
¿Estás listo para aprender ingeniería de funciones para el aprendizaje automático y la ciencia de datos? ¡Estás en el lugar correcto!
La ingeniería de funciones es una habilidad fundamental para extraer información valiosa de los datos y, en esta guía rápida, la dividiré en partes simples y digeribles. Entonces, ¡profundicemos y comencemos su viaje para dominar la extracción de funciones!
Tabla de contenido
¿Qué es la ingeniería de funciones?

Cuando crea un modelo de aprendizaje automático relacionado con un problema empresarial o experimental, proporciona datos de aprendizaje en columnas y filas. En el dominio de la ciencia de datos y el desarrollo de ML, las columnas se conocen como atributos o variables.
Los datos granulares o las filas debajo de estas columnas se conocen como observaciones o instancias. Las columnas o atributos son las características de un conjunto de datos sin procesar.
Estas características sin procesar no son suficientes ni óptimas para entrenar un modelo de aprendizaje automático. Para reducir el ruido de los metadatos recopilados y maximizar las señales únicas de las funciones, es necesario transformar o convertir columnas de metadatos en funciones funcionales mediante ingeniería de funciones.
Ejemplo 1: modelado financiero
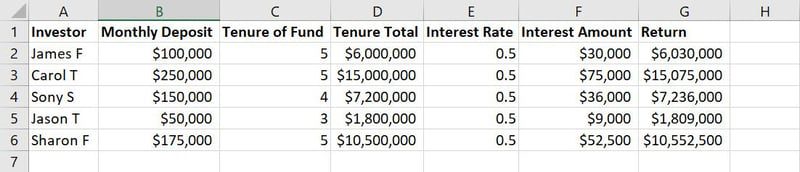 Datos sin procesar para el entrenamiento de modelos ML
Datos sin procesar para el entrenamiento de modelos ML
Por ejemplo, en la imagen de arriba de un conjunto de datos de ejemplo, las columnas de la A a la G son características. Los valores o cadenas de texto en cada columna a lo largo de las filas, como nombres, monto del depósito, años de depósito, tasas de interés, etc., son observaciones.
En el modelado de ML, debe eliminar, agregar, combinar o transformar datos para crear características significativas y reducir el tamaño de la base de datos de entrenamiento del modelo general. Esta es la ingeniería de características.
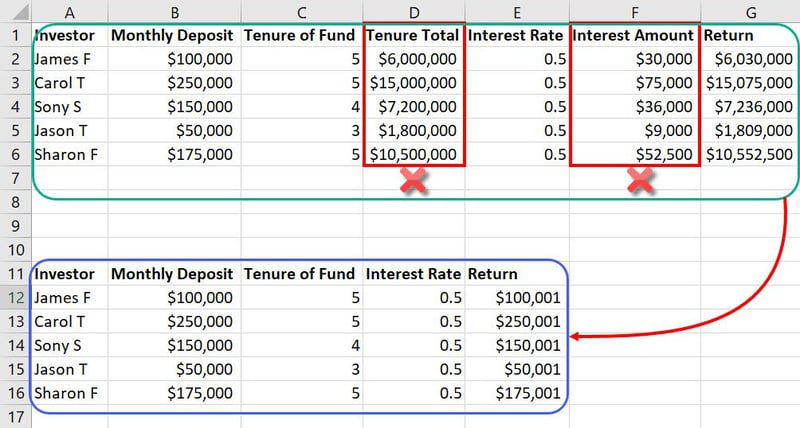 Ejemplo de ingeniería de características
Ejemplo de ingeniería de características
En el mismo conjunto de datos mencionado anteriormente, características como Tenure Total y Interest Amount son entradas innecesarias. Estos simplemente ocuparán más espacio y confundirán el modelo ML. Por lo tanto, puede reducir dos funciones de un total de siete funciones.
Dado que las bases de datos en los modelos ML contienen miles de columnas y millones de filas, la reducción de dos funciones tiene un gran impacto en el proyecto.
