
La ciencia de datos es para cualquier persona a la que le guste desentrañar cosas enredadas y descubrir maravillas ocultas en un desorden aparente.
Es como buscar agujas en un pajar; solo que los científicos de datos no necesitan ensuciarse las manos en absoluto. Usando herramientas sofisticadas con gráficos coloridos y mirando montones de números, simplemente se sumergen en montones de datos y encuentran agujas valiosas en forma de ideas de alto valor comercial.
un tipico científico de datos La caja de herramientas debe incluir al menos un elemento de cada una de estas categorías: bases de datos relacionales, bases de datos NoSQL, marcos de big data, herramientas de visualización, herramientas de extracción, lenguajes de programación, IDE y herramientas de aprendizaje profundo.
Tabla de contenido
Bases de datos relacionales
Una base de datos relacional es una colección de datos estructurados en tablas con atributos. Las tablas se pueden vincular entre sí, definiendo relaciones y restricciones, y creando lo que se denomina un modelo de datos. Para trabajar con bases de datos relacionales, normalmente se utiliza un lenguaje llamado SQL (lenguaje de consulta estructurado).
Las aplicaciones que gestionan la estructura y los datos de las bases de datos relacionales se denominan RDBMS (Relational DataBase Management Systems). Hay muchas aplicaciones de este tipo, y las más relevantes recientemente han comenzado a enfocarse en el campo de la ciencia de datos, agregando funcionalidad para trabajar con repositorios de big data y para aplicar técnicas como el análisis de datos y el aprendizaje automático.
servidor SQL
SGBDR de Microsoft, ha estado evolucionando durante más de 20 años mediante la expansión constante de su funcionalidad empresarial. Desde su versión 2016, SQL Server ofrece una cartera de servicios que incluyen soporte para código R incrustado. SQL Server 2017 aumenta la apuesta al cambiar el nombre de R Services a Machine Language Services y agregar soporte para el lenguaje Python (más información sobre estos dos lenguajes a continuación).
Con estas importantes adiciones, SQL Server apunta a los científicos de datos que pueden no tener experiencia con Transact SQL, el lenguaje de consulta nativo de Microsoft SQL Server.
SQL Server está lejos de ser un producto gratuito. Puede comprar licencias para instalarlo en un Windows Server (el precio variará según la cantidad de usuarios concurrentes) o usarlo como un servicio de pago, a través de la nube de Microsoft Azure. Aprender Microsoft SQL Server es fácil.
mysql
En el lado del software de código abierto, mysql tiene la corona de popularidad de los RDBMS. Aunque Oracle actualmente lo posee, sigue siendo gratuito y de código abierto según los términos de una Licencia Pública General GNU. La mayoría de las aplicaciones basadas en web utilizan MySQL como depósito de datos subyacente, gracias a su conformidad con el estándar SQL.
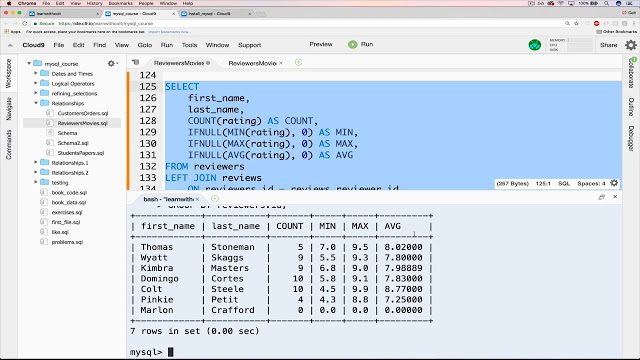
También ayudan a su popularidad sus sencillos procedimientos de instalación, su gran comunidad de desarrolladores, toneladas de documentación completa y herramientas de terceros, como phpMyAdmin, que simplifican las actividades de administración diarias. Aunque MySQL no tiene funciones nativas para realizar análisis de datos, su apertura permite su integración con casi cualquier herramienta de visualización, informes e inteligencia comercial que pueda elegir.
postgresql
Otra opción de RDBMS de código abierto es Pos.tgreSQL. Si bien no es tan popular como MySQL, PostgreSQL se destaca por su flexibilidad y extensibilidad, y su soporte para consultas complejas, las que van más allá de las declaraciones básicas como SELECT, WHERE y GROUP BY.
Estas características le permiten ganar popularidad entre los científicos de datos. Otra característica interesante es el soporte para múltiples entornos, lo que permite su uso en entornos en la nube y en las instalaciones, o en una combinación de ambos, comúnmente conocidos como entornos de nube híbrida.
