Si desea fusionar datos de dos archivos de texto haciendo coincidir un campo común, puede usar el comando de unión de Linux. Agrega una pizca de dinamismo a sus archivos de datos estáticos. Te mostraremos cómo usarlo.
Tabla de contenido
Coincidencia de datos entre archivos
Los datos son el rey. Corporaciones, negocios y hogares lo manejan. Pero los datos almacenados en diferentes archivos y recopilados por diferentes personas son una molestia. Además de saber qué archivos abrir para encontrar la información que desea, es probable que el diseño y el formato de los archivos sean diferentes.
También debe lidiar con el dolor de cabeza administrativo de qué archivos deben actualizarse, cuáles deben respaldarse, cuáles son heredados y cuáles pueden archivarse.
Además, si necesita consolidar sus datos o realizar algún análisis en un conjunto de datos completo, tiene un problema adicional. ¿Cómo racionaliza los datos en los diferentes archivos antes de poder hacer lo que necesita hacer con ellos? ¿Cómo aborda la fase de preparación de datos?
La buena noticia es que si los archivos comparten al menos un elemento de datos común, el comando join de Linux puede sacarlo del fango.
Los archivos de datos
Todos los datos que usaremos para demostrar el uso del comando join son ficticios, comenzando con los siguientes dos archivos:
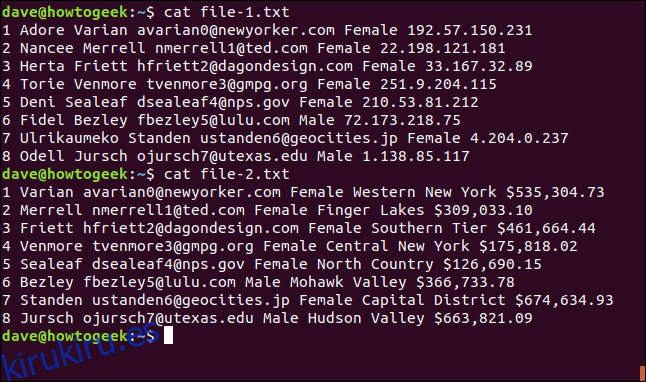
cat file-1.txt
cat file-2.txt
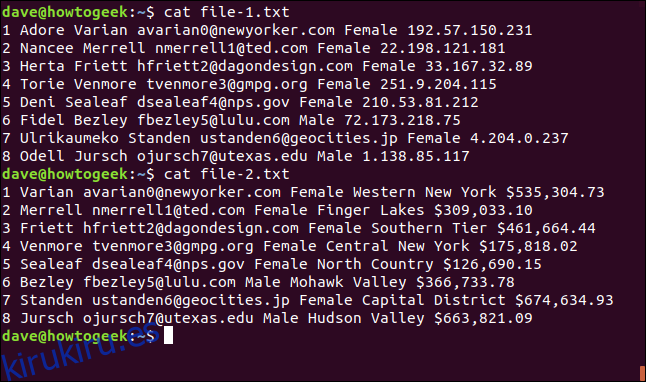
El siguiente es el contenido de file-1.txt:
1 Adore Varian [email protected] Female 192.57.150.231 2 Nancee Merrell [email protected] Female 22.198.121.181 3 Herta Friett [email protected] Female 33.167.32.89 4 Torie Venmore [email protected] Female 251.9.204.115 5 Deni Sealeaf [email protected] Female 210.53.81.212 6 Fidel Bezley [email protected] Male 72.173.218.75 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 8 Odell Jursch [email protected] Male 1.138.85.117
Tenemos un conjunto de líneas numeradas y cada línea contiene toda la siguiente información:
Un número
Un nombre
Un apellido
Una dirección de correo electrónico
El sexo de la persona
Una dirección IP
El siguiente es el contenido de file-2.txt:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93 8 Jursch [email protected] Male Hudson Valley $663,821.09
Cada línea en file-2.txt contiene la siguiente información:
Un número
Un apellido
Una dirección de correo electrónico
El sexo de la persona
Una región de Nueva York
Un valor en dólares
El comando de unión funciona con «campos», que, en este contexto, significa una sección de texto rodeada por espacios en blanco, el comienzo de una línea o el final de una línea. Para que la combinación haga coincidir las líneas entre los dos archivos, cada línea debe contener un campo común.