Ejemplo 2: Creador de listas de reproducción de música con IA
A veces, puedes crear una función completamente nueva a partir de varias funciones existentes. Suponga que está creando un modelo de IA que creará automáticamente una lista de reproducción de música y canciones según el evento, el gusto, el modo, etc.
Ahora, recopiló datos sobre canciones y música de varias fuentes y creó la siguiente base de datos:
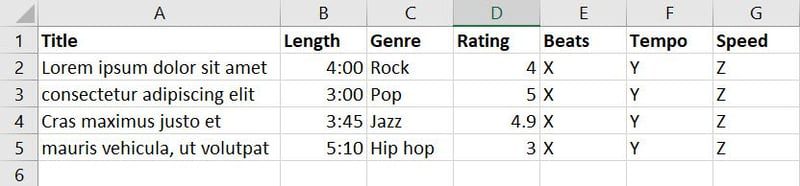
Hay siete características en la base de datos anterior. Sin embargo, dado que su objetivo es entrenar el modelo ML para decidir qué canción o música es adecuada para cada evento, puede agrupar funciones como Género, Clasificación, Ritmos, Tempo y Velocidad en una nueva función llamada Aplicabilidad.
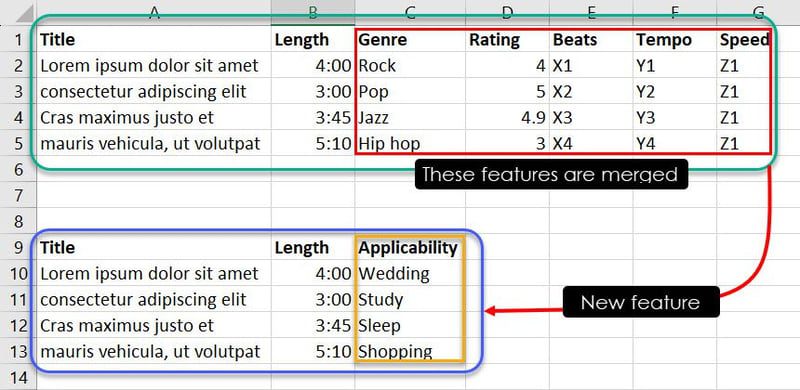
Ahora, ya sea mediante experiencia o identificación de patrones, puedes combinar ciertas instancias de características para determinar qué canción es adecuada para cada evento. Por ejemplo, observaciones como Jazz, 4.9, X3, Y3 y Z1 le dicen al modelo ML que la canción Cras maximus justo et debería estar en la lista de reproducción del usuario si está buscando una canción para dormir.
Tipos de funciones en el aprendizaje automático
Características categóricas
Estos son atributos de datos que representan categorías o etiquetas distintas. Debe utilizar este tipo para etiquetar conjuntos de datos cualitativos.
#1. Características categóricas ordinales
Las características ordinales tienen categorías con un orden significativo. Por ejemplo, los niveles educativos como Bachillerato, Licenciatura, Maestría, etc., tienen una clara distinción en los estándares, pero no existen diferencias cuantitativas.
#2. Características categóricas nominales
Los rasgos nominales son categorías sin ningún orden inherente. Algunos ejemplos podrían ser colores, países o tipos de animales. Además, sólo existen diferencias cualitativas.
Características de la matriz
Este tipo de característica representa datos organizados en matrices o listas. Los científicos de datos y los desarrolladores de ML suelen utilizar funciones de matriz para manejar secuencias o incrustar datos categóricos.
#1. Incorporación de características de matriz
Las matrices integradas convierten datos categóricos en vectores densos. Se utiliza comúnmente en sistemas de recomendación y procesamiento de lenguaje natural.
#2. Características de la matriz de lista
Las matrices de listas almacenan secuencias de datos, como listas de elementos en un pedido o el historial de acciones.
Características numéricas
Estas funciones de entrenamiento de ML se utilizan para realizar operaciones matemáticas, ya que estas funciones representan datos cuantitativos.
