
El comando uniq de Linux recorre rápidamente sus archivos de texto en busca de líneas únicas o duplicadas. En esta guía, cubrimos su versatilidad y características, así como también cómo puede aprovechar al máximo esta ingeniosa utilidad.
Tabla de contenido
Encontrar líneas de texto coincidentes en Linux
El comando uniq es rápido, flexible y excelente en lo que hace. Sin embargo, al igual que muchos comandos de Linux, tiene algunas peculiaridades, lo cual está bien, siempre que los conozca. Si da el paso sin un poco de conocimiento interno, bien podría quedarse rascándose la cabeza con los resultados. Señalaremos estas peculiaridades a medida que avanzamos.
El comando uniq es perfecto para aquellos en el campo de un solo propósito, diseñado para hacer una cosa y hacerlo bien. Es por eso que también es particularmente adecuado para trabajar con tuberías y desempeñar su papel en las tuberías de comando. Uno de sus colaboradores más frecuentes es sort porque uniq tiene que tener una entrada ordenada sobre la que trabajar.
¡Vamos a encenderlo!
Ejecutando uniq sin opciones
Tenemos un archivo de texto que contiene la letra para De Robert Johnson canción Creo que sacaré el polvo de mi escoba. Veamos qué hace uniq con él.
Escribiremos lo siguiente para canalizar la salida a menos:
uniq dust-my-broom.txt | less

Obtenemos la canción completa, incluidas las líneas duplicadas, en menos:
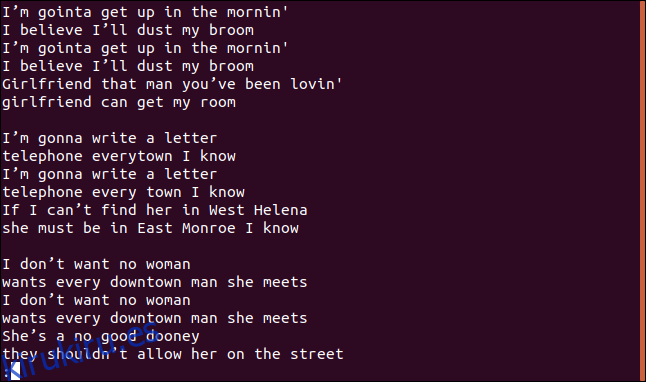
Eso no parece ser ni las líneas únicas ni las líneas duplicadas.
Correcto, porque esta es la primera peculiaridad. Si ejecuta uniq sin opciones, se comporta como si hubiera utilizado la opción -u (líneas únicas). Esto le dice a uniq que imprima solo las líneas únicas del archivo. La razón por la que ve líneas duplicadas es porque, para que uniq considere una línea como un duplicado, debe estar adyacente a su duplicado, que es donde entra la ordenación.
Cuando ordenamos el archivo, agrupa las líneas duplicadas y uniq las trata como duplicadas. Usaremos ordenar en el archivo, canalizar la salida ordenada a uniq y luego canalizar la salida final a menos.
Para hacerlo, escribimos lo siguiente:
sort dust-my-broom.txt | uniq | less

Aparece una lista ordenada de líneas en menos.
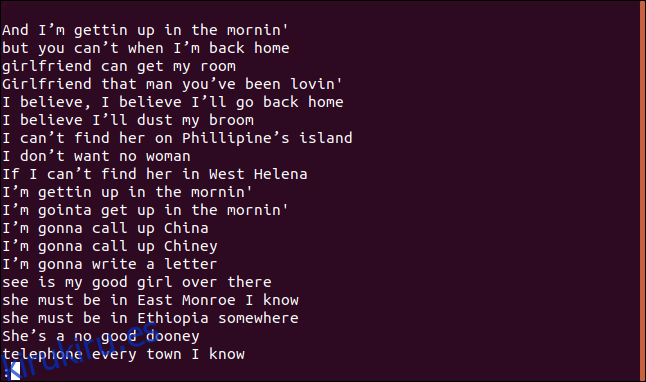
La línea, «Creo que quitaré el polvo de mi escoba», definitivamente aparece en la canción más de una vez. De hecho, se repite dos veces en las primeras cuatro líneas de la canción.
