según sus especificaciones, ocultar información de identificación personal y desarrollar datos de prueba para sus aplicaciones.
Puede usar Synth para generar series en tiempo real y datos relacionales para sus necesidades de aprendizaje automático. Synth también es independiente de la base de datos, por lo que puede usarlo con sus bases de datos SQL y NoSQL.
SDV.dev
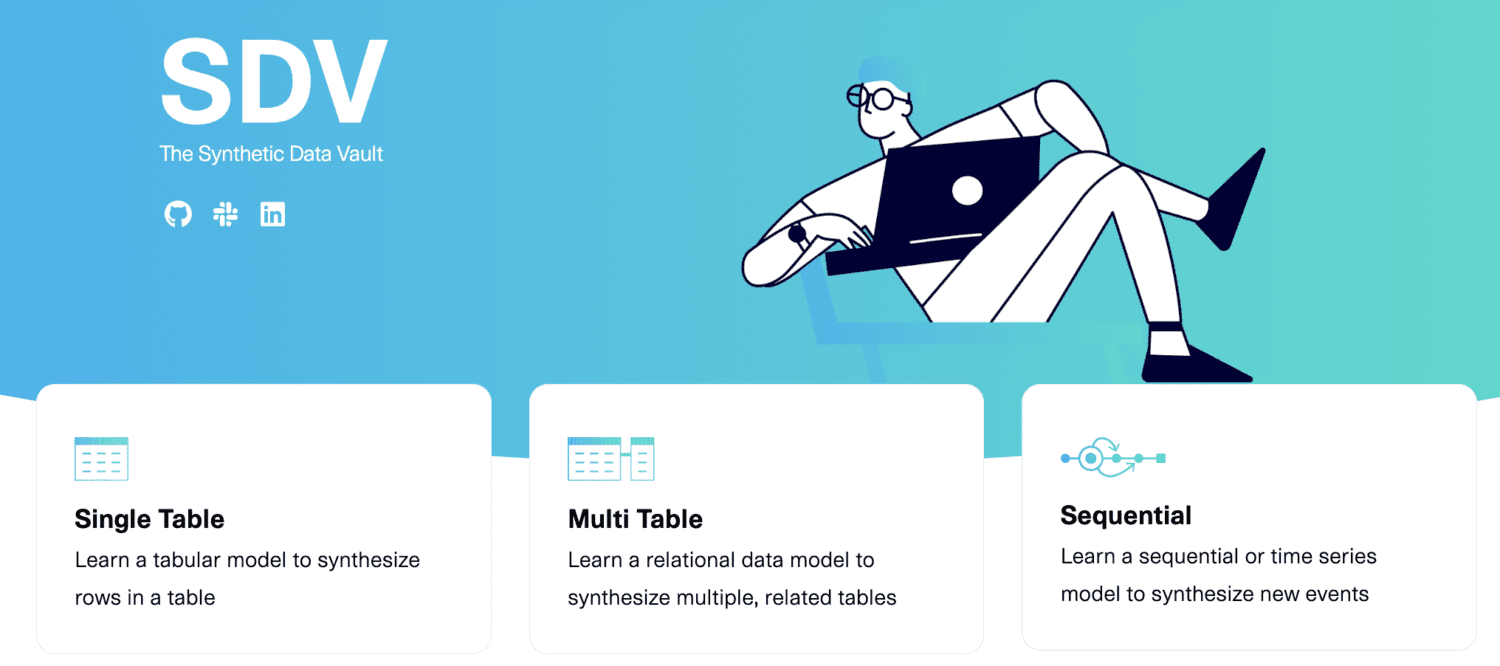
SDV significa Bóveda de datos sintéticos. SDV.dev es un proyecto de software que comenzó en el MIT en 2016 y ha creado diferentes herramientas para generar datos sintéticos.
Estas herramientas incluyen Copulas, CTGAN, DeepEcho y RDT. Estas herramientas se implementan como bibliotecas Python de código abierto que puede usar fácilmente.
tofu
Tofu es una biblioteca Python de código abierto para generar datos sintéticos basados en datos de biobancos del Reino Unido. A diferencia de las herramientas mencionadas anteriormente que lo ayudarán a generar cualquier tipo de datos en función de su conjunto de datos existente, Tofu genera datos que se asemejan únicamente a los del biobanco.