#1. Características numéricas de intervalo
Las funciones de intervalo tienen intervalos consistentes entre valores pero no tienen un punto cero verdadero (por ejemplo, datos de monitoreo de temperatura). Aquí, cero significa temperatura bajo cero, pero el atributo sigue ahí.
#2. Características numéricas de relación
Las características de relación tienen intervalos consistentes entre valores y un punto cero verdadero. Los ejemplos incluyen edad, altura e ingresos.
Importancia de la ingeniería de funciones en ML y ciencia de datos
A continuación, exploraremos el proceso paso a paso de ingeniería de funciones.
Proceso de ingeniería de funciones paso a paso

A continuación, analizaremos los métodos de ingeniería de características.
Métodos de ingeniería de características
#1. Análisis de Componentes Principales (PCA)
PCA simplifica datos complejos al encontrar nuevas características no correlacionadas. Estos se llaman componentes principales. Puede usarlo para reducir la dimensionalidad y mejorar el rendimiento del modelo.
#2. Características polinómicas
Crear entidades polinómicas significa agregar potencias de características existentes para capturar relaciones complejas en sus datos. Ayuda a su modelo a comprender patrones no lineales.
#3. Manejo de valores atípicos
Los valores atípicos son puntos de datos inusuales que pueden afectar el rendimiento de sus modelos. Debe identificar y gestionar los valores atípicos para evitar resultados sesgados.
#4. Transformación de registro
La transformación logarítmica puede ayudarle a normalizar datos con una distribución sesgada. Reduce el impacto de los valores extremos para que los datos sean más adecuados para el modelado.
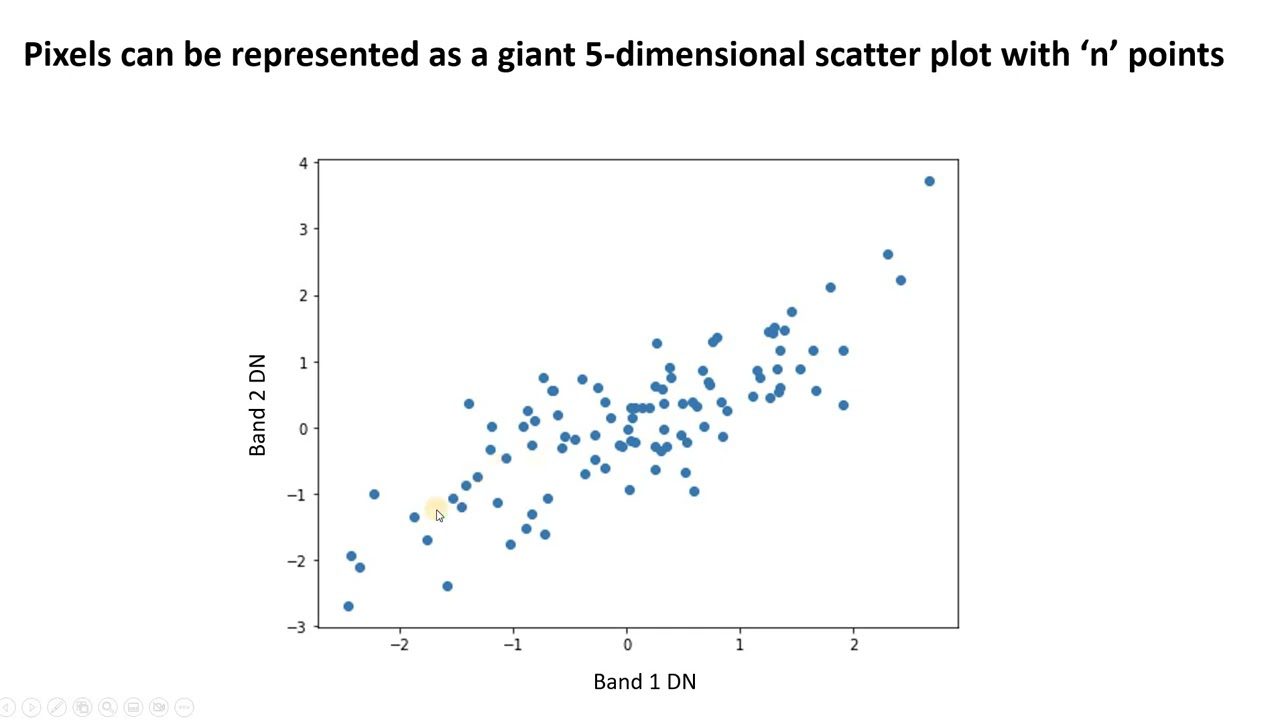
#5. Incrustación de vecinos estocásticos distribuidos en t (t-SNE)
t-SNE es útil para visualizar datos de alta dimensión. Reduce la dimensionalidad y hace que los clústeres sean más evidentes al tiempo que preserva la estructura de los datos.
