Construir un sistema de software automatizado significó configurar varios servidores con configuración de CPU, memoria, almacenamiento y otros recursos dedicados durante muchos años. A continuación, se formó un equipo de administradores para gestionar estos sistemas. Luego, el equipo de desarrollo se hizo cargo de la infraestructura y comenzó a crear procesos que conectan los servidores.
Este proceso puede ser complicado porque involucra a muchos grupos diferentes que trabajan juntos hacia un objetivo común. Estos conflictos de interés pueden entonces ser un problema.
También puede ser bastante costoso. Esto requiere que tenga administradores en su nómina. Los servidores, que funcionan de forma continua, consumen recursos a pesar de no ser utilizados.
Para mantener el mejor rendimiento a lo largo del tiempo, necesita una solución de escalado automático que escale automáticamente los recursos del servidor.
La plataforma en la nube tiene una ventaja: le permite crear una arquitectura de extremo a extremo sin necesidad de configurar un clúster de servidores. Desde una perspectiva de administración, no hay nada que mantener.
Esta es una opción rentable para las nuevas empresas y las fases de proyectos de producto mínimo viable (MVP). Es un buen punto de partida si es difícil predecir las futuras cargas de producción y la actividad de los usuarios. Aquí es donde puede ser un desafío determinar la configuración de los servidores de clúster.