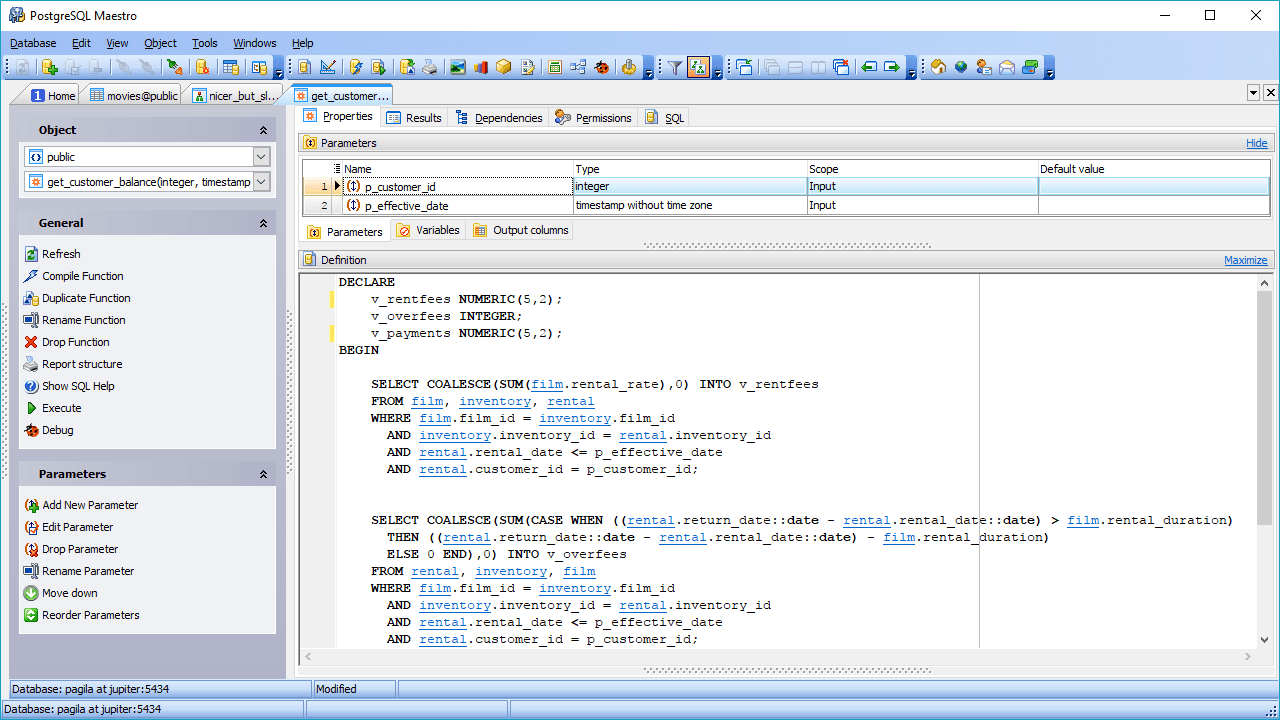
PostgreSQL es capaz de combinar el procesamiento analítico en línea (OLAP) con el procesamiento de transacciones en línea (OLTP), trabajando en un modo llamado procesamiento transaccional/analítico híbrido (HTAP). También es muy adecuado para trabajar con big data, gracias a la adición de PostGIS para datos geográficos y JSON-B para documentos. PostgreSQL también admite datos no estructurados, lo que le permite estar en ambas categorías: bases de datos SQL y NoSQL.
Bases de datos NoSQL
También conocidas como bases de datos no relacionales, este tipo de repositorio de datos proporciona un acceso más rápido a estructuras de datos no tabulares. Algunos ejemplos de estas estructuras son gráficos, documentos, columnas anchas, valores clave, entre muchos otros. Los almacenes de datos NoSQL pueden dejar de lado la coherencia de los datos en favor de otros beneficios, como la disponibilidad, la partición y la velocidad de acceso.
Dado que no hay SQL en los almacenes de datos NoSQL, la única forma de consultar este tipo de base de datos es mediante el uso de lenguajes de bajo nivel, y no existe un lenguaje tan ampliamente aceptado como SQL. Además, no existen especificaciones estándar para NoSQL. Es por eso que, irónicamente, algunas bases de datos NoSQL están comenzando a agregar soporte para scripts SQL.
MongoDB
MongoDB es un popular sistema de base de datos NoSQL, que almacena datos en forma de documentos JSON. Su enfoque está en la escalabilidad y la flexibilidad para almacenar datos de forma no estructurada. Esto significa que no existe una lista de campos fijos que deban observarse en todos los elementos almacenados. Además, la estructura de datos puede cambiar con el tiempo, algo que en una base de datos relacional implica un alto riesgo de afectar las aplicaciones en ejecución.

La tecnología de MongoDB permite la indexación, las consultas ad hoc y la agregación que proporcionan una base sólida para el análisis de datos. La naturaleza distribuida de la base de datos proporciona alta disponibilidad, escalabilidad y distribución geográfica sin necesidad de herramientas sofisticadas.
redis
Este one es otra opción en el frente NoSQL de código abierto. Básicamente es un almacén de estructuras de datos que opera en memoria y, además de brindar servicios de base de datos, también funciona como memoria caché y intermediario de mensajes.

Admite una gran variedad de estructuras de datos no convencionales, incluidos hashes, índices geoespaciales, listas y conjuntos ordenados. Es muy adecuado para la ciencia de datos gracias a su alto rendimiento en tareas de uso intensivo de datos, como el cálculo de intersecciones de conjuntos, la clasificación de listas largas o la generación de clasificaciones complejas. La razón del desempeño sobresaliente de Redis es su operación en memoria. Se puede configurar para persistir los datos de forma selectiva.