Entonces, ¿por qué aparece en una lista de líneas únicas? Debido a que la primera vez que aparece una línea en el archivo, es única; solo las entradas posteriores son duplicadas. Puede pensar en ello como una lista de la primera aparición de cada línea única.
Usemos ordenar nuevamente y redirigamos la salida a un nuevo archivo. De esta manera, no tenemos que usar ordenar en cada comando.
Escribimos el siguiente comando:
sort dust-my-broom.txt > sorted.txt
 sorted.txt ”en una ventana de terminal. ‘ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);” onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (esto);”>
sorted.txt ”en una ventana de terminal. ‘ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);” onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (esto);”>
Ahora, tenemos un archivo preordenado para trabajar.
Contando duplicados
Puede utilizar la opción -c (recuento) para imprimir el número de veces que aparece cada línea en un archivo.
Escriba el siguiente comando:
uniq -c sorted.txt | less

Cada línea comienza con la cantidad de veces que esa línea aparece en el archivo. Sin embargo, notará que la primera línea está en blanco. Esto le indica que hay cinco líneas en blanco en el archivo.
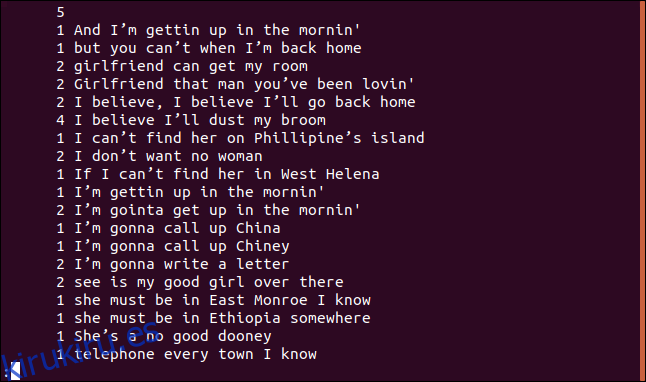
Si desea que la salida se clasifique en orden numérico, puede alimentar la salida de uniq en sort. En nuestro ejemplo, usaremos las opciones -r (inversa) y -n (ordenación numérica) y canalizaremos los resultados a menos.
Escribimos lo siguiente:
uniq -c sorted.txt | sort -rn | less

La lista está ordenada en orden descendente según la frecuencia de aparición de cada línea.
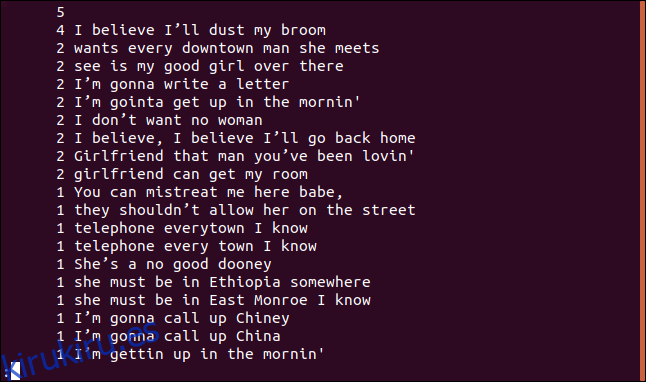
Listar solo líneas duplicadas
Si desea ver solo las líneas que se repiten en un archivo, puede usar la opción -d (repetidas). No importa cuántas veces se duplica una línea en un archivo, solo aparece una vez.