La automatización de procesos a través de servicios en la nube sin servidor es lo que hace que la arquitectura sin servidor se destaque. Conecta servicios y produce resultados similares a los servidores de clúster tradicionales.
Este es un ejemplo de creación de una arquitectura de este tipo utilizando solo servicios nativos de AWS.
Tabla de contenido
Recogiendo el flujo sin servidor de servicios
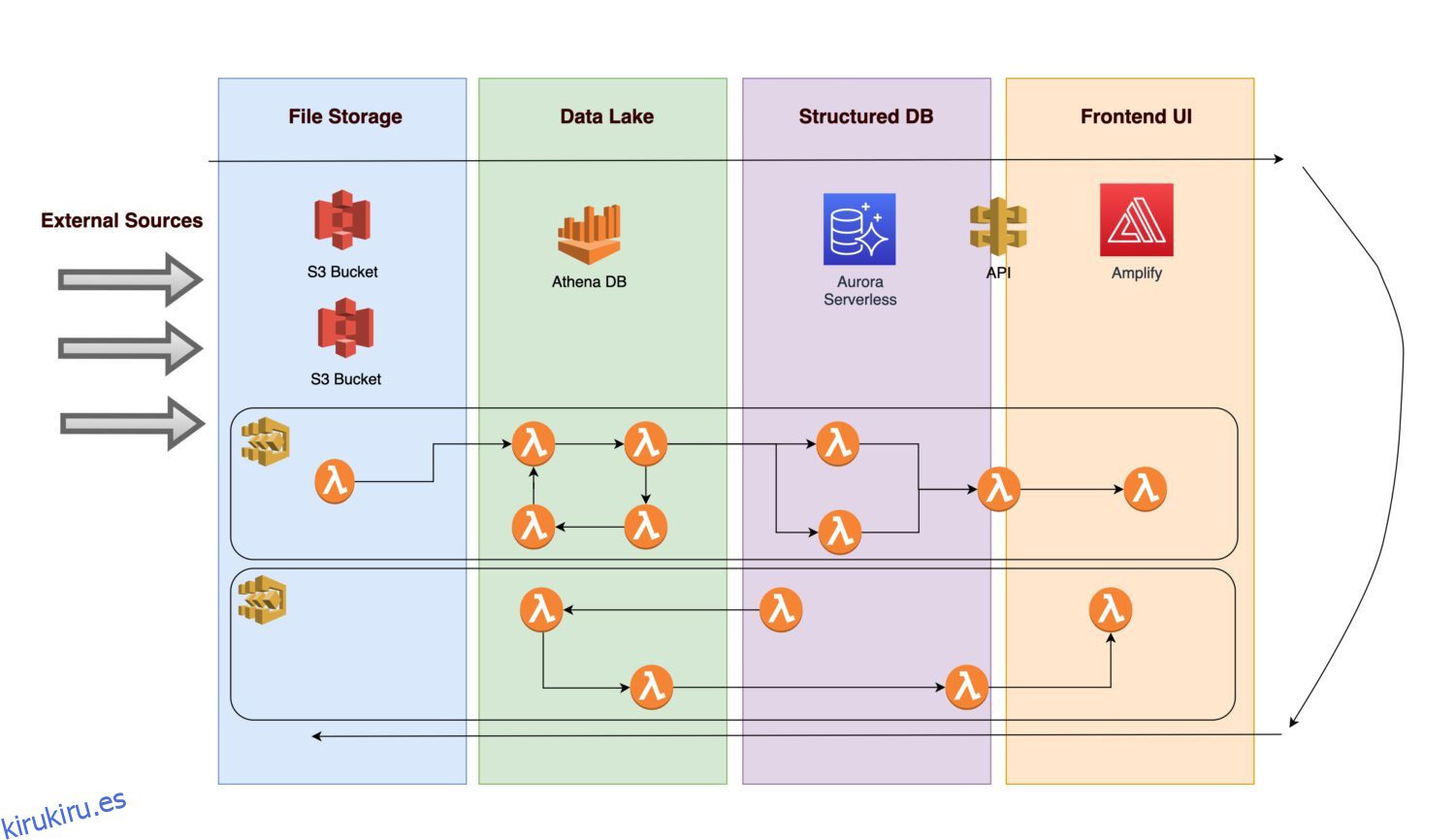
Imagine que le gustaría crear una plataforma para recopilar varios datos e imágenes (o fotos) de la infraestructura de algunos activos concretos (puede ser cualquier activo de fabricación o de servicios públicos).
- Para hacer posible el análisis futuro, es necesario que los datos entrantes se ingieran primero.
- Después de aplicar las reglas comerciales, un procedimiento de back-end guarda los resultados calculados como información normalizada en una base de datos relacional.
- Una interfaz de aplicación que muestra datos limpios normalizados permite a los usuarios ver los resultados.
Examinemos qué componentes podría incluir la arquitectura.
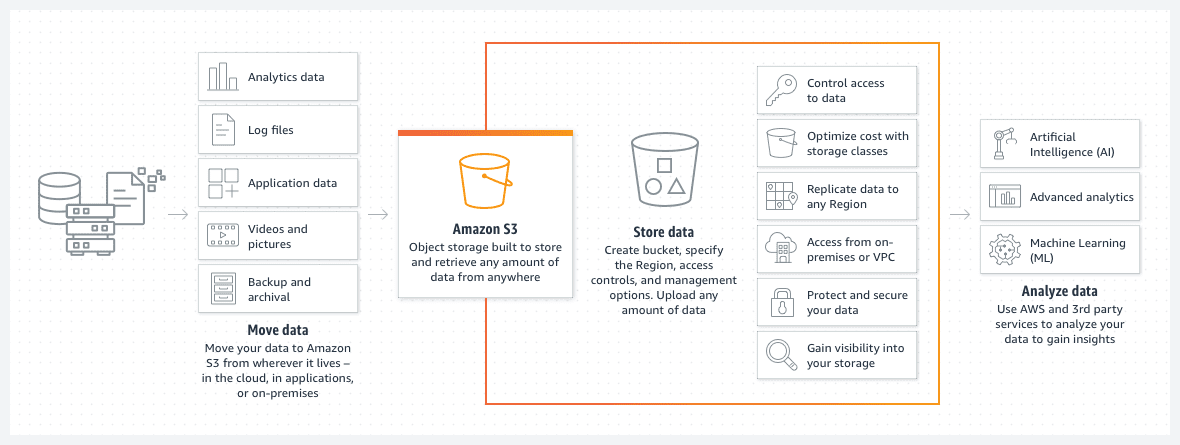
Cubos de AWS S3
 Fuente: aws.amazon.com
Fuente: aws.amazon.com
Los depósitos de Amazon S3 son una excelente manera de almacenar archivos o imágenes en la nube de AWS. El precio del almacenamiento en el cubo S3 es notablemente bajo. Además, la introducción de una política de ciclo de vida del depósito S3 reduce aún más este precio.