Por lo tanto, solo podemos hacer coincidir un campo si aparece en ambos archivos. La dirección IP solo aparece en un archivo, por lo que no es bueno. El primer nombre solo aparece en un archivo, por lo que tampoco podemos usarlo. El apellido está en ambos archivos, pero sería una mala elección, ya que diferentes personas tienen el mismo apellido.
Tampoco puede vincular los datos con las entradas masculinas y femeninas, porque son demasiado vagas. Las regiones de Nueva York y los valores en dólares solo aparecen en un archivo también.
Sin embargo, podemos usar la dirección de correo electrónico porque está presente en ambos archivos y cada uno es único para un individuo. Un vistazo rápido a los archivos también confirma que las líneas en cada uno corresponden a la misma persona, por lo que podemos usar los números de línea como nuestro campo para hacer coincidir (usaremos un campo diferente más adelante).
Tenga en cuenta que hay un número diferente de campos en los dos archivos, lo cual está bien: podemos decirle a join qué campo usar de cada archivo.
Sin embargo, tenga cuidado con campos como las regiones de Nueva York; en un archivo separado por espacios, cada palabra en el nombre de una región parece un campo. Debido a que algunas regiones tienen nombres de dos o tres palabras, en realidad tiene un número diferente de campos dentro del mismo archivo. Esto está bien, siempre que coincida en los campos que aparecen en la línea antes de las regiones de Nueva York.
El comando de unión
Primero, el campo que va a hacer coincidir debe estar ordenado. Tenemos números ascendentes en ambos archivos, por lo que cumplimos con ese criterio. Por defecto, join usa el primer campo de un archivo, que es lo que queremos. Otro valor predeterminado sensato es que join espera que los separadores de campo sean espacios en blanco. Una vez más, tenemos eso, así que podemos seguir adelante y activar Join.
Como usamos todos los valores predeterminados, nuestro comando es simple:
join file-1.txt file-2.txt
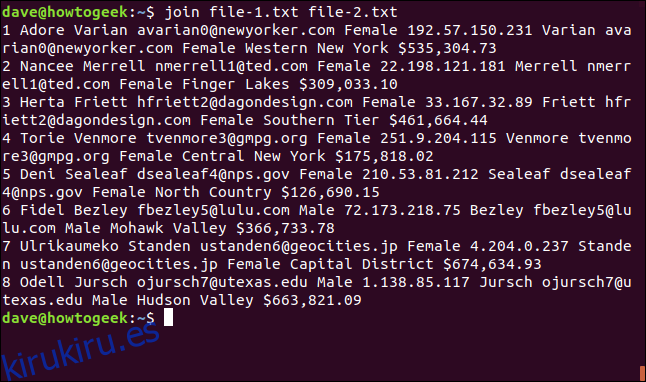
join considera que los archivos son «archivo uno» y «archivo dos» de acuerdo con el orden en el que aparecen en la línea de comando.
El resultado es el siguiente:
1 Adore Varian [email protected] Female 192.57.150.231 Varian [email protected] Female Western New York $535,304.73 2 Nancee Merrell [email protected] Female 22.198.121.181 Merrell [email protected] Female Finger Lakes $309,033.10 3 Herta Friett [email protected] Female 33.167.32.89 Friett [email protected] Female Southern Tier $461,664.44 4 Torie Venmore [email protected] Female 251.9.204.115 Venmore [email protected] Female Central New York $175,818.02 5 Deni Sealeaf [email protected] Female 210.53.81.212 Sealeaf [email protected] Female North Country $126,690.15 6 Fidel Bezley [email protected] Male 72.173.218.75 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 Standen [email protected] Female Capital District $674,634.93 8 Odell Jursch [email protected] Male 1.138.85.117 Jursch [email protected] Male Hudson Valley $663,821.09
La salida se formatea de la siguiente manera: El campo en el que se hicieron coincidir las líneas se imprime primero, seguido de los otros campos del archivo uno y luego los campos del archivo dos sin el campo de coincidencia.