El UK Biobank es un estudio sobre las características fenotípicas y genotípicas de 500 000 adultos de mediana edad del Reino Unido.
Twinificar
Twinify es un paquete de software que se utiliza como biblioteca o herramienta de línea de comandos para combinar datos confidenciales mediante la producción de datos sintéticos con distribuciones estadísticas idénticas.

Para usar Twinify, proporciona los datos reales como un archivo CSV y aprende de los datos para producir un modelo que se puede usar para generar datos sintéticos. Es de uso completamente gratuito.
Datos dinámicos
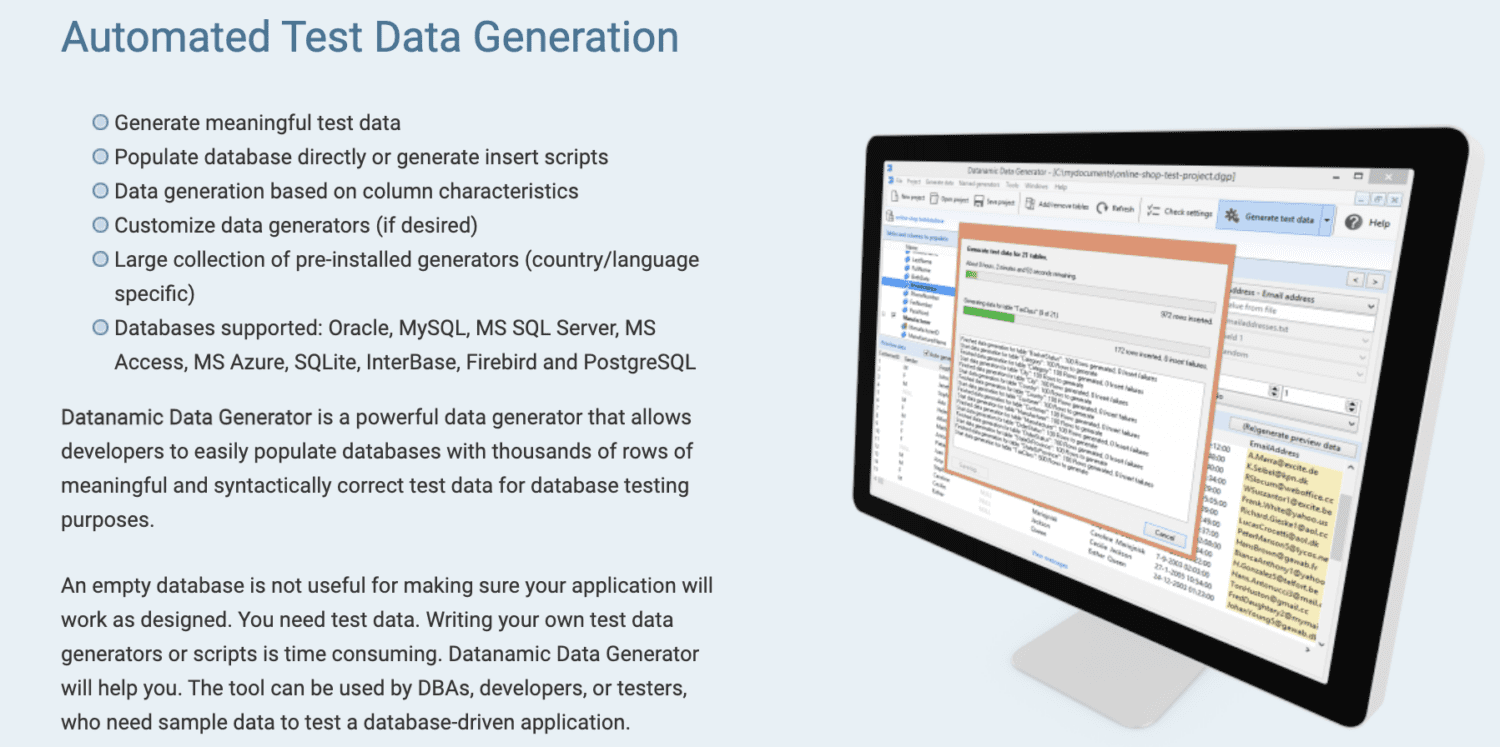
Datanamic lo ayuda a crear datos de prueba para aplicaciones de aprendizaje automático y basadas en datos. Genera datos basados en características de columna como correo electrónico, nombre y número de teléfono.