Marcos de Big Data
Supongamos que tienes que analizar los datos que generan los usuarios de Facebook durante un mes. Estamos hablando de fotos, videos, mensajes, todo eso. Teniendo en cuenta que cada día se añaden más de 500 terabytes de datos a la red social por parte de sus usuarios, es difícil medir el volumen que representa un mes completo de sus datos.
Para manipular esa gran cantidad de datos de manera efectiva, necesita un marco adecuado capaz de calcular estadísticas en una arquitectura distribuida. Hay dos de los marcos que lideran el mercado: Hadoop y Spark.
Hadoop
Como un gran marco de datos, Hadoop se ocupa de las complejidades asociadas con la recuperación, el procesamiento y el almacenamiento de grandes cantidades de datos. Hadoop opera en un entorno distribuido, compuesto por grupos de computadoras que procesan algoritmos simples. Hay un algoritmo de orquestación, llamado MapReduce, que divide las tareas grandes en partes pequeñas y luego distribuye esas tareas pequeñas entre los clústeres disponibles.

Hadoop se recomienda para repositorios de datos de clase empresarial que requieren acceso rápido y alta disponibilidad, todo eso en un esquema de bajo costo. Pero necesita un administrador de Linux con profundo Conocimiento de Hadoop para mantener el marco en funcionamiento.
Chispa – chispear
Hadoop no es el único marco disponible para la manipulación de grandes datos. Otro gran nombre en esta área es Chispa – chispear. El motor Spark fue diseñado para superar a Hadoop en términos de velocidad de análisis y facilidad de uso. Aparentemente, logró este objetivo: algunas comparaciones dicen que Spark se ejecuta hasta 10 veces más rápido que Hadoop cuando trabaja en un disco y 100 veces más rápido operando en memoria. También requiere un número menor de máquinas para procesar la misma cantidad de datos.

Además de la velocidad, otro beneficio de Spark es su compatibilidad con el procesamiento de secuencias. Este tipo de procesamiento de datos, también llamado procesamiento en tiempo real, implica la entrada y salida continua de datos.
Herramientas de visualización
Un chiste común entre los científicos de datos dice que, si torturas los datos el tiempo suficiente, te confesarán lo que necesitas saber. En este caso, “torturar” significa manipular los datos transformándolos y filtrándolos, para poder visualizarlos mejor. Y ahí es donde las herramientas de visualización de datos entran en escena. Estas herramientas toman datos preprocesados de múltiples fuentes y muestran sus verdades reveladas en formas gráficas y comprensibles.
Hay cientos de herramientas que entran en esta categoría. Nos guste o no, el más utilizado es Microsoft Excel y sus herramientas de gráficos. Los gráficos de Excel son accesibles para cualquiera que use Excel, pero tienen una funcionalidad limitada. Lo mismo se aplica a otras aplicaciones de hojas de cálculo, como Google Sheets y Libre Office. Pero aquí estamos hablando de herramientas más específicas, especialmente diseñadas para inteligencia comercial (BI) y análisis de datos.
BI de energía
No hace mucho, Microsoft lanzó su BI de energía aplicación de visualización. Puede tomar datos de diversas fuentes, como archivos de texto, bases de datos, hojas de cálculo y muchos servicios de datos en línea, incluidos Facebook y Twitter, y usarlos para generar paneles repletos de gráficos, tablas, mapas y muchos otros objetos de visualización. Los objetos del tablero son interactivos, lo que significa que puede hacer clic en una serie de datos en un gráfico para seleccionarla y usarla como filtro para los otros objetos en el tablero.
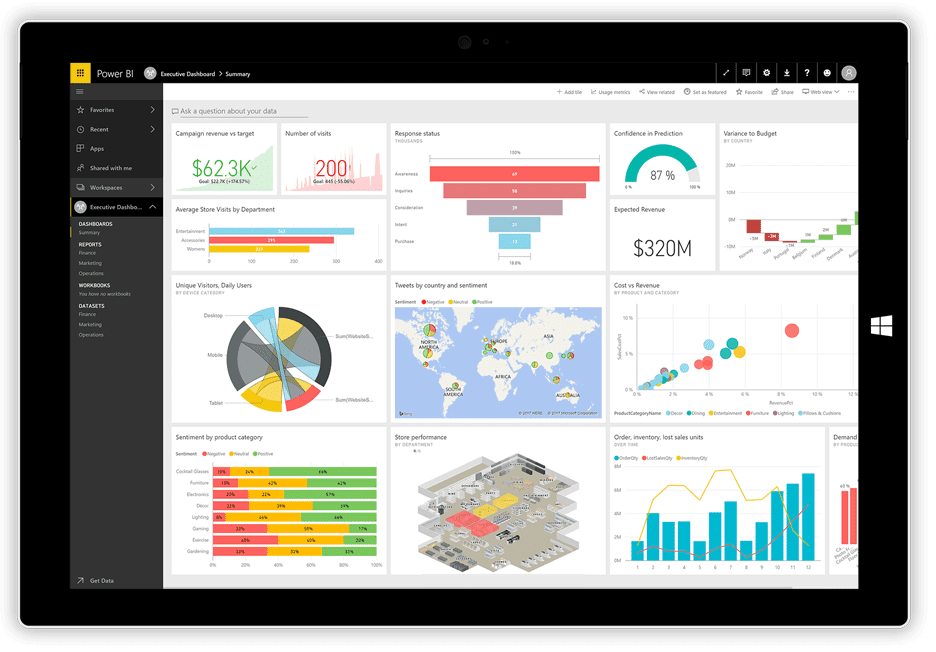
Power BI es una combinación de una aplicación de escritorio de Windows (parte del paquete Office 365), una aplicación web y un servicio en línea para publicar los paneles en la web y compartirlos con sus usuarios. El servicio le permite crear y administrar permisos para otorgar acceso a los tableros solo a ciertas personas.
