
Hace años, cuando los servidores Unix locales con grandes sistemas de archivos estaban de moda, las empresas creaban extensas reglas y estrategias de administración de carpetas para administrar los derechos de acceso a diferentes carpetas para diferentes personas.
Por lo general, la plataforma de una organización atiende a diferentes grupos de usuarios con intereses, restricciones de nivel de confidencialidad o definiciones de contenido completamente distintos. En el caso de organizaciones globales, esto podría incluso significar separar el contenido según la ubicación, básicamente, entre los usuarios que pertenecen a diferentes países.
Otros ejemplos típicos podrían incluir:
- separación de datos entre entornos de desarrollo, prueba y producción
- el contenido de ventas no es accesible para una amplia audiencia
- contenido legislativo específico del país que no se puede ver o acceder desde dentro de otra región
- contenido relacionado con el proyecto donde los «datos de liderazgo» se proporcionarán solo a un grupo limitado de personas, etc.
Hay una lista potencialmente interminable de tales ejemplos. El punto es que siempre existe algún tipo de necesidad de orquestar los derechos de acceso a archivos y datos entre todos los usuarios a los que la plataforma brinda acceso.
En el caso de las soluciones locales, esta era una tarea rutinaria. El administrador del sistema de archivos simplemente configuró algunas reglas, usó una herramienta de elección y luego las personas se asignaron a grupos de usuarios, y los grupos de usuarios se asignaron a una lista de carpetas o puntos de montaje a los que podrán acceder. En el camino, el nivel de acceso se definió como acceso de solo lectura o lectura y escritura.
Ahora que analiza las plataformas en la nube de AWS, es obvio esperar que las personas tengan requisitos similares para las restricciones de acceso al contenido. La solución a este problema debe ser, sin embargo ahora, diferente. Los archivos ya no resisten en servidores Unix sino en la nube (y potencialmente accesibles no solo para toda la organización sino incluso para todo el mundo), y el contenido no se almacena en carpetas sino en cubos S3.

A continuación se describe una alternativa para abordar este problema. Se basa en la experiencia del mundo real que tuve mientras diseñaba tales soluciones para un proyecto concreto.
Tabla de contenido
Enfoque simple pero sumamente manual
Una forma de resolver este problema sin ninguna automatización es relativamente sencilla y sencilla:
- Cree un nuevo cubo para cada grupo distinto de personas.
- Asigne derechos de acceso al depósito para que solo este grupo específico pueda acceder al depósito S3.
Esto es ciertamente posible si el requisito es ir con una resolución muy simple y rápida. Hay, sin embargo, algunos límites a tener en cuenta.
De forma predeterminada, solo se pueden crear hasta 100 depósitos S3 en una cuenta de AWS. Este límite se puede ampliar a 1000 enviando un aumento del límite de servicio al ticket de AWS. Si esos límites no son algo que le preocupe a su caso particular de implementación, entonces puede dejar que cada uno de sus distintos usuarios de dominio opere en un depósito S3 separado y llamarlo por día.
Los problemas pueden surgir si hay algunos grupos de personas con responsabilidades multifuncionales o simplemente algunas personas que necesitan acceder al contenido de más dominios al mismo tiempo. Por ejemplo:
- Analistas de datos que evalúan el contenido de los datos para varias áreas, regiones, etc.
- El equipo de pruebas compartió servicios para diferentes equipos de desarrollo.
- Informar a los usuarios que requieren crear un panel de análisis sobre diferentes países dentro de la misma región.
Como puede imaginar, esta lista puede volver a crecer tanto como pueda imaginar, y las necesidades de las organizaciones pueden generar todo tipo de casos de uso.
Cuanto más compleja se vuelva esta lista, más compleja será la orquestación de derechos de acceso para otorgar a todos esos grupos diferentes derechos de acceso diferentes a diferentes depósitos de S3 en la organización. Se requerirán herramientas adicionales, y tal vez incluso un recurso dedicado (administrador) necesitará mantener las listas de derechos de acceso y actualizarlas cada vez que se solicite algún cambio (que será muy frecuente, especialmente si la organización es grande).
Entonces, ¿cómo lograr lo mismo de una forma más organizada y automatizada?
Si el enfoque de cubo por dominio no funciona, cualquier otra solución terminará con cubos compartidos para más grupos de usuarios. En tales casos, es necesario construir toda la lógica de asignación de derechos de acceso en algún área que sea fácil de cambiar o actualizar dinámicamente.