Para usar esta opción, escribimos lo siguiente:
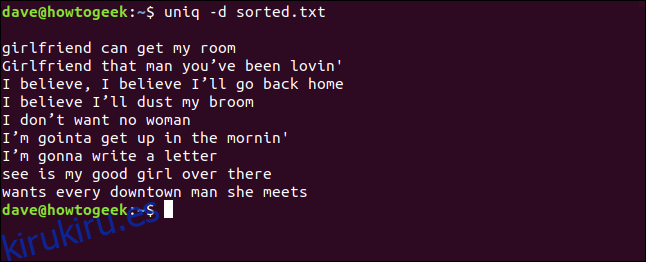
uniq -d sorted.txt

Las líneas duplicadas se enumeran para nosotros. Notará la línea en blanco en la parte superior, lo que significa que el archivo contiene líneas en blanco duplicadas; no es un espacio dejado por uniq para compensar cosméticamente la lista.
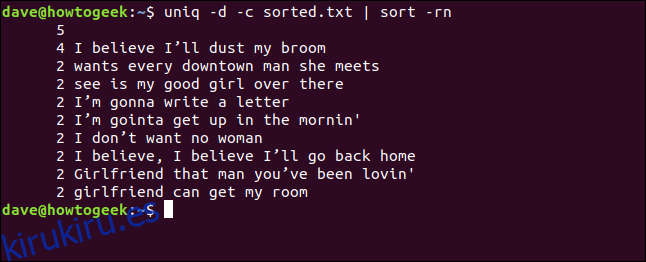
También podemos combinar las opciones -d (repetido) y -c (recuento) y canalizar la salida a través de sort. Esto nos da una lista ordenada de las líneas que aparecen al menos dos veces.
Escriba lo siguiente para usar esta opción:
uniq -d -c sorted.txt | sort -rn
Listado de todas las líneas duplicadas
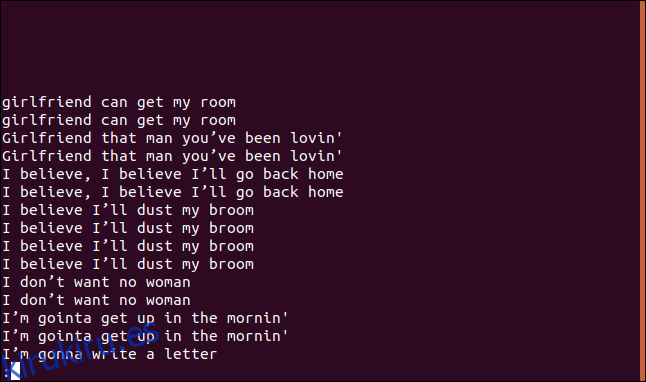
Si desea ver una lista de cada línea duplicada, así como una entrada por cada vez que aparece una línea en el archivo, puede usar la opción -D (todas las líneas duplicadas).
Para utilizar esta opción, escriba lo siguiente:
uniq -D sorted.txt | less

El listado contiene una entrada para cada línea duplicada.
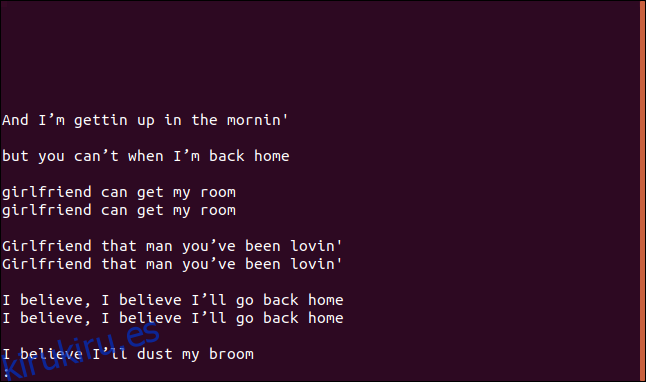
Si usa la opción –group, imprime cada línea duplicada con una línea en blanco antes (anteponer) o después de cada grupo (añadir), o antes y después (ambos) de cada grupo.