Dicha política moverá automáticamente los archivos más antiguos a diferentes clases de depósitos de S3, como un archivo o acceso a archivos profundos. Las clases también difieren por la velocidad del tiempo de acceso, pero para los datos antiguos, esto será un problema menor. Sirve principalmente para acceder a los datos archivados en caso de un evento urgente en lugar de necesidades de operaciones estándar.
- Puede organizar sus datos en subcarpetas.
- Debe establecer las restricciones de permisos adecuadas.
- Agregue etiquetas a los depósitos para que sean fáciles de identificar y para su posible uso dentro de las políticas dinámicas de depósitos de S3.
- El depósito no tiene servidor por diseño. Es simplemente un espacio de almacenamiento para sus datos.
Un depósito S3 no tiene servidor por diseño. Es simplemente un espacio de almacenamiento para sus datos.
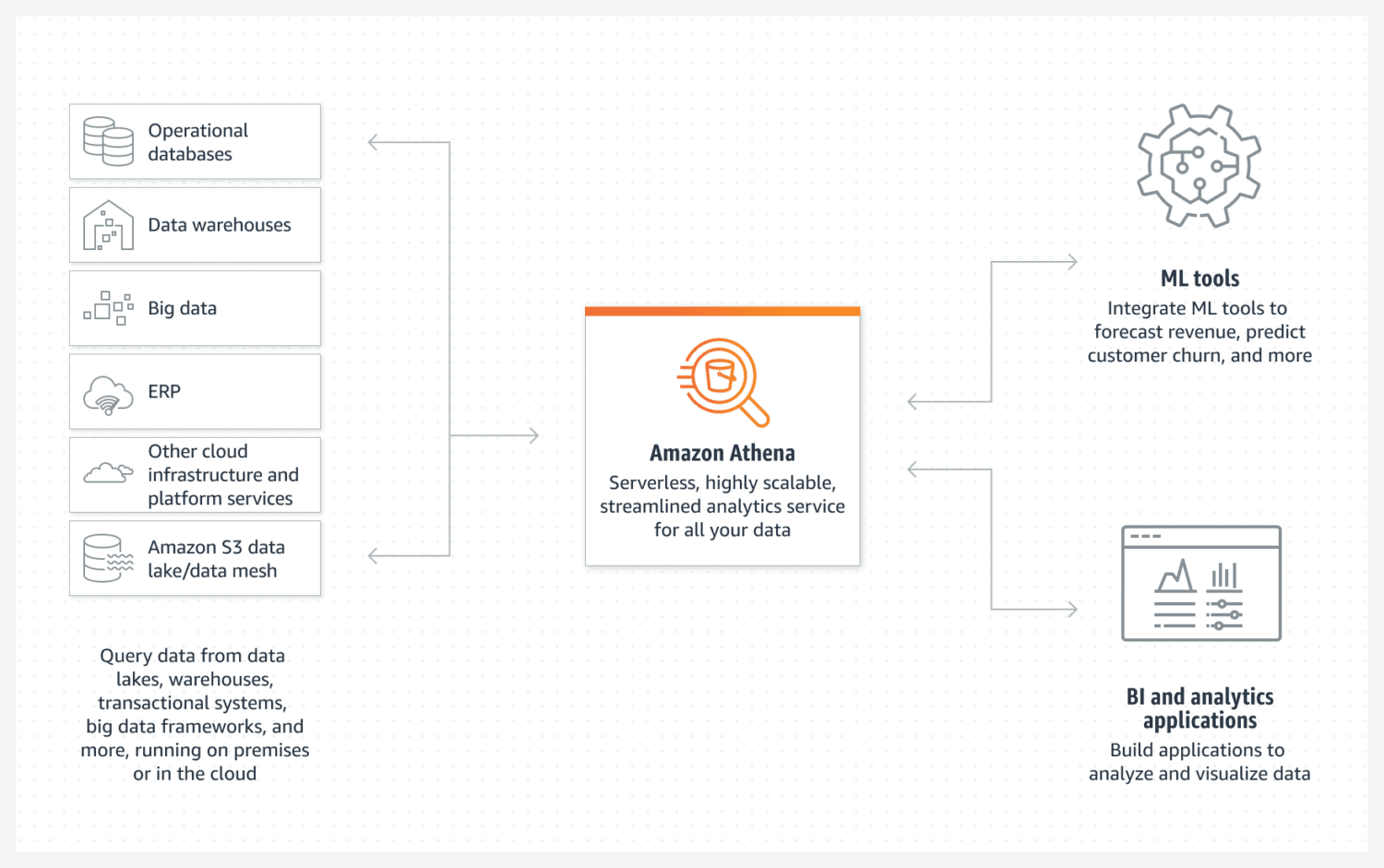
Base de datos AWS Athena
 Fuente: aws.amazon.com
Fuente: aws.amazon.com
Athena facilita la creación de un lago de datos básico de AWS. Es una base de datos sin servidores que utiliza un bucket de S3 para almacenar sus datos. La organización de los datos se mantiene mediante formatos de archivo estructurados como parquet o archivos de valores separados por comas (CSV). El depósito S3 contiene los archivos y Athena los consulta cada vez que los procesos seleccionan los datos de la base de datos.