Cuadro
Cuadro es otra opción para crear tableros interactivos a partir de una combinación de múltiples fuentes de datos. También ofrece una versión de escritorio, una versión web y un servicio en línea para compartir los paneles que cree. Funciona naturalmente «con la forma en que piensas» (como afirma), y es fácil de usar para personas sin conocimientos técnicos, lo que se mejora a través de muchos tutoriales y videos en línea.
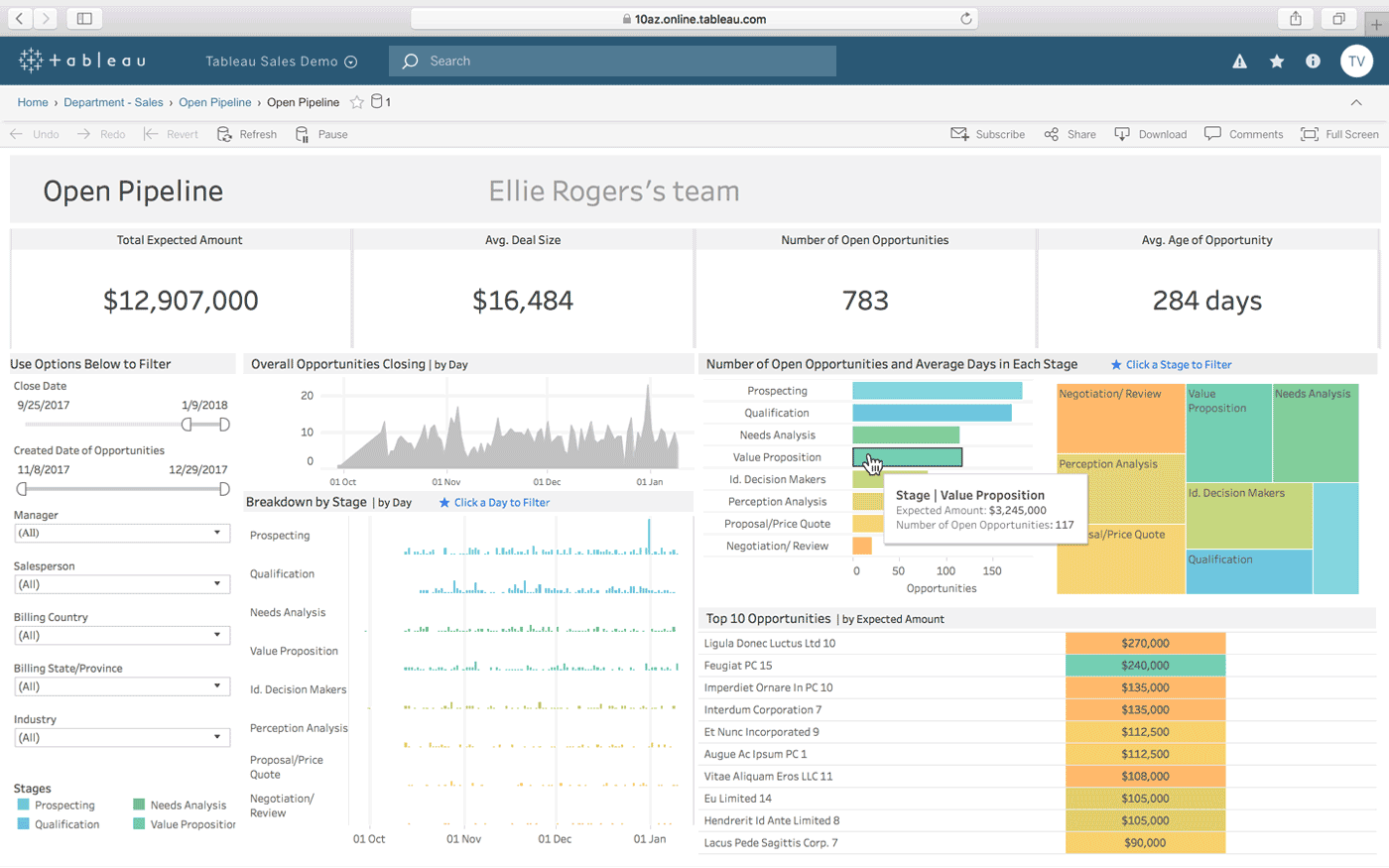
Algunas de las características más destacadas de Tableau son sus conectores de datos ilimitados, sus datos en vivo y en memoria, y sus diseños optimizados para dispositivos móviles.