Campos sin clasificar
Intentemos algo que sabemos que no funcionará. Pondremos las líneas en un archivo desordenadas para que join no pueda procesar el archivo correctamente. El contenido de file-3.txt es el mismo que file-2.txt, pero la línea ocho está entre las líneas cinco y seis.
El siguiente es el contenido de file-3.txt:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 8 Jursch [email protected] Male Hudson Valley $663,821.09 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Escribimos el siguiente comando para intentar unir el archivo-3.txt al archivo-1.txt:
join file-1.txt file-3.txt
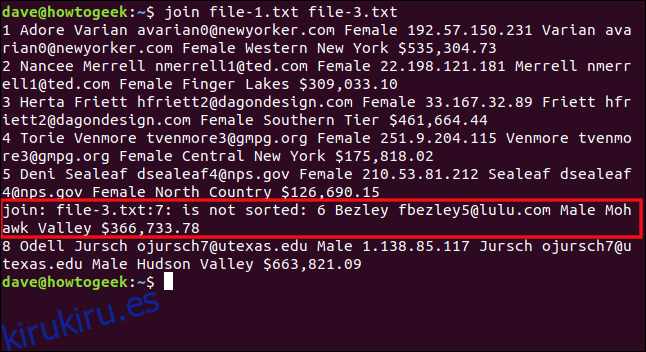
join informa que la séptima línea en file-3.txt está fuera de servicio, por lo que no se procesa. La línea siete es la que comienza con el número seis, que debe ir antes del ocho en una lista ordenada correctamente. La sexta línea del archivo (que comienza con «8 Odell») fue la última procesada, por lo que vemos el resultado.
Puede usar la opción –check-order si desea ver si la unión está conforme con el orden de clasificación de los archivos; no se intentará fusionar.
Para hacerlo, escribimos lo siguiente:
join --check-order file-1.txt file-3.txt
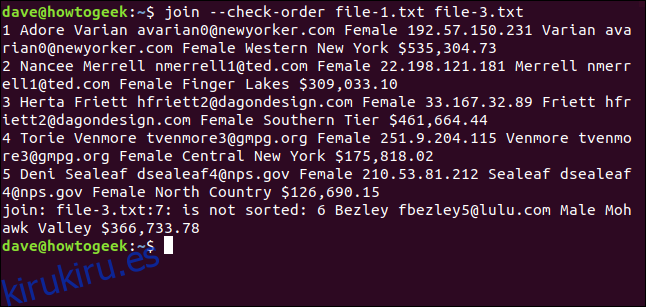
join le dice de antemano que habrá un problema con la línea siete del archivo file-3.txt.
Archivos con líneas faltantes
En file-4.txt, se eliminó la última línea, por lo que no hay una línea ocho. Los contenidos son los siguientes:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Escribimos lo siguiente y, sorprendentemente, join no se queja y procesa todas las líneas que puede:
join file-1.txt file-4.txt
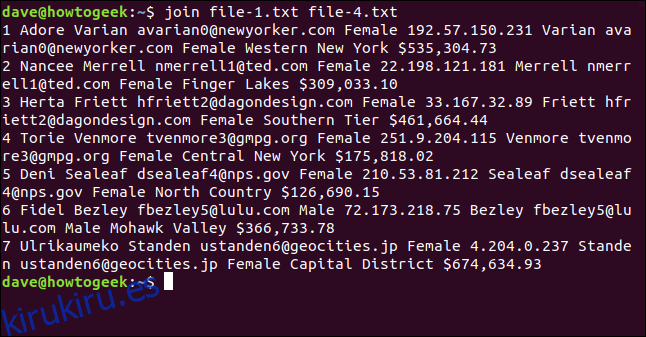
La salida enumera siete líneas fusionadas.
La opción -a (imprimir no emparejable) le dice a join que también imprima las líneas que no pudieron coincidir.
