Cuando decimos computación “sin servidor”, muchos asumen que no hay un servidor en este modelo para facilitar la ejecución del código y otras tareas de desarrollo. Es un simple concepto erróneo.
Entonces, después de este destructor de mitos, puede estar pensando cuál es la lógica detrás del nombre «sin servidor».
Déjame darte una pista: en lugar de «sin servidor», CÓMO se administran e implementan los servidores es lo que implica «Sin servidor».
¿Suena confuso?
Bueno, aprenderemos todo sobre serverless y otros términos relacionados para despejar tus dudas. Para empezar, serverless se está volviendo famoso en este momento. De hecho, es probable que el mercado sin servidor alcance $ 7.7 mil millones para 2021 de $ 1.9 mil millones en 2016.
Entonces, hablemos de serverless e intentemos descubrir la razón detrás de su popularidad.
Tabla de contenido
¿Qué es la informática sin servidor?
La computación sin servidor o sin servidor es un modelo de ejecución basado en la nube en el que los proveedores de servicios en la nube aprovisionan recursos de máquinas bajo demanda y administran los servidores por sí mismos en lugar de los clientes o desarrolladores. Es una forma que combina servicios, estrategias y prácticas para ayudar a los desarrolladores a crear aplicaciones basadas en la nube permitiéndoles concentrarse en su código en lugar de en la administración del servidor.
Desde la asignación de recursos, la planificación de la capacidad, la administración, las configuraciones y el escalado hasta los parches, las actualizaciones, la programación y el mantenimiento, el proveedor de servicios en la nube (como AWS o Google Cloud Platform) asume toda la responsabilidad de administrar las tareas comunes de la infraestructura. Como resultado, los desarrolladores pueden concentrar su esfuerzo y tiempo en la lógica comercial de sus procesos y aplicaciones.
Esta arquitectura informática sin servidor nunca mantiene los recursos informáticos en la memoria volátil; en cambio, la computación se lleva a cabo en partes cortas. Supongamos que no está utilizando una aplicación, no se le asignarán recursos. Por lo tanto, está pagando por el recurso que realmente consume en las aplicaciones.
El objetivo principal detrás de la creación del modelo sin servidor es simplificar el proceso de implementación de código en producción. Muchas veces, también funciona con estilos tradicionales como microservicios. Una vez que se implementa la tecnología sin servidor, las aplicaciones que impulsa comienzan a responder a las demandas rápidamente y se amplían o reducen automáticamente según sea necesario.
La informática sin servidor utiliza un modelo basado en eventos para determinar los requisitos de escalado. Por lo tanto, los desarrolladores ya no necesitan anticipar el uso de una aplicación para decidir cuántos servidores o ancho de banda requieren. Puede exigir más servidores y ancho de banda en función de sus necesidades crecientes sin reserva previa o reducir la escala en cualquier momento sin problemas.
¿Cómo evolucionó Serverless?
El sistema tradicional tenía desafíos asociados con la escalabilidad y la agilidad en el proceso de desarrollo e implementación de aplicaciones. A medida que aumentaba la demanda de aplicaciones de alta calidad con un rápido tiempo de comercialización, comenzó a surgir la necesidad de un mejor sistema que pudiera ofrecer más escalabilidad y agilidad. Resultó en la evolución de la computación en la nube y los modelos sin servidor.
El modelo sin servidor evolucionó en varias etapas, desde monolítico hasta microservicios y arquitectura sin servidor o función como servicio (FaaS).
- La arquitectura monolítica es un enfoque unificado tradicional para el desarrollo de software. Es un modelo estrechamente acoplado en el que cada componente y sus subcomponentes compilan o ejecutan código. Si un servicio es defectuoso, todo el servidor de aplicaciones y los servicios en ejecución pueden dejar de funcionar.
- La arquitectura de microservicios es una colección de servicios más pequeños dentro de una sola aplicación grande implementada de forma independiente para realizar una función específica. Permite la entrega rápida de aplicaciones a gran escala, lo que brinda a los desarrolladores flexibilidad mediante el uso de Infraestructura como servicio (IaaS) y Plataforma como servicio (PaaS). Sin embargo, elegir entre PaaS e IaaS es un desafío en este modelo.
- La arquitectura sin servidor evolucionó con la computación en la nube y ofrece más escalabilidad y agilidad comercial. En lugar de IaaS y PaaS, utiliza FaaS y Backend-as-a-Service (BaaS). Aquí, las aplicaciones se implementan según sea necesario, junto con los recursos para ello. No tienes que administrar el servidor y puedes dejar de pagar si finaliza la ejecución del código.