Solo tenga en cuenta que Athena no es compatible con varias funcionalidades que de otro modo se considerarían estándar, por ejemplo, declaraciones de actualización. Es por eso que debe considerar a Athena como una opción muy simple.
Sin embargo, admite la indexación y el particionamiento. También puede escalar horizontalmente con mucha facilidad, ya que esto es tan complejo como agregar nuevos cubos a la infraestructura. Para la creación de lagos de datos simples pero funcionales, esto aún puede ser suficiente en la mayoría de los casos.
Para un buen rendimiento, es esencial seleccionar el mejor diseño de datos con un enfoque en el uso futuro. Es fundamental tener muy claro la forma en que desea seleccionar los datos. Volver a crear tablas más tarde, una vez que ya existen y están llenas de muchos datos, es difícil.
Athena DB es una excelente opción y una buena opción para su objetivo si busca crear un conjunto de datos simple e inmutable que sea fácil de escalar horizontalmente con el tiempo.
Base de datos Aurora de AWS
 Fuente: aws.amazon.com
Fuente: aws.amazon.com
Athena DB sobresale en el almacenamiento de datos no seleccionados. Así es como desea almacenar su contenido original para maximizar su reutilización futura, después de todo. Sin embargo, es lento proporcionar resultados selectos a una aplicación de front-end.
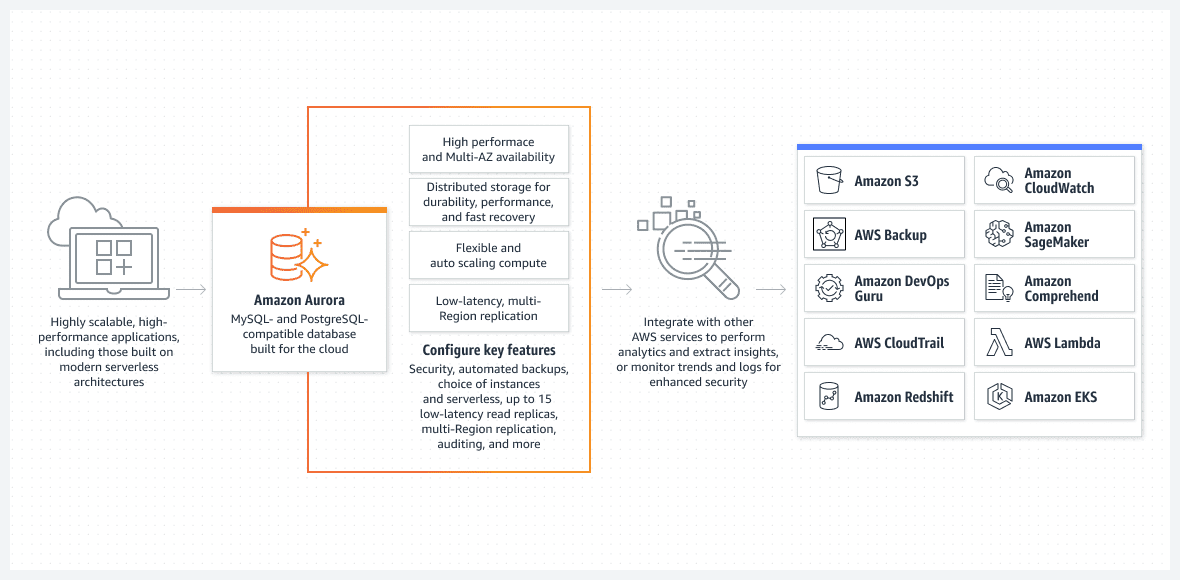
Una de las mejores opciones, principalmente desde la perspectiva de una configuración fácil de ejecutar, es la base de datos Aurora que se ejecuta en modo sin servidor.