Aquí, escribimos el siguiente comando para decirle a join que imprima las líneas del archivo uno que no pueden coincidir con las líneas del archivo dos:
join -a 1 file-1.txt file-4.txt
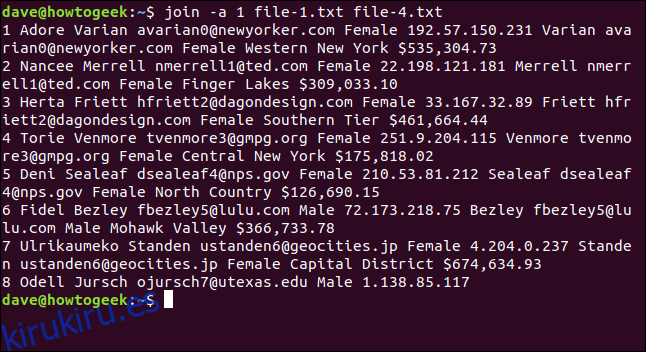
Siete líneas coinciden y la línea ocho del archivo uno está impresa, sin coincidencia. No hay ninguna información combinada porque file-4.txt no contiene una línea ocho con la que pueda coincidir. Sin embargo, al menos todavía aparece en la salida para que sepa que no tiene una coincidencia en el archivo-4.txt.
Escribimos el siguiente comando -v (suprimir líneas unidas) para revelar las líneas que no coinciden:
join -v file-1.txt file-4.txt

Vemos que la línea ocho es la única que no tiene una coincidencia en el archivo dos.
Coincidencia de otros campos
Hagamos coincidir dos archivos nuevos en un campo que no es el predeterminado (campo uno). El siguiente es el contenido de file-7.txt:
[email protected] Female 192.57.150.231 [email protected] Female 210.53.81.212 [email protected] Male 72.173.218.75 [email protected] Female 33.167.32.89 [email protected] Female 22.198.121.181 [email protected] Male 1.138.85.117 [email protected] Female 251.9.204.115 [email protected] Female 4.204.0.237
Y el siguiente es el contenido de file-8.txt:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
El único campo sensato que se puede usar para unirse es la dirección de correo electrónico, que es el campo uno en el primer archivo y el campo dos en el segundo. Para adaptarse a esto, podemos usar las opciones -1 (archivo de un campo) y -2 (archivo de dos campos). Seguiremos estos con un número que indica qué campo en cada archivo debe usarse para unirse.
Escribimos lo siguiente para decirle a join que use el primer campo en el archivo uno y el segundo en el archivo dos:
join -1 1 -2 2 file-7.txt file-8.txt
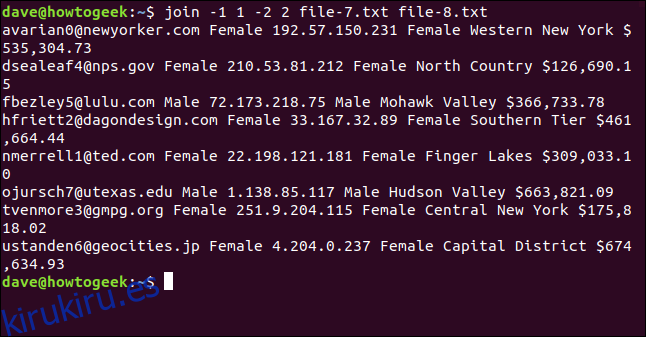
Los archivos se unen en la dirección de correo electrónico, que se muestra como el primer campo de cada línea en la salida.
Usando diferentes separadores de campo
¿Qué sucede si tiene archivos con campos separados por algo que no sea un espacio en blanco?