Atributos de la informática sin servidor
Algunos de los atributos de la informática sin servidor son los siguientes:
- La mayoría de las aplicaciones que utilizan serverless comprenden funciones únicas y pequeñas unidades de código.
- Ejecuta código solo bajo demanda, generalmente en un contenedor de software sin estado, y se escala sin problemas en función de la demanda.
- No se necesita la gestión del servidor por parte de los clientes.
- Cuenta con ejecución basada en eventos donde el entorno informático se crea una vez que se activa una función o se recibe un evento para ejecutar la solicitud.
- Escalabilidad flexible para que pueda escalar hacia arriba o hacia abajo fácilmente. Una vez que se ejecuta un código, la infraestructura deja de funcionar y se ahorra el costo. De manera similar, cuando la función continúa ejecutándose, puede escalar infinitamente según sea necesario.
- Puede usar servicios de nube administrados para manejar tareas complejas como almacenamiento de archivos, colas, bases de datos y más.
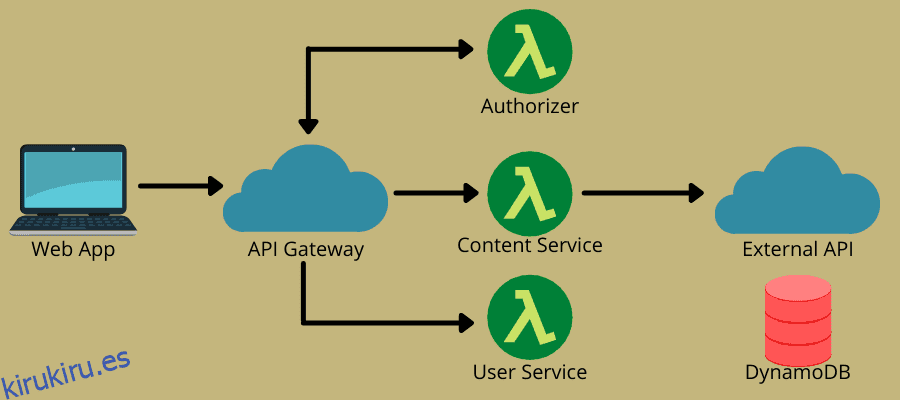
¿Cómo funciona sin servidor?
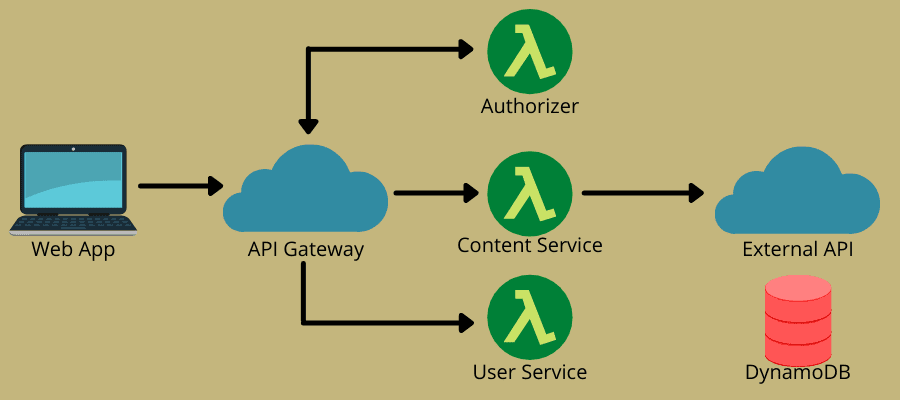
La arquitectura sin servidor combina dos ideas principales: función como servicio (FaaS) y backend como servicio (BaaS). Se basa más en FaaS, que permite servicios en la nube para la ejecución de código sin necesidad de instancias completamente aprovisionadas. FaaS consta de funciones sin estado, basadas en eventos, escalables y del lado del servidor que los servicios en la nube administran por completo.
El modelo permite a los equipos de DevOps escribir código centrándose en su lógica empresarial. A continuación, definen un evento que puede activar la función, como las solicitudes HTTP, para su ejecución. En consecuencia, el proveedor de la nube ejecuta la función y envía los resultados a las aplicaciones que los usuarios pueden ver.
De esta manera, el modelo sin servidor ofrece rentabilidad y conveniencia con funciones de escalado automático, bajo demanda y de pago por uso. Por lo tanto, muchas empresas y equipos de DevOps se están quedando sin servidor en estos días.