Aurora está lejos de ser una base de datos básica. Es una de las soluciones de bases de datos relacionales nativas más avanzadas de AWS. También es una solución de base de datos relacional nativa altamente compleja que mejora con cada versión.
Aurora es única porque puede ejecutarse en modo sin servidor, lo que la destaca de otros servicios relacionales. Así es como funciona el modo:
- Para configurar el clúster de Aurora, utilice la consola de AWS. Deberá especificar los niveles estándar de CPU y RAM, así como el intervalo máximo de funcionalidad de escalado automático. Esto afectará el rendimiento que el clúster de Aurora puede agregar o eliminar dinámicamente. En función de la utilización actual de la base de datos, AWS decide aumentar o reducir la escala.
- El clúster de Aurora no se iniciará a menos que el usuario o el proceso inicie una solicitud real. Por ejemplo, cuando comienza el procesamiento por lotes programado. O si la aplicación realiza una llamada API de back-end para recuperar datos de una base de datos. La base de datos se abrirá automáticamente y permanecerá activa durante un tiempo predeterminado después de que se completen los procesos de solicitud.
- El clúster de Aurora se apagará automáticamente si no hay más trabajo en la base de datos.
Para enfatizarlo una vez más, Aurora DB sin servidor se ejecuta solo cuando tiene que hacer un trabajo real. El clúster iniciado automáticamente se apagará nuevamente si no está procesando ningún trabajo. El trabajo real es lo que paga y no su tiempo de inactividad.
La Aurora sin servidor está completamente administrada por AWS y no requiere un administrador.
AWS amplificar
Amplify ofrece una plataforma sin servidor para la implementación rápida de aplicaciones front-end creadas con bibliotecas JavaScript y React. No es necesario configurar servidores de clúster. Utilice la consola de AWS para implementar el código directamente o utilice una canalización de DevOps automatizada.
Puede llamar a las API de back-end para acceder a los datos almacenados en las bases de datos. Estas llamadas le permiten acceder a los datos reales en la aplicación frontal. El equipo debe realizar la optimización principal del rendimiento en el back-end. Incluso puede reducir aún más la posibilidad de una respuesta lenta en la interfaz de usuario si diseña declaraciones de selección efectivas dentro de las llamadas a la API directamente.