En este método de extracción de características, los puntos de datos se representan como puntos en un espacio de dimensiones inferiores. Luego, se colocan los puntos de datos similares en el espacio original de alta dimensión y se modelan para que estén cerca unos de otros en la representación de menor dimensión.
Se diferencia de otros métodos de reducción de dimensionalidad al preservar la estructura y las distancias entre los puntos de datos.
#6. Codificación en caliente
La codificación one-hot transforma variables categóricas en formato binario (0 o 1). Entonces, obtienes nuevas columnas binarias para cada categoría. La codificación one-hot hace que los datos categóricos sean adecuados para los algoritmos de aprendizaje automático.
#7. Codificación de recuento
La codificación de recuento reemplaza los valores categóricos con la cantidad de veces que aparecen en el conjunto de datos. Puede capturar información valiosa de variables categóricas.
En este método de ingeniería de características, se utiliza la frecuencia o el recuento de cada categoría como una nueva característica numérica en lugar de utilizar las etiquetas de categoría originales.
#8. Estandarización de funciones

Las características de valores más grandes a menudo dominan las características de valores pequeños. Por lo tanto, el modelo ML puede volverse sesgado fácilmente. La estandarización previene tales causas de sesgos en un modelo de aprendizaje automático.
El proceso de estandarización normalmente implica las dos técnicas comunes siguientes:
- Estandarización de puntuación Z: este método transforma cada característica para que tenga una media (promedio) de 0 y una desviación estándar de 1. Aquí, se resta la media de la característica de cada punto de datos y se divide el resultado por la desviación estándar.
- Escala mín-máx: la escala mín-máx transforma los datos en un rango específico, generalmente entre 0 y 1. Puede lograr esto restando el valor mínimo de la característica de cada punto de datos y dividiéndolo por el rango.
#9. Normalización
A través de la normalización, las características numéricas se escalan a un rango común, generalmente entre 0 y 1. Mantiene las diferencias relativas entre valores y garantiza que todas las características estén en igualdad de condiciones.

#1. Herramientas de funciones
Herramientas de funciones es un marco Python de código abierto que crea automáticamente características a partir de conjuntos de datos temporales y relacionales. Se puede utilizar con herramientas que ya utiliza para desarrollar canales de aprendizaje automático.
La solución utiliza Deep Feature Synthesis para automatizar la ingeniería de funciones. Tiene una biblioteca de funciones de bajo nivel para crear funciones. Featuretools también tiene una API, que también es ideal para un manejo preciso del tiempo.
#2. gatoboost
Si está buscando una biblioteca de código abierto que combine múltiples árboles de decisión para crear un modelo predictivo potente, opte por gatoboost. Esta solución ofrece resultados precisos con parámetros predeterminados, por lo que no tiene que pasar horas ajustando los parámetros.
CatBoost también te permite utilizar factores no numéricos para mejorar los resultados de tu entrenamiento. Con él, también puede esperar obtener resultados más precisos y predicciones rápidas.
#3. Motor de funciones
Motor de funciones es una biblioteca de Python con múltiples transformadores y características seleccionadas que puede usar para modelos ML. Los transformadores que incluye se pueden utilizar para transformación de variables, creación de variables, funciones de fecha y hora, preprocesamiento, codificación categórica, limitación o eliminación de valores atípicos e imputación de datos faltantes. Es capaz de reconocer automáticamente variables numéricas, categóricas y de fecha y hora.