QlikView
QlikView ofrece una interfaz de usuario limpia y sencilla para ayudar a los analistas a descubrir nuevos conocimientos a partir de los datos existentes a través de elementos visuales que son fácilmente comprensibles para todos.
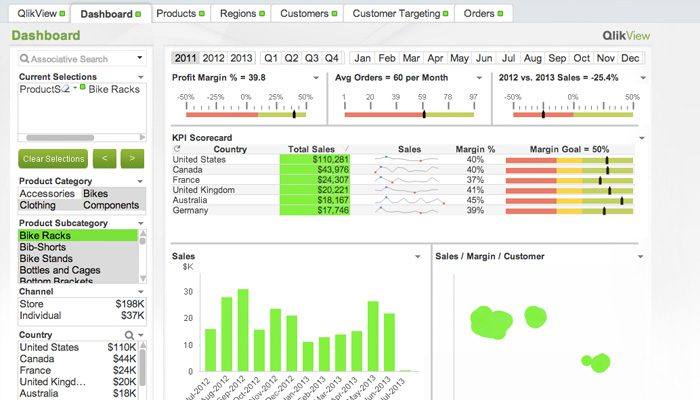
Esta herramienta es conocida por ser una de las plataformas de inteligencia empresarial más flexibles. Proporciona una función llamada Búsqueda asociativa, que lo ayuda a concentrarse en los datos más importantes, ahorrándole el tiempo que le llevaría encontrarlos por su cuenta.
Con QlikView, puede colaborar con socios en tiempo real, realizando análisis comparativos. Todos los datos pertinentes se pueden combinar en una aplicación, con características de seguridad que restringen el acceso a los datos.
herramientas de raspado
En los tiempos en que Internet recién estaba surgiendo, los rastreadores web comenzaron a viajar junto con las redes recopilando información en su camino. A medida que la tecnología evolucionó, el término web crawling cambió por web scraping, pero aún significa lo mismo: extraer información automáticamente de los sitios web. Para hacer web scraping, utiliza procesos automatizados, o bots, que saltan de una página web a otra, extrayendo datos de ellos y exportándolos a diferentes formatos o insertándolos en bases de datos para su posterior análisis.
A continuación, resumimos las características de tres de los web scrapers más populares disponibles en la actualidad.
Octoparse