Los generadores de datos de Datanamic son personalizables y admiten la mayoría de las bases de datos, como Oracle, MySQL, MySQL Server, MS Access y Postgres. Soporta y asegura la integridad referencial en los datos generados.
Beneficiador
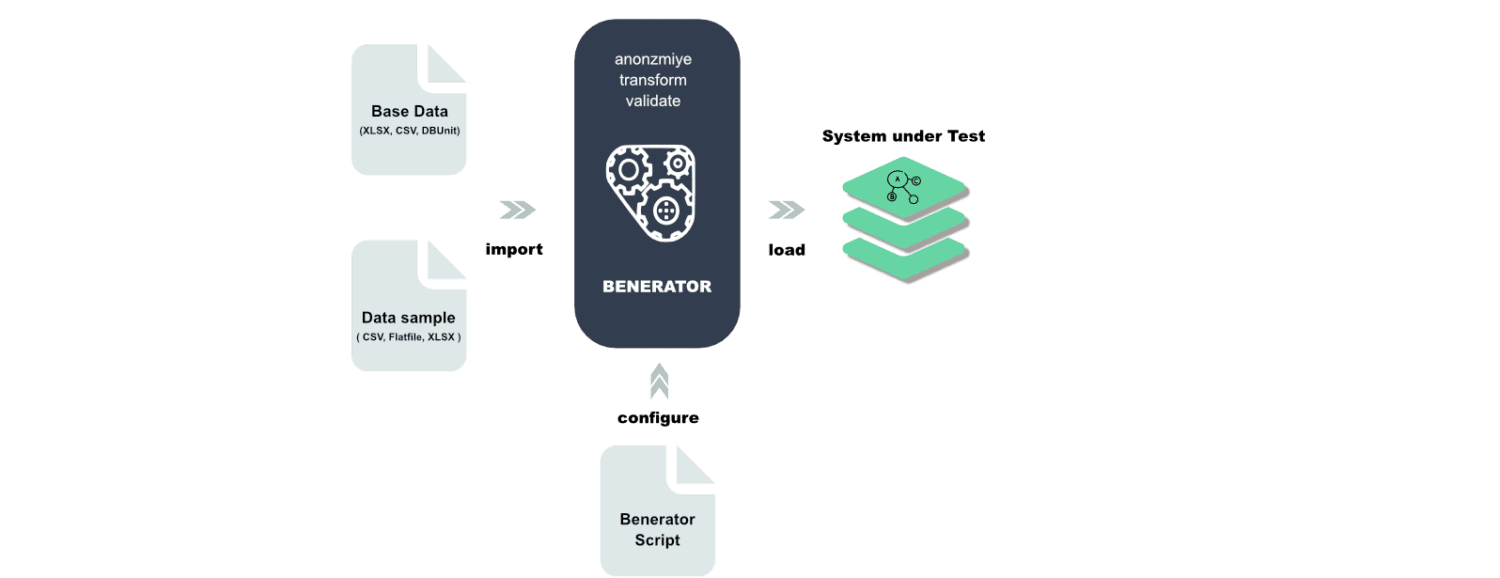
Benerator es un software para ofuscación, generación y migración de datos con fines de prueba y capacitación. Con Benerator, describe los datos mediante XML (Lenguaje de marcado extensible) y los genera con la herramienta de línea de comandos.
Está diseñado para que lo puedan usar personas que no son desarrolladores y, con él, puede generar miles de millones de filas de datos. Benerator es gratuito y de código abierto.
Ultimas palabras
Gartner estima que para 2030, se utilizarán más datos sintéticos para el aprendizaje automático que datos reales.
No es difícil ver por qué dado el costo y las preocupaciones de privacidad de usar datos reales. Por lo tanto, es necesario que las empresas conozcan los datos sintéticos y las diferentes herramientas que les ayuden a generarlos.
A continuación, consulte las herramientas de supervisión sintéticas para su negocio en línea.