¿Quién usa Serverless y por qué?
Serverless es una de las tecnologías más emergentes en el desarrollo de software. Podría eliminar la gestión de la infraestructura y las necesidades de aprovisionamiento en el futuro.
Es útil para:
- Las organizaciones que desean una mayor escalabilidad y flexibilidad con una mejor capacidad de prueba de aplicaciones pueden optar por no tener servidor.
- Desarrolladores que desean reducir el tiempo de comercialización mediante la creación de aplicaciones ágiles y de alto rendimiento
- Empresas que no necesitan sus servidores funcionando todo el tiempo. Pueden llamar a funciones basadas en módulos usando aplicaciones, cuando sea necesario, para ahorrar costos.
- Organizaciones que desean crear aplicaciones eficientes basadas en la nube y simplificar la migración a la nube
- Los desarrolladores que buscan formas de reducir la latencia pueden ofrecer a los usuarios acceso a algunas funciones o aplicaciones.
- Una empresa que no tiene suficientes recursos para manejar el mantenimiento y la complejidad de la infraestructura de TI puede optar por la informática sin servidor para resolver problemas automáticamente y no necesita mantenimiento de su parte.
Algunos usuarios notables del modelo sin servidor son Slack, Coca-Cola, NetFlix, etc.
Debido a sus atributos únicos, el modelo sin servidor es adecuado para muchos casos de uso, como:
- Aplicaciones web: puede crear aplicaciones web rápidas y escalables utilizando este modelo que responde rápidamente a las demandas de los usuarios. Es ideal para crear aplicaciones sin estado que puede iniciar instantáneamente y aplicaciones que pueden satisfacer aumentos repentinos e impredecibles en las demandas de los usuarios.
- Back-ends de API: en las plataformas sin servidor, cualquier función se puede convertir fácilmente en puntos finales HTTP listos para que los utilicen los clientes. Estas funciones o acciones se conocen como acciones web cuando están habilitadas en la web. Y una vez que están habilitados, ensamblar las funciones en una API completa se vuelve fácil. También puede usar una puerta de enlace API decente para brindar más seguridad, soporte de dominio, limitación de velocidad y soporte OAuth.
- Microservicios: Serverless se usa ampliamente en el modelo de microservicios que se enfoca en crear pequeños servicios capaces de realizar una sola función y comunicarse entre sí mediante API.
Aunque es posible crear microservicios utilizando contenedores de software y PaaS, la arquitectura sin servidor es más eficiente. Facilita líneas de código más pequeñas que realizan una sola cosa y ofrece un aprovisionamiento rápido, escalado automático y precios flexibles que no cobran a los clientes cuando los recursos no están en uso. - Procesamiento de datos: Serverless es excelente para trabajar con datos que contienen videos, audio, imágenes y texto estructurado. También es favorable para varias tareas como validación de datos, transformación, enriquecimiento, limpieza, normalización de audio y procesamiento de PDF. Puede aprovecharlo para el procesamiento de imágenes que incluye nitidez, rotación, generación de miniaturas, reducción de ruido. Otros usos de serverless en el procesamiento de datos pueden ser la transcodificación de video y el reconocimiento óptico de caracteres (OCR).
- Procesamiento de secuencias/lotes: puede crear potentes aplicaciones de transmisión y canalizaciones de datos utilizando FaaS y una base de datos con Apache Kafka. El modelo sin servidor se adapta a diferentes ingestas de flujo, incluidos datos para registros de aplicaciones, sensores de IoT, lógica empresarial y el mercado financiero.
- Cómputo paralelo: Serverless es excelente para tareas relacionadas con el cómputo paralelo, donde cada tarea se ejecuta en paralelo para ejecutar una tarea específica. Puede incluir búsqueda de datos, procesamiento, operaciones de mapas, web scraping, procesamiento de genomas, ajuste de hiperparámetros, etc.
- Otros usos: Serverless también se usa para varias aplicaciones, como la gestión de relaciones con los clientes (CRM), finanzas, chatbots e inteligencia y análisis de negocios, por nombrar algunas.
Nota: Serverless puede no ser ideal para algunos casos. Por ejemplo, las aplicaciones grandes con cargas de trabajo predecibles y casi constantes pueden beneficiarse más de una arquitectura de sistema tradicional. Pueden optar por servidores dedicados, ya sean administrados o autoadministrados. Además, si su organización tiene configuraciones tradicionales completas con sistemas y aplicaciones heredados, puede ser costoso y desafiante cambiar a una arquitectura completamente nueva y diferente.