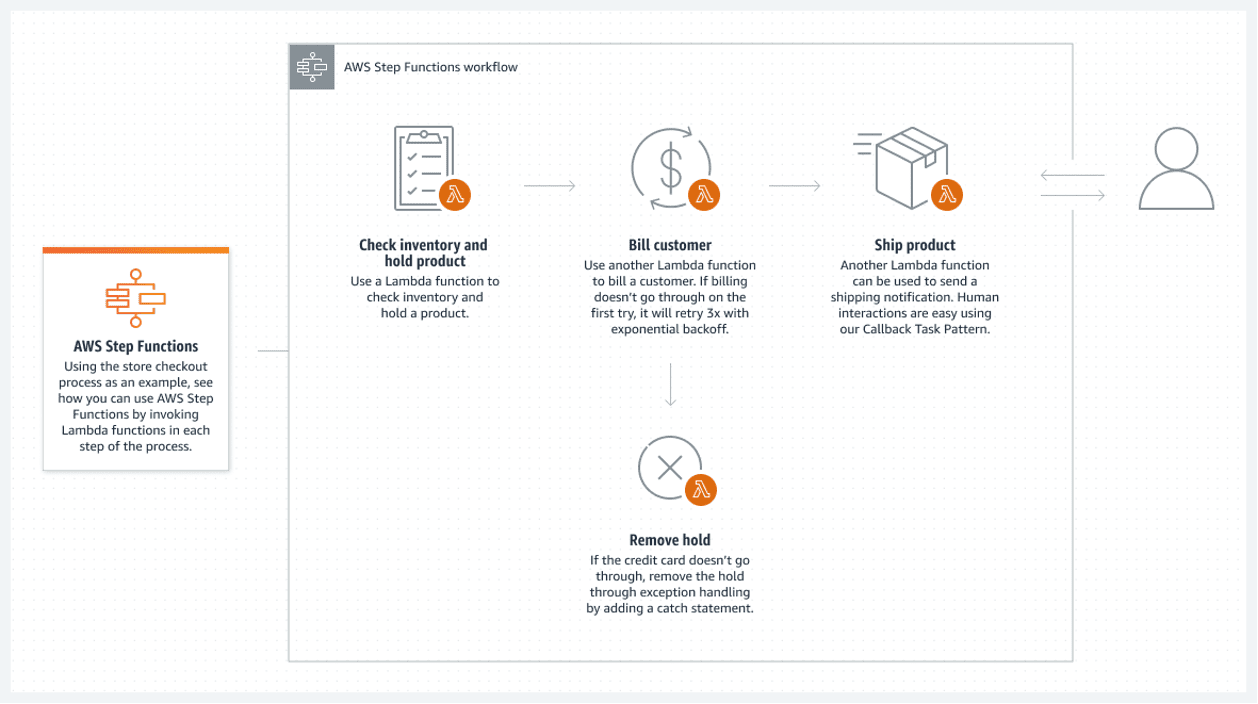
Funciones de pasos de AWS
 Fuente: aws.amazon.com
Fuente: aws.amazon.com
Aunque todos los componentes principales de un sistema no tienen servidor, esto no garantiza una arquitectura completamente sin servidor. Esto es posible solo si todos los procesos por lotes entre los componentes son sin servidor.
Las funciones de AWS Step proporcionan la mejor solución en la nube de AWS. Una lista conectada de funciones de AWS Lambda constituye la función de paso. Estas funciones crean un diagrama de flujo que tiene estados iniciales y finales claros. Una función lambda, generalmente escrita en los lenguajes Python o Node JS, es un fragmento de código ejecutable que procesa todo lo que se necesita.
El siguiente es un ejemplo de cómo puede ejecutar una función de paso:
Este flujo sin servidor tiene un gran inconveniente: cada función lambda solo puede ejecutarse durante 15 minutos como máximo. Por lo tanto, dividir el flujo en funciones lambda más pequeñas puede hacer que esto sea menos problemático.
Es posible llamar a múltiples funciones lambda simultáneamente en un solo paso, lo que básicamente significa paralelizar un paso con múltiples lambdas ejecutadas simultáneamente. Solo espere a que finalice todo el procesamiento lambda paralelo antes de continuar. Luego, continúe con el siguiente procesamiento lambda.
Ultimas palabras
La arquitectura sin servidor ofrece una oportunidad única para crear una plataforma en la nube que cubra todo el panorama del sistema. Esta plataforma es escalable horizontalmente y tiene bajos costos operativos mientras lo hace.
Es la solución perfecta para proyectos con presupuesto limitado. Es una excelente opción de exploración, típicamente cuando nadie conoce la realidad de la carga de producción. Esto es especialmente importante después de haber incorporado con éxito a todos los usuarios. Es posible que los equipos de proyecto aún obtengan una visión general de cómo funciona el sistema. Puede tener todos estos beneficios y aún así no necesita aceptar compromisos.
Esta cobertura no será adecuada para todos los casos, particularmente aquellos que involucran un alto uso de la CPU. Sin embargo, la nube de AWS evoluciona constantemente en términos de casos de uso sin servidor. Por lo general, es una buena idea realizar una investigación exhaustiva antes de decidirse por la opción sin servidor para su próximo proyecto en la nube de AWS.
A continuación, consulte las mejores bases de datos sin servidor para aplicaciones modernas.