Estamos usando append como nuestro modificador, así que escribimos lo siguiente:
uniq --group=append sorted.txt | less

Los grupos están separados por líneas en blanco para facilitar su lectura.
Comprobación de cierto número de caracteres
De forma predeterminada, uniq comprueba la longitud completa de cada línea. Sin embargo, si desea restringir las comprobaciones a un cierto número de caracteres, puede utilizar la opción -w (comprobar caracteres).
En este ejemplo, repetiremos el último comando, pero limitaremos las comparaciones a los primeros tres caracteres. Para hacerlo, escribimos el siguiente comando:
uniq -w 3 --group=append sorted.txt | less

Los resultados y agrupaciones que recibimos son bastante diferentes.
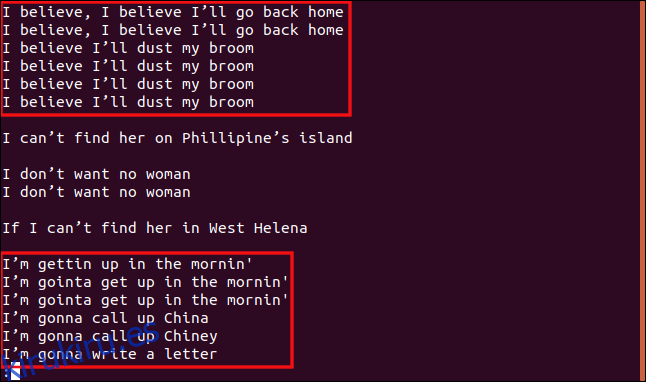
Todas las líneas que comienzan con «I b» se agrupan porque esas partes de las líneas son idénticas, por lo que se consideran duplicadas.
Del mismo modo, todas las líneas que comienzan con “I’m” se tratan como duplicadas, incluso si el resto del texto es diferente.
Ignorar cierto número de caracteres
Hay algunos casos en los que puede resultar beneficioso omitir una determinada cantidad de caracteres al principio de cada línea, como cuando las líneas de un archivo están numeradas. O, digamos que necesita uniq para saltar una marca de tiempo y comenzar a verificar las líneas desde el carácter seis en lugar de desde el primer carácter.
A continuación se muestra una versión de nuestro archivo ordenado con líneas numeradas.
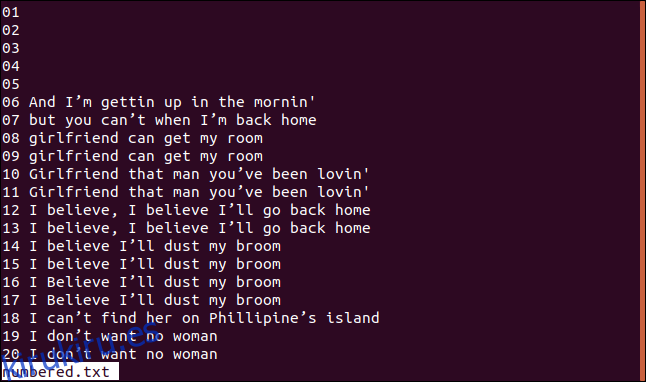
Si queremos que uniq comience sus comprobaciones de comparación en el carácter tres, podemos usar la opción -s (omitir caracteres) escribiendo lo siguiente:
uniq -s 3 -d -c numbered.txt
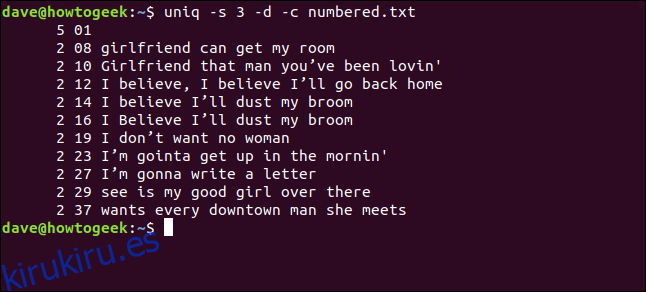
Las líneas se detectan como duplicadas y se cuentan correctamente. Observe que los números de línea que se muestran son los de la primera aparición de cada duplicado.