Ventajas y desventajas de la informática sin servidor
Cada moneda tiene dos caras, al igual que la arquitectura sin servidor. También tiene algunas ventajas y desventajas basadas en diferentes parámetros. Entonces, antes de seguir adelante, es importante conocer ambos lados para decidir si sería mejor para su organización o no.
Ventajas 👍
Estas son algunas de las ventajas de la arquitectura sin servidor:
Rentable
Serverless puede ofrecer una mayor rentabilidad que comprar o alquilar servidores en los que paga por los recursos, incluso si no los usa.
Serverless emplea un modelo de pago por uso en el que pagará solo por los recursos que consume. El proveedor sin servidor le cobrará solo por la memoria asignada y el tiempo para ejecutar el código sin incurrir en costos por tiempo de inactividad.
Como resultado, ahorrará en costos operativos para tareas como instalación, licencias, mantenimiento, parches, soporte, etc. Sin hardware de servidor, ahorra en costos de mano de obra.
Escalabilidad
Los sistemas sin servidor ofrecen un alto nivel de escalabilidad, ya que puede escalar hacia arriba o hacia abajo cuando lo desee según las demandas. También se les llama “elásticos” por este motivo.
Aquí, los desarrolladores no necesitan tiempo dedicado para configurar los sistemas o políticas de escalado automático o ajustarlos. El proveedor de la nube que elija es responsable de administrar todo eso. Además, los desarrolladores de equipos pequeños también pueden ejecutar su código por sí mismos sin necesidad de ingenieros de soporte o infraestructura.
latencia reducida
Como las aplicaciones no están alojadas en un único servidor de origen, puede ejecutar el código desde cualquier lugar. Si el proveedor de la nube que ha elegido lo admite, puede ejecutar las funciones de la aplicación en un servidor cercano a los usuarios finales. Por lo tanto, incurre en menos latencia debido a la distancia reducida entre las solicitudes del usuario y el servidor.
Productividad
El modelo sin servidor ayuda a mejorar la productividad de sus desarrolladores, ya que no tienen que manejar la administración del servidor. Además, no tienen que pensar en administrar solicitudes HTTP o subprocesos múltiples en su código directamente.
Como resultado, simplifica el desarrollo de back-end, todo gracias a FaaS, donde el código expuesto son funciones impulsadas por eventos. Todo esto ahorra el tiempo que pueden dedicar a mejorar el código y la aplicación.
Despliegue de aplicaciones más rápido
Con serverless, los desarrolladores no realizan la configuración de back-end ni cargan código en el servidor para implementar una versión de la aplicación. También pueden cargar rápidamente el código en bits para lanzar nuevos productos.
También tienen la flexibilidad de implementar código a la vez o funcionar uno tras otro, ya que no es una arquitectura monolítica. Además, puede parchear, actualizar, agregar funciones o corregir errores desde una aplicación rápidamente.
Otros beneficios incluyen la computación ecológica debido a la reducción del consumo de energía con servidores bajo demanda, la creación de una aplicación que se vuelve más fácil con integraciones integradas, un tiempo de comercialización más rápido y más.
Desventajas 👎
Ahora, veamos las desventajas de la computación sin servidor:
Actuación
A veces, el código sin servidor que se usa con menos frecuencia puede exhibir una mayor latencia de respuesta que los que se ejecutan continuamente en servidores dedicados, contenedores de software o máquinas virtuales (VM). Es porque puede necesitar más tiempo para comenzar de nuevo y crear una latencia adicional.
Difícil de depurar y probar
Necesita saber cómo funciona su código una vez que lo implementa. Para esto, debe probarlo, lo cual es un desafío en un entorno sin servidor. Además, como los desarrolladores carecen de visibilidad de cada proceso de back-end y las aplicaciones se dividen en funciones más pequeñas, la depuración se complica.
Temas de seguridad
Las preocupaciones de seguridad cibernética nuevas y avanzadas están creciendo. Pero no es posible conocer o medir completamente la seguridad del proveedor de la nube. Entonces, cuando manejan todo su backend con datos confidenciales almacenados en aplicaciones, es riesgoso.
No apto para procesos de aplicación de larga duración
Serverless es rentable, pero no para todos los tipos de aplicaciones. Si tiene una aplicación que tiene procesos de ejecución prolongados, el costo de ejecutarla en función del tiempo y los recursos asignados puede ser muy alto. En este momento, es posible que desee continuar con un alojamiento de servidor dedicado.