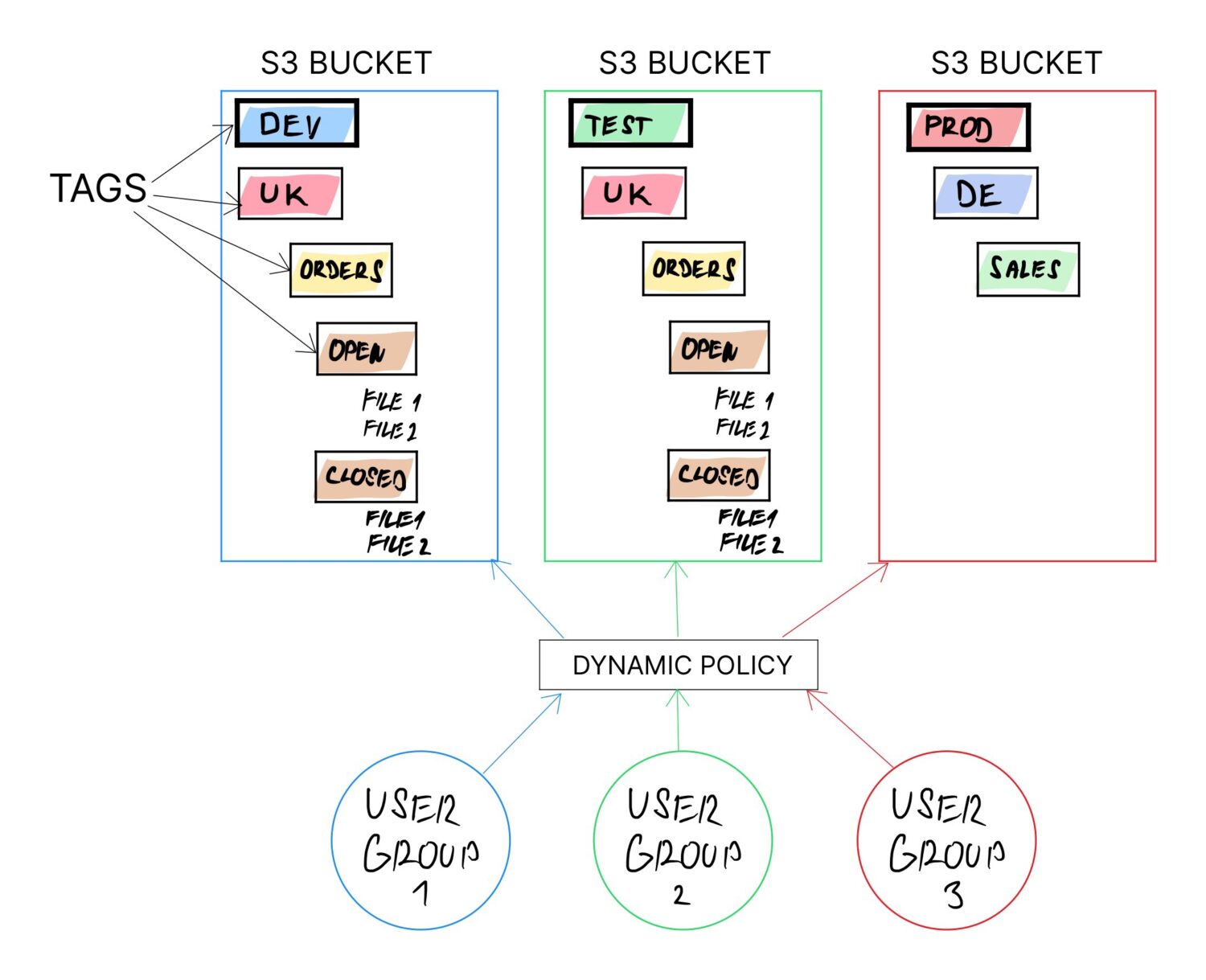
Una de las formas de lograrlo es mediante el uso de etiquetas en los cubos S3. Se recomienda utilizar las etiquetas en cualquier caso (aunque solo sea para permitir una categorización de facturación más sencilla). Sin embargo, la etiqueta se puede cambiar en cualquier momento en el futuro para cualquier depósito.