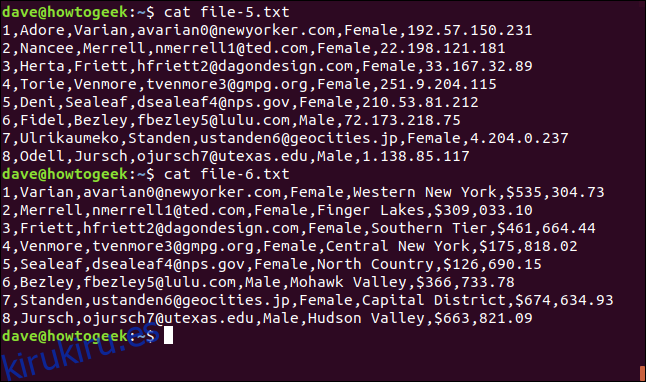
Los dos archivos siguientes están delimitados por comas; el único espacio en blanco está entre los nombres de lugares de varias palabras:
cat file-5.txt
cat file-6.txt
Podemos usar el -t (carácter separador) para decirle a join qué carácter usar como separador de campo. En este caso, es la coma, entonces escribimos el siguiente comando:
join -t, file-5.txt file-6.txt
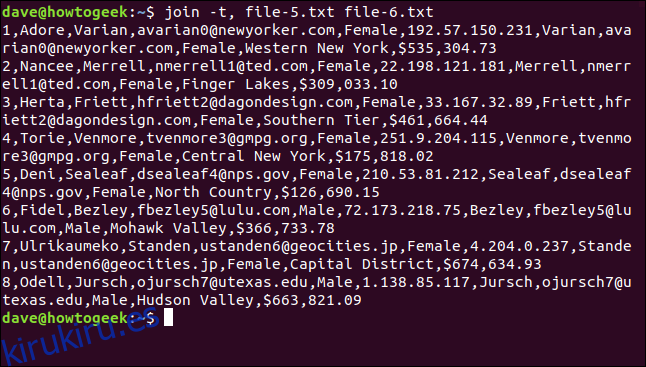
Todas las líneas coinciden y los espacios se conservan en los nombres de los lugares.
Ignorar mayúsculas y minúsculas
Otro archivo, file-9.txt, es casi idéntico al file-8.txt. La única diferencia es que algunas de las direcciones de correo electrónico tienen una letra mayúscula, como se muestra a continuación:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
Cuando unimos file-7.txt y file-8.txt, funcionó perfectamente. Veamos qué sucede con file-7.txt y file-9.txt.
Escribimos el siguiente comando:
join -1 1 -2 2 file-7.txt file-9.txt
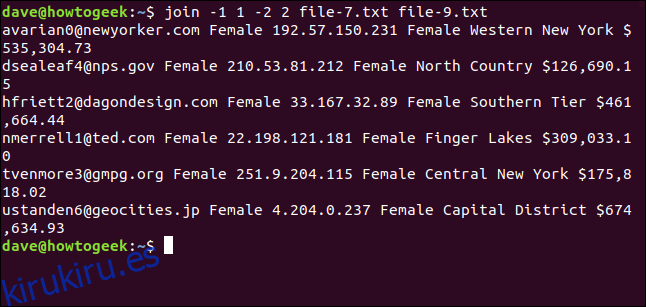
Solo emparejamos seis líneas. Las diferencias en letras mayúsculas y minúsculas impidieron que se unieran las otras dos direcciones de correo electrónico.
Sin embargo, podemos usar la opción -i (ignorar mayúsculas y minúsculas) para forzar la unión a ignorar esas diferencias y hacer coincidir los campos que contienen el mismo texto, independientemente del caso.
Escribimos el siguiente comando:
join -1 1 -2 2 -i file-7.txt file-9.txt
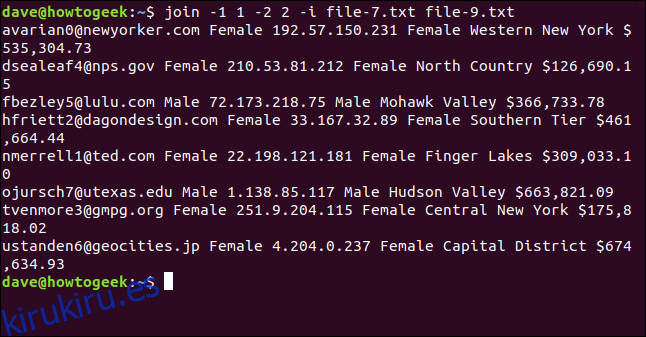
Las ocho líneas se combinan y unen correctamente.
Mezclar y combinar
Al unirse, tiene un aliado poderoso cuando está luchando con una preparación de datos incómoda. Tal vez necesite analizar los datos, o tal vez esté tratando de darles forma para realizar una importación a un sistema diferente.
No importa cuál sea la situación, ¡se alegrará de haberse unido en su esquina!