Otros inconvenientes de la tecnología sin servidor son la dificultad para cambiar de un proveedor a otro y los problemas de privacidad.
Terminologías importantes en la arquitectura sin servidor
Serverless nunca está completo sin hablar de algunas terminologías clave relacionadas con él. FaaS y BaaS son dos de las ideas más destacadas que llevaron a la evolución de serverless que conocemos hoy. Y para crear un sistema sin servidor, necesita una base de datos, un sistema de almacenamiento, una pila de tecnología, un marco, etc. Entonces, hablemos un poco sobre ellos.
Función como servicio (FaaS)
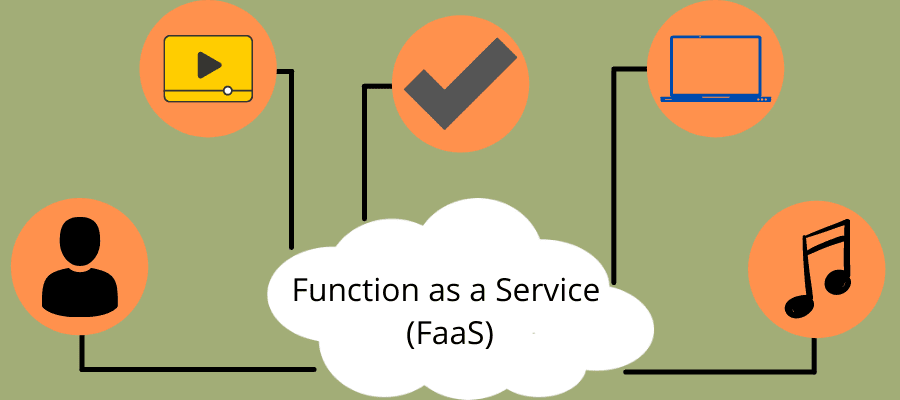
FaaS es una idea central en serverless y funciona como su subconjunto. Este modelo de ejecución de código basado en eventos (aplicaciones que se ejecutan en respuesta a una solicitud) le permite escribir lógica implementada en contenedores de software, ejecutada bajo demanda y una plataforma en la nube la administra.
Si lo compara con BaaS, FaaS ofrece más control a los desarrolladores para crear aplicaciones personalizadas en lugar de depender de bibliotecas que contienen código prefabricado.
Los contenedores de software donde se implementa el código no tienen estado para simplificar la integración de datos y el código se ejecuta durante menos tiempo. Además, los desarrolladores pueden invocar aplicaciones sin servidor a través de API utilizando FaaS que los proveedores de la nube administran a través de una API Gateway.
Back-end como servicio (BaaS)
BaaS es similar a FaaS porque ambos necesitan un proveedor de servicios externo. En este modelo, un proveedor de la nube proporciona servicios de back-end como almacenamiento de datos para ayudar a los desarrolladores a concentrarse en escribir su código de front-end. Sin embargo, es posible que las aplicaciones BaaS no estén basadas en eventos ni se ejecuten en el perímetro como las aplicaciones sin servidor.
Un buen ejemplo de BaaS es AWS Lambda. Los desarrolladores usan código sin servidor en contenedores con Lambda que proporciona pautas a seguir al enviar el código. También automatiza los procesos de ingreso del código a los contenedores de software y ofrece un servicio administrado.
pila sin servidor
Al igual que con otras tecnologías de software, la arquitectura sin servidor también viene con una pila de tecnología. Reúne varios componentes esenciales para crear un sistema o aplicación sin servidor.
La pila sin servidor incluye:
- Un lenguaje de programación: El lenguaje de programación en el que los desarrolladores escribirán el código. Según el proveedor, puede elegir entre Java, JavaScript, Python, C#, Go, Node.js, F#, etc.
- Un marco sin servidor: un marco proporciona el esqueleto o la estructura del código. Hay muchos marcos sin servidor para que pueda comenzar. Permite construir, empaquetar y compilar código y, finalmente, la implementación en la nube. Los marcos sin servidor aceleran el proceso de codificación y simplifican el escalado con un tiempo de configuración reducido. Ejemplos de marcos de servidor son Apex, AWS Serverless Application Model, etc.
- Bases de datos sin servidor: se utilizan para almacenar datos a los que el código requiere acceder. También son necesarios para interactuar con las funciones de los disparadores. Estas bases de datos se comportan como funciones sin servidor pero almacenan datos indefinidamente. Ejemplos de bases de datos sin servidor son DynamoDB, Azure Cosmos DB, Aurora Serverless y Cloud Firestore.