Si toda la lógica se crea en función de las etiquetas del depósito y el resto depende de la configuración de los valores de las etiquetas, la propiedad dinámica está asegurada, ya que se puede redefinir el propósito del depósito simplemente actualizando los valores de las etiquetas.
¿Qué tipo de etiquetas usar para que esto funcione?
Esto depende de su caso de uso concreto. Por ejemplo:
- Puede ser necesario separar cubos por tipo de entorno. Entonces, en ese caso, uno de los nombres de las etiquetas será algo así como «ENV» y con posibles valores «DEV», «TEST», «PROD», etc.
- Tal vez quieras separar el equipo según el país. En ese caso, otra etiqueta será “PAÍS” y valorará algún nombre de país.
- O puede querer separar a los usuarios según el departamento funcional al que pertenecen, como analistas de negocios, usuarios de almacenamiento de datos, científicos de datos, etc. Entonces crea una etiqueta con el nombre «USER_TYPE» y el valor respectivo.
- Otra opción podría ser que desee definir explícitamente una estructura de carpetas fija para grupos de usuarios específicos que deben usar (para no crear su propio desorden de carpetas y perderse allí con el tiempo). Puede hacerlo nuevamente con etiquetas, donde puede especificar varios directorios de trabajo como: «datos/importación», «datos/procesados», «datos/error», etc.
Idealmente, desea definir las etiquetas para que puedan combinarse lógicamente y hacer que formen una estructura de carpetas completa en el depósito.
Por ejemplo, puede combinar las siguientes etiquetas de los ejemplos anteriores para construir una estructura de carpetas dedicada para diferentes tipos de usuarios de varios países con carpetas de importación predefinidas que se espera que usen:
- /
/ / /
Simplemente cambiando el valor de
Esto permitirá el uso del mismo cubo para muchos usuarios diferentes. Los cubos no admiten carpetas explícitamente, pero sí admiten «etiquetas». Esas etiquetas funcionan como subcarpetas al final porque los usuarios necesitan pasar por una serie de etiquetas para llegar a sus datos (tal como lo harían con las subcarpetas).
Una vez definidas las etiquetas en alguna forma utilizable, el siguiente paso es crear políticas de depósito de S3 que usarían las etiquetas.
Si las políticas usan los nombres de las etiquetas, está creando algo llamado «políticas dinámicas». Básicamente, esto significa que su política se comportará de manera diferente para depósitos con diferentes valores de etiqueta a los que se refiere la política en forma o marcadores de posición.
Obviamente, este paso implica cierta codificación personalizada de las políticas dinámicas, pero puede simplificar este paso utilizando la herramienta de edición de políticas de Amazon AWS, que lo guiará a través del proceso.
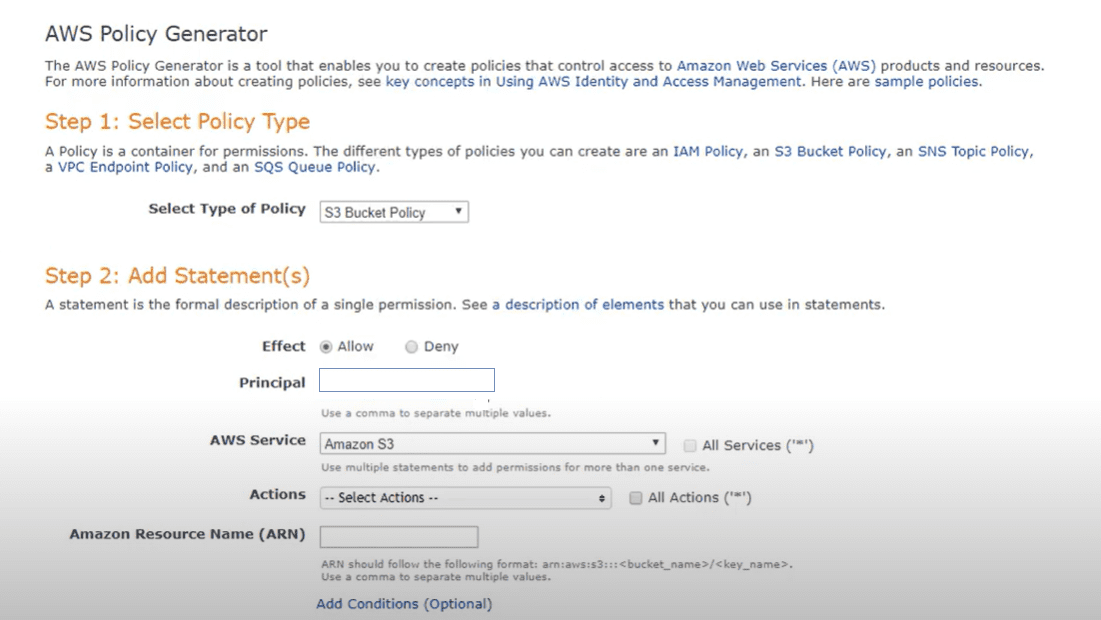
En la propia política, querrá codificar derechos de acceso concretos que se aplicarán al depósito y el nivel de acceso de dichos derechos (lectura, escritura). La lógica leerá las etiquetas en los cubos y construirá la estructura de carpetas en el cubo (creando etiquetas basadas en las etiquetas). En función de los valores concretos de las etiquetas, se crearán las subcarpetas y se asignarán los derechos de acceso necesarios a lo largo de la línea.