Octoparse web scraper ofrece algunas características interesantes, incluidas herramientas integradas para obtener información de sitios web que no facilitan que los bots de scraping hagan su trabajo. Es una aplicación de escritorio que no requiere codificación, con una interfaz de usuario fácil de usar que permite visualizar el proceso de extracción a través de un diseñador de flujo de trabajo gráfico.
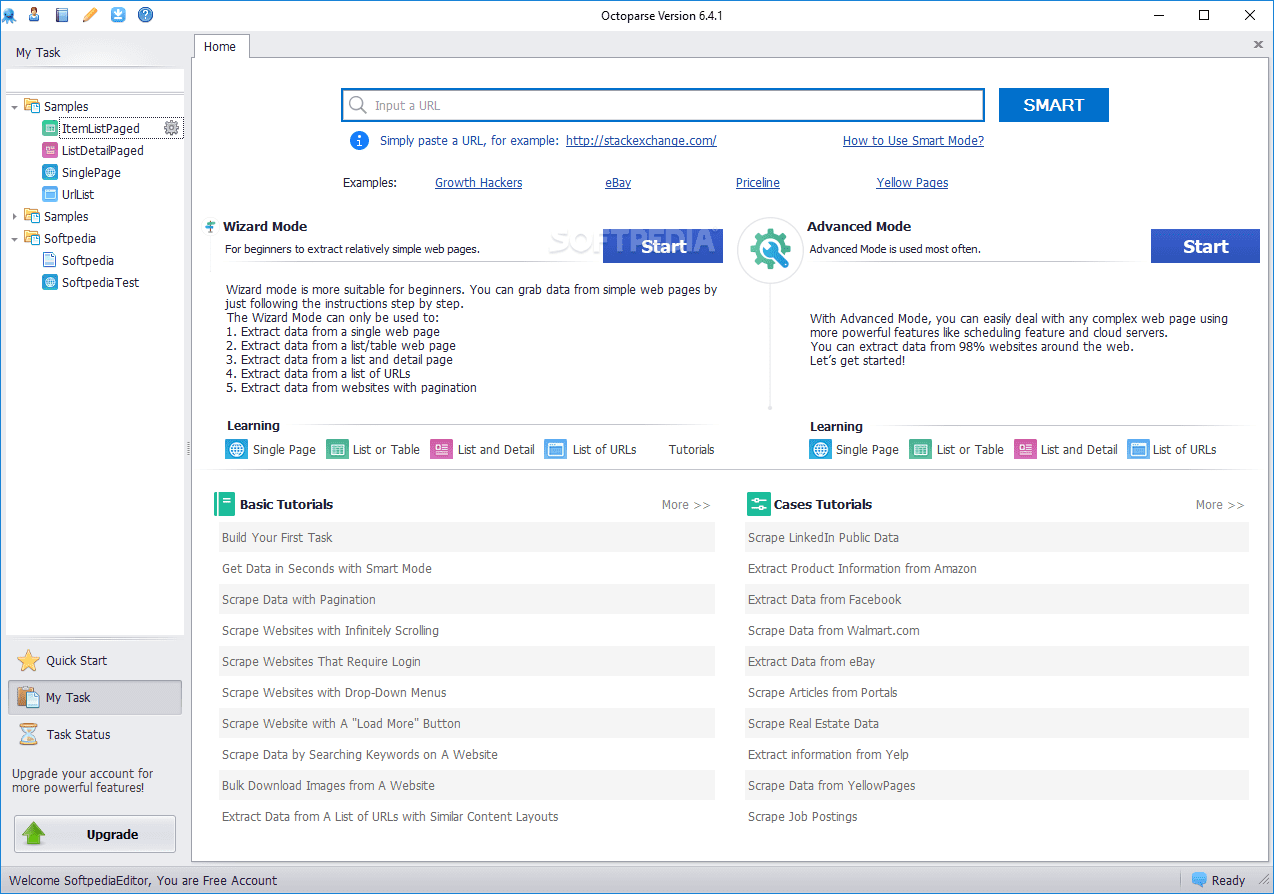
Junto con la aplicación independiente, Octoparse ofrece un servicio basado en la nube para acelerar el proceso de extracción de datos. Los usuarios pueden experimentar una ganancia de velocidad de 4x a 10x cuando usan el servicio en la nube en lugar de la aplicación de escritorio. Si te quedas con la versión de escritorio, puedes usar Octoparse gratis. Pero si prefiere utilizar el servicio en la nube, deberá elegir uno de sus planes pagos.
Capturador de contenido
Si está buscando una herramienta de raspado rica en funciones, debe echar un ojo a Capturador de contenido. A diferencia de Octoparse, para utilizar Content Grabber es necesario tener conocimientos avanzados de programación. A cambio, obtiene edición de secuencias de comandos, interfaces de depuración y otras funcionalidades avanzadas. Con Content Grabber, puede usar lenguajes .Net para escribir expresiones regulares. De esta manera, no tiene que generar las expresiones usando una herramienta integrada.
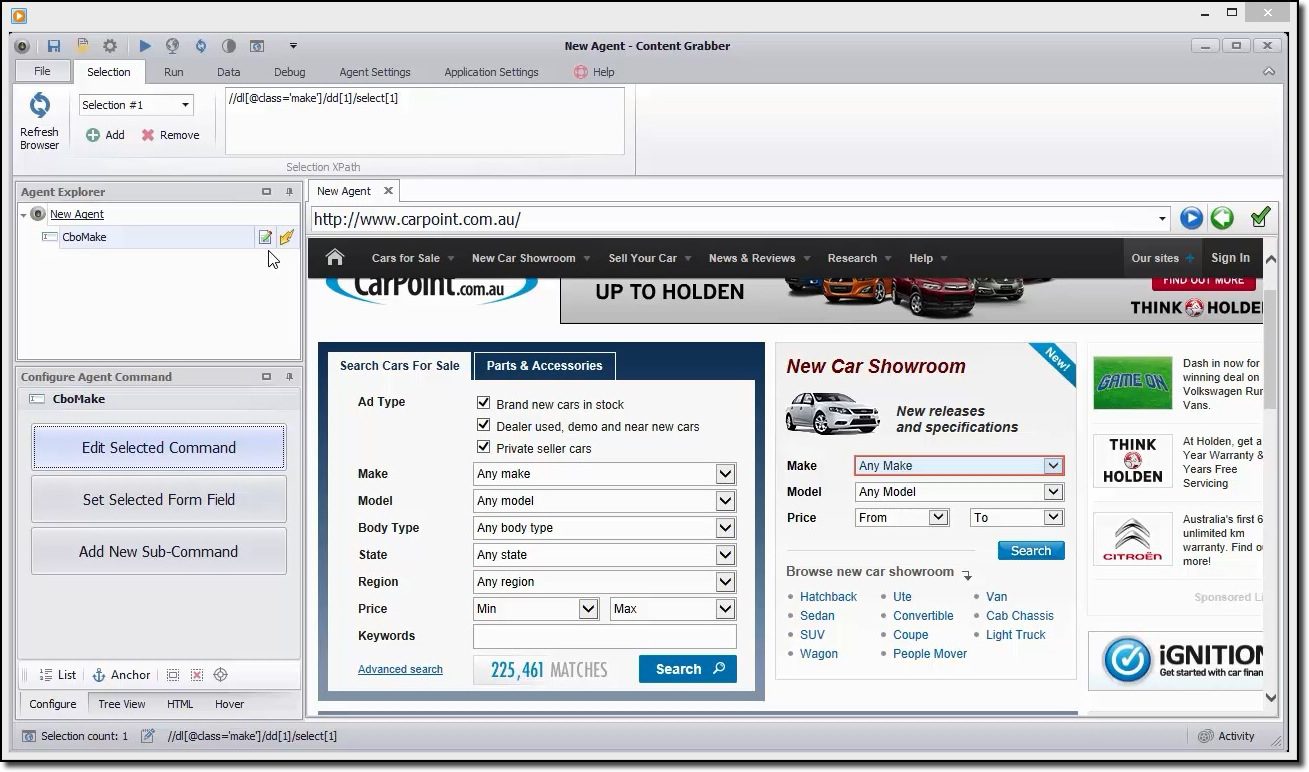
La herramienta ofrece una API (interfaz de programación de aplicaciones) que puede usar para agregar capacidades de extracción a sus aplicaciones web y de escritorio. Para utilizar esta API, los desarrolladores deben obtener acceso al servicio de Windows Content Grabber.