También puede omitir campos (una serie de caracteres y algunos espacios en blanco) en lugar de caracteres. Usaremos la opción -f (campos) para decirle a uniq qué campos ignorar.
Escribimos lo siguiente para decirle a uniq que ignore el primer campo:
uniq -f 1 -d -c numbered.txt
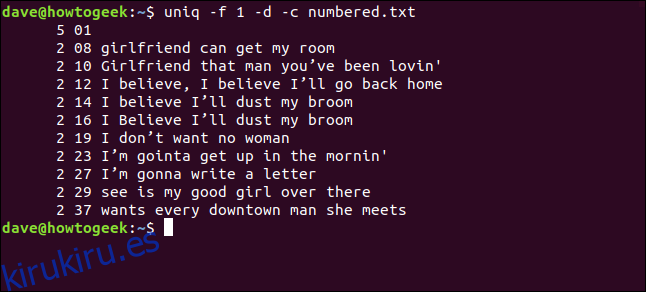
Obtenemos los mismos resultados que obtuvimos cuando le dijimos a uniq que omitara tres caracteres al comienzo de cada línea.
Ignorando el caso
De forma predeterminada, uniq distingue entre mayúsculas y minúsculas. Si la misma letra aparece en mayúscula y en minúsculas, uniq considera que las líneas son diferentes.
Por ejemplo, consulte el resultado del siguiente comando:
uniq -d -c sorted.txt | sort -rn
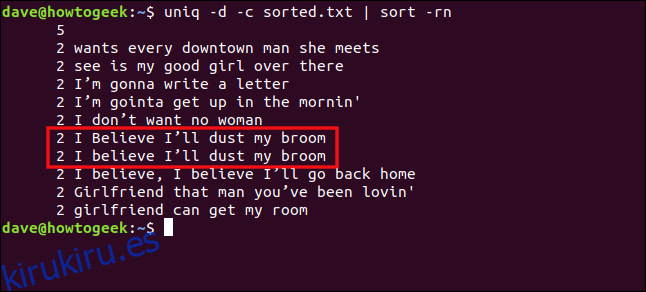
Las líneas «Creo que quitaré el polvo de mi escoba» y «Creo que quitaré el polvo de mi escoba» no se tratan como duplicadas debido a la diferencia entre mayúsculas y minúsculas en la «B» en «creer».
Sin embargo, si incluimos la opción -i (ignorar mayúsculas y minúsculas), estas líneas se tratarán como duplicadas. Escribimos lo siguiente:
uniq -d -c -i sorted.txt | sort -rn
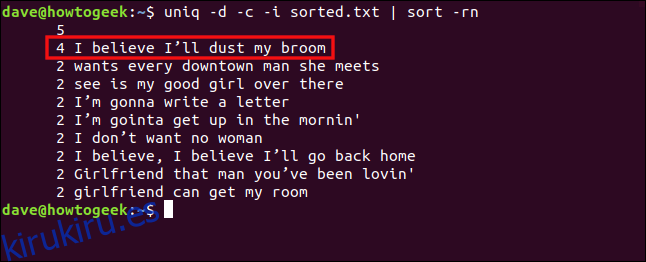
Las líneas ahora se tratan como duplicadas y se agrupan.
Linux pone a tu disposición multitud de utilidades especiales. Como muchos de ellos, uniq no es una herramienta que usará todos los días.
Es por eso que una gran parte de ser competente en Linux es recordar qué herramienta resolverá su problema actual y dónde puede encontrarla nuevamente. Sin embargo, si practicas, estarás bien encaminado.
O bien, siempre puede buscar kirukiru.es; probablemente tengamos un artículo al respecto.