Lo bueno de una política tan dinámica es que puede crear solo una política dinámica y luego asignar la misma política dinámica a muchos depósitos. Esta política se comportará de manera diferente para depósitos con diferentes valores de etiqueta, pero siempre estará de acuerdo con sus expectativas para un depósito con dichos valores de etiqueta.
Es una forma realmente efectiva de administrar las asignaciones de derechos de acceso de una manera organizada y centralizada para una gran cantidad de depósitos, donde se espera que cada depósito siga algunas estructuras de plantilla acordadas por adelantado y que sus usuarios usarán dentro toda la organización.
Automatice la incorporación de nuevas entidades
Después de definir políticas dinámicas y asignarlas a los depósitos existentes, los usuarios pueden comenzar a usar los mismos depósitos sin el riesgo de que los usuarios de diferentes grupos no accedan al contenido (almacenado en el mismo depósito) ubicado en una estructura de carpetas donde no tienen acceso.
Además, para algunos grupos de usuarios con un acceso más amplio, será fácil acceder a los datos porque estarán todos almacenados en el mismo depósito.
El paso final es hacer que la incorporación de nuevos usuarios, nuevos cubos e incluso nuevas etiquetas sea lo más simple posible. Esto lleva a otra codificación personalizada que, sin embargo, no necesita ser demasiado compleja, suponiendo que su proceso de incorporación tenga algunas reglas muy claras que se pueden encapsular con una lógica de algoritmo simple y directa (al menos puede probar de esta manera que su proceso tiene algo de lógica y no se hace de una manera demasiado caótica).
Esto puede ser tan simple como crear un script ejecutable mediante el comando AWS CLI con los parámetros necesarios para incorporar con éxito una nueva entidad en la plataforma. Incluso puede ser una serie de scripts CLI, ejecutables en un orden específico, como, por ejemplo:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - etc.
Tú entiendes. 😃
Un consejo profesional 👨💻
Hay un consejo profesional si lo desea, que se puede aplicar fácilmente además de los anteriores.
¡Las políticas dinámicas se pueden aprovechar no solo para asignar derechos de acceso para ubicaciones de carpetas, sino también para asignar derechos de servicio para los depósitos y grupos de usuarios automáticamente!
Todo lo que se necesitaría es extender la lista de etiquetas en los cubos y luego agregar derechos de acceso de políticas dinámicas para usar servicios específicos para grupos concretos de usuarios.
Por ejemplo, puede haber algún grupo de usuarios que también necesite acceso al servidor de clúster de base de datos específico. Sin duda, esto se puede lograr mediante políticas dinámicas que aprovechen las tareas de depósito, más aún si los accesos a los servicios están impulsados por un enfoque basado en roles. Simplemente agregue al código de política dinámica una parte que procesará las etiquetas relacionadas con la especificación del clúster de la base de datos y asignará los privilegios de acceso a la política a ese clúster de base de datos y grupo de usuarios en particular directamente.
De esta manera, la incorporación de un nuevo grupo de usuarios será ejecutable solo por esta única política dinámica. Además, dado que es dinámica, la misma política se puede reutilizar para incorporar muchos grupos de usuarios diferentes (se espera que sigan la misma plantilla pero no necesariamente los mismos servicios).
También puede echar un vistazo a estos comandos de AWS S3 para administrar depósitos y datos.