ParseHub
este raspador puede manejar una extensa lista de diferentes tipos de contenido, incluidos foros, comentarios anidados, calendarios y mapas. También puede manejar páginas que contienen autenticación, Javascript, Ajax y más. ParseHub se puede usar como una aplicación web o una aplicación de escritorio capaz de ejecutarse en Windows, macOS X y Linux.
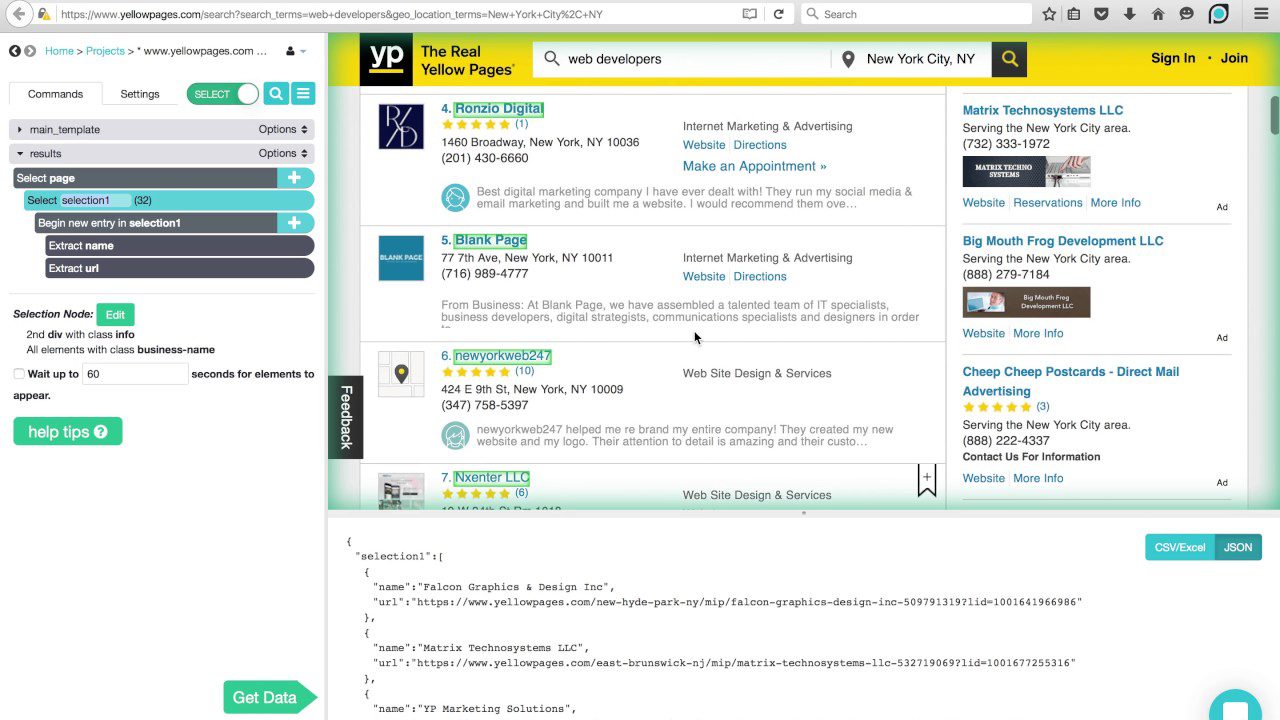
Al igual que Content Grabber, se recomienda tener algunos conocimientos de programación para aprovechar al máximo ParseHub. Tiene una versión gratuita, limitada a 5 proyectos y 200 páginas por tirada.
Lenguajes de programación
Así como el lenguaje SQL mencionado anteriormente está diseñado específicamente para trabajar con bases de datos relacionales, existen otros lenguajes creados con un claro enfoque en la ciencia de datos. Estos lenguajes permiten a los desarrolladores escribir programas que se ocupan del análisis masivo de datos, como estadísticas y aprendizaje automático.