- Un conjunto de activadores: ayudan a iniciar la ejecución del código como solicitudes HTTP
- Contenedores de software: Potencian el modelo serverless y ofrecen microservicios en contenedores sin complejidad. También funcionan como un depósito para su código y facilitan a los desarrolladores mientras escriben el código para múltiples plataformas, como escritorio o iOS.
- Puertas de enlace API: funcionan como un proxy para las acciones web. Ofrecen enrutamiento HTTP, límites de velocidad, visualización del uso de API y registros de respuesta, ID de cliente, etc.
¿Cómo implementar el modelo sin servidor y optimizarlo?
Ir sin servidor implicará cambios significativos en términos de sus aplicaciones, tecnología, costos, seguridad y beneficios.
Supongamos que es una empresa nueva o una pequeña empresa. En ese caso, acelerará su tiempo de comercialización y lo ayudará a enviar actualizaciones rápidamente con pruebas simplificadas, depuración, recopilación de comentarios, trabajo en problemas y más para ofrecer una aplicación pulida a los usuarios.
Si es una organización más grande, experimentará beneficios como una mayor escalabilidad para satisfacer las demandas de sus usuarios, pero requerirá una inversión de costos significativa.
Por lo tanto, es mejor evaluar los pros y los contras de la tecnología sin servidor específicamente para el tipo y las demandas de su negocio y luego continuar. Y si lo dices en serio, empieza por:
- Comprender sus necesidades e identificar una pila de tecnología sin servidor adecuada
- Elija un proveedor sin servidor como Google Cloud Functions, Azure Functions, AWS Lambda, etc.
- Capacite a su equipo con herramientas poderosas para monitorear el rendimiento y las funciones del sistema. Tenga cuidado con la cantidad total de solicitudes, limitaciones, recuentos de errores, tasas de éxito, duración de las solicitudes y latencia.
Proveedores sin servidor

Hay muchos proveedores sin servidor o proveedores de nube en el mercado para que usted pueda elegir. Algunos de los principales son:
- AWS Lambda: es perfecto para organizaciones que ya aprovechan los servicios de AWS. Se integra con una amplia gama de servicios de almacenamiento, transmisión y bases de datos.
- Funciones de Microsoft Azure: si usa Visual Studio Code, hágalo. Funciona sin problemas con DevOps y Azure Pipelines para CI/CD. También es compatible con Durable Functions para funciones con estado y ofrece monitoreo integrado.
- Funciones de Google Cloud: si está utilizando los servicios de Google, es bueno. Admite aplicaciones JS, Go y Python, permite activar funciones desde el asistente de Google o GCP y ofrece escalado integrado.
- IBM Cloud Functions: si desea optar por un modelo sin servidor basado en Apache OpenWhisk, IBM Cloud Functions es para usted. Incluye una excelente supervisión del rendimiento, activación de eventos desde una API REST o servicios en la nube de IBM y se integra con API Gateway de IBM para gestionar puntos finales.
- Knative: si está ejecutando servicios en Kubernetes, hágalo. Está respaldado por Google, Red Hat, IBM, etc.
- Trabajadores de Cloudflare: es bueno para las aplicaciones que requieren una gran capacidad de respuesta, especialmente las aplicaciones de JavaScript. Admite Workers KV para el almacenamiento de datos y WebAssembly para ayudarlo a compilar y entregar varios idiomas. Además, su red de alta distribución con 193 centros de datos mejora la latencia y la capacidad de respuesta.
Conclusión: el futuro de Serverless
La informática sin servidor está evolucionando con la creciente demanda de aplicaciones altamente escalables. También brinda muchos beneficios que ofrece la computación en la nube, como más conveniencia, rentabilidad, mayor productividad y más.
Según un encuesta de O’Reillyel 40 % de los encuestados trabaja en empresas que han adoptado la arquitectura sin servidor.
Aunque la tecnología sin servidor todavía tiene ciertas preocupaciones, como la latencia debido a arranques en frío, pruebas, depuración, etc., los proveedores de la nube están trabajando en ello. Pronto, podría surgir una forma más refinada de serverless con más beneficios y problemas resueltos. Por lo tanto, se espera que la popularidad y el uso del modelo sin servidor aumenten en el futuro.
También te puede interesar: 7 formas en que la informática sin servidor es una tecnología en auge