Recursos de aprendizaje de ingeniería destacados
Cursos en línea y clases virtuales

#1. Ingeniería de funciones para el aprendizaje automático en Python: Datacamp
Este campo de datos curso de Ingeniería de Funciones para Aprendizaje Automático en Python le permite crear nuevas funciones que mejoran el rendimiento de su modelo de aprendizaje automático. Le enseñará a realizar ingeniería de funciones y combinación de datos para desarrollar aplicaciones de aprendizaje automático sofisticadas.
#2. Ingeniería de funciones para el aprendizaje automático: Udemy
Desde el Curso de ingeniería de funciones para aprendizaje automáticoaprenderá temas que incluyen imputación, codificación de variables, extracción de características, discretización, funcionalidad de fecha y hora, valores atípicos, etc. Los participantes también aprenderán a trabajar con variables sesgadas y a lidiar con categorías poco frecuentes, invisibles y raras.
#3. Ingeniería de funciones: visión plural
Este Pluralvista La ruta de aprendizaje tiene un total de seis cursos. Estos cursos lo ayudarán a aprender la importancia de la ingeniería de funciones en el flujo de trabajo de ML, las formas de aplicar sus técnicas y la extracción de funciones de texto e imágenes.
#4. Selección de funciones para el aprendizaje automático: Udemy
Con la ayuda de este Udemy Por supuesto, los participantes pueden aprender a barajar funciones, filtrar, envolver y métodos integrados, eliminación recursiva de funciones y búsqueda exhaustiva. También analiza técnicas de selección de características, incluidas las de Python, Lasso y árboles de decisión. Este curso contiene 5,5 horas de vídeo bajo demanda y 22 artículos.
#5. Ingeniería de funciones para el aprendizaje automático: gran aprendizaje
Este curso de Gran aprendizaje Le presentará la ingeniería de funciones mientras le enseñará sobre sobremuestreo y submuestreo. Además, le permitirá realizar ejercicios prácticos sobre el ajuste de modelos.
#6. Ingeniería de funciones: Coursera
Disfruta el Coursera curso para usar BigQuery ML, Keras y TensorFlow para realizar ingeniería de funciones. Este curso de nivel intermedio también cubre prácticas avanzadas de ingeniería de funciones.
Libros digitales o de tapa dura

#1. Ingeniería de funciones para el aprendizaje automático
Este libro le enseña cómo transformar funciones en formatos para modelos de aprendizaje automático.
También le enseña principios de ingeniería de características y aplicaciones prácticas a través del ejercicio.
#2. Ingeniería y selección de características
Al leer este libro, aprenderá los métodos para desarrollar modelos predictivos en diferentes etapas.
A partir de él, puede aprender técnicas para encontrar las mejores representaciones de predictores para el modelado.
#3. Ingeniería de funciones simplificada
El libro es una guía para mejorar el poder de predicción de los algoritmos de ML.
Le enseña a diseñar y crear funciones eficientes para aplicaciones basadas en ML al ofrecer información detallada sobre los datos.
#4. Campamento de libros sobre ingeniería de funciones
Este libro trata con estudios de casos prácticos para enseñarle técnicas de ingeniería de funciones para obtener mejores resultados de aprendizaje automático y una gestión de datos mejorada.
Leer esto garantizará que pueda obtener mejores resultados sin perder mucho tiempo ajustando los parámetros de ML.
#5. El arte de la ingeniería de funciones
El recurso funciona como un elemento esencial para cualquier científico de datos o ingeniero de aprendizaje automático.
El libro utiliza un enfoque multidisciplinario para analizar gráficos, textos, series temporales, imágenes y estudios de casos.
Conclusión
Así es como se puede realizar la ingeniería de funciones. Ahora que conoce la definición, el proceso paso a paso, los métodos y los recursos de aprendizaje, puede implementarlos en sus proyectos de ML y ver el éxito.
A continuación, consulte el artículo sobre aprendizaje por refuerzo.