SQL también se considera una habilidad importante que los desarrolladores deberían tener para hacer ciencia de datos, pero eso se debe a que la mayoría de las organizaciones todavía tienen una gran cantidad de datos en bases de datos relacionales. Los lenguajes de ciencia de datos «verdaderos» son R y Python.
Pitón

Pitón es un lenguaje de programación de propósito general, interpretado y de alto nivel, muy adecuado para el desarrollo rápido de aplicaciones. Tiene una sintaxis simple y fácil de aprender que permite una curva de aprendizaje empinada y reducciones en los costos de mantenimiento del programa. Hay muchas razones por las que es el lenguaje preferido para la ciencia de datos. Por mencionar algunos: potencial de secuencias de comandos, verbosidad, portabilidad y rendimiento.
Este lenguaje es un buen punto de partida para los científicos de datos que planean experimentar mucho antes de lanzarse al trabajo de procesamiento de datos reales y duros, y que desean desarrollar aplicaciones completas.
R
los lenguaje R se utiliza principalmente para el procesamiento de datos estadísticos y gráficos. Aunque no está destinado a desarrollar aplicaciones completas, como sería el caso de Python, R se ha vuelto muy popular en los últimos años debido a su potencial para la minería y el análisis de datos.

Gracias a una biblioteca cada vez mayor de paquetes disponibles gratuitamente que amplían su funcionalidad, R es capaz de realizar todo tipo de trabajo de procesamiento de datos, incluido el modelado lineal/no lineal, la clasificación, las pruebas estadísticas, etc.
No es un lenguaje fácil de aprender, pero una vez que te familiarices con su filosofía, estarás haciendo cálculos estadísticos como un profesional.
IDE
Si está considerando seriamente dedicarse a la ciencia de datos, deberá elegir cuidadosamente un entorno de desarrollo integrado (IDE) que se adapte a sus necesidades, ya que usted y su IDE pasarán mucho tiempo trabajando juntos.
Un IDE ideal debería reunir todas las herramientas que necesita en su trabajo diario como codificador: un editor de texto con resaltado de sintaxis y finalización automática, un depurador potente, un navegador de objetos y fácil acceso a herramientas externas. Además, debe ser compatible con el idioma de tu preferencia, por lo que es una buena idea elegir tu IDE después de saber qué idioma usarás.
espía
Este El IDE genérico está destinado principalmente a científicos y analistas que también necesitan codificar. Para que se sientan cómodos, no se limita a la funcionalidad IDE, sino que también proporciona herramientas para la exploración/visualización de datos y la ejecución interactiva, como se podría encontrar en un paquete científico. El editor de Spyder admite varios idiomas y agrega un navegador de clase, división de ventanas, salto a definición, finalización automática de código e incluso una herramienta de análisis de código.
El depurador lo ayuda a rastrear cada línea de código de forma interactiva, y un generador de perfiles lo ayuda a encontrar y eliminar las ineficiencias.
PyCharm
Si programa en Python, lo más probable es que su IDE de elección sea PyCharm. Tiene un editor de código inteligente con búsqueda inteligente, finalización de código y detección y corrección de errores. Con solo un clic, puede pasar del editor de código a cualquier ventana relacionada con el contexto, incluida la prueba, el supermétodo, la implementación, la declaración y más. PyCharm admite Anaconda y muchos paquetes científicos, como NumPy y Matplotlib, por nombrar solo dos de ellos.
Ofrece integración con los sistemas de control de versiones más importantes, y también con un corredor de pruebas, un perfilador y un depurador. Para cerrar el trato, también se integra con Docker y Vagrant para brindar desarrollo y contenedorización multiplataforma.
RStudio
Para aquellos científicos de datos que prefieren el equipo R, el IDE de elección debe ser RStudio, debido a sus muchas características. Puede instalarlo en una computadora de escritorio con Windows, macOS o Linux, o puede ejecutarlo desde un navegador web si no desea instalarlo localmente. Ambas versiones ofrecen ventajas como resaltado de sintaxis, sangría inteligente y finalización de código. Hay un visor de datos integrado que resulta útil cuando necesita buscar datos tabulares.
El modo de depuración permite ver cómo se van actualizando los datos de forma dinámica al ejecutar un programa o script paso a paso. Para el control de versiones, RStudio integra soporte para SVN y Git. Una buena ventaja es la posibilidad de crear gráficos interactivos, con Shiny y ofrece bibliotecas.
Tu caja de herramientas personal
En este punto, debe tener una visión completa de las herramientas que debe conocer para sobresalir en la ciencia de datos. Además, esperamos haberte dado suficiente información para decidir cuál es la opción más conveniente dentro de cada categoría de herramientas. Ahora depende de ti. La ciencia de datos es un campo floreciente donde desarrollar una carrera. Pero si quieres hacerlo, debes mantenerte al día con los cambios de tendencias y tecnologías, ya que ocurren casi a diario.