
El procesamiento de big data es uno de los procedimientos más complejos a los que se enfrentan las organizaciones. El proceso se vuelve más complicado cuando tiene un gran volumen de datos en tiempo real.
En esta publicación, descubriremos qué es el procesamiento de big data, cómo se hace y exploraremos Apache Kafka y Spark, ¡las dos de las herramientas de procesamiento de datos más famosas!
Tabla de contenido
¿Qué es el procesamiento de datos? ¿Cómo se hace?
Se entiende por tratamiento de datos cualquier operación o conjunto de operaciones, se realice o no mediante un proceso automatizado. Puede pensarse como la recopilación, ordenación y organización de la información de acuerdo con una disposición lógica y apropiada para la interpretación.
Cuando un usuario accede a una base de datos y obtiene los resultados de su búsqueda, es el procesamiento de datos lo que les proporciona los resultados que necesitan. La información extraída como resultado de una búsqueda es el resultado del procesamiento de datos. Es por ello que la tecnología de la información tiene el foco de su existencia centrado en el procesamiento de datos.
El procesamiento de datos tradicional se llevó a cabo utilizando un software simple. Sin embargo, con la aparición de Big Data, las cosas han cambiado. Big Data se refiere a información cuyo volumen puede superar los cien terabytes y petabytes.
Además, esta información se actualiza periódicamente. Los ejemplos incluyen datos provenientes de centros de contacto, redes sociales, datos de operaciones bursátiles, etc. Dichos datos a veces también se denominan flujo de datos: un flujo de datos constante e incontrolado. Su principal característica es que los datos no tienen límites definidos, por lo que es imposible decir cuándo comienza o termina el flujo.
Los datos se procesan a medida que llegan al destino. Algunos autores lo llaman procesamiento en tiempo real o en línea. Un enfoque diferente es el procesamiento por bloques, por lotes o fuera de línea, en el que los bloques de datos se procesan en ventanas de tiempo de horas o días. A menudo, el lote es un proceso que se ejecuta por la noche y consolida los datos de ese día. Hay casos de ventanas de tiempo de una semana o incluso un mes generando informes desactualizados.
Dado que las mejores plataformas de procesamiento de Big Data vía streaming son de código abierto como Kafka y Spark, estas plataformas permiten el uso de otras diferentes y complementarias. Esto significa que al ser de código abierto, evolucionan más rápido y utilizan más herramientas. De esta manera, los flujos de datos se reciben desde otros lugares a una velocidad variable y sin interrupciones.
Ahora, veremos dos de las herramientas de procesamiento de datos más conocidas y las compararemos:
apache kafka
Apache Kafka es un sistema de mensajería que crea aplicaciones de transmisión con un flujo de datos continuo. Creado originalmente por LinkedIn, Kafka se basa en registros; un registro es una forma básica de almacenamiento porque cada nueva información se agrega al final del archivo.

Kafka es una de las mejores soluciones para big data porque su principal característica es su alto rendimiento. Con Apache Kafka, incluso es posible transformar el procesamiento por lotes en tiempo real,
Apache Kafka es un sistema de mensajería de publicación y suscripción en el que una aplicación publica y una aplicación que se suscribe recibe mensajes. El tiempo entre la publicación y la recepción del mensaje puede ser de milisegundos, por lo que una solución de Kafka tiene una latencia baja.
Trabajo de Kafka
La arquitectura de Apache Kafka comprende productores, consumidores y el propio clúster. El productor es cualquier aplicación que publica mensajes en el clúster. El consumidor es cualquier aplicación que recibe mensajes de Kafka. El clúster de Kafka es un conjunto de nodos que funcionan como una única instancia del servicio de mensajería.
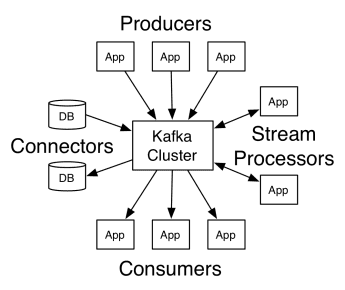 Trabajo de Kafka
Trabajo de Kafka
Un clúster de Kafka se compone de varios intermediarios. Un intermediario es un servidor Kafka que recibe mensajes de los productores y los escribe en el disco. Cada corredor gestiona una lista de temas, y cada tema se divide en varias particiones.
Después de recibir los mensajes, el corredor los envía a los consumidores registrados para cada tema.
La configuración de Apache Kafka es administrada por Apache Zookeeper, que almacena metadatos del clúster, como la ubicación de la partición, la lista de nombres, la lista de temas y los nodos disponibles. Así, Zookeeper mantiene la sincronización entre los diferentes elementos del clúster.
Zookeeper es importante porque Kafka es un sistema distribuido; es decir, la escritura y la lectura la realizan varios clientes simultáneamente. Cuando hay una falla, el Zookeeper elige un reemplazo y recupera la operación.
Casos de uso
Kafka se hizo popular, especialmente por su uso como herramienta de mensajería, pero su versatilidad va más allá y se puede usar en una variedad de escenarios, como en los ejemplos a continuación.
Mensajería
Forma de comunicación asíncrona que desacopla las partes que se comunican. En este modelo, una de las partes envía los datos como un mensaje a Kafka, para que otra aplicación los consuma más tarde.
Seguimiento de actividad
Le permite almacenar y procesar datos de seguimiento de la interacción de un usuario con un sitio web, como páginas vistas, clics, entrada de datos, etc.; este tipo de actividad suele generar un gran volumen de datos.
Métrica
Implica agregar datos y estadísticas de múltiples fuentes para generar un informe centralizado.
Agregación de registros
Agrega y almacena de forma centralizada los archivos de registro que se originan en otros sistemas.
Procesamiento de flujo
El procesamiento de canalizaciones de datos consta de varias etapas, en las que los datos sin procesar se consumen de los temas y se agregan, enriquecen o transforman en otros temas.
Para admitir estas funciones, la plataforma proporciona esencialmente tres API:
- API de flujos: actúa como un procesador de flujo que consume datos de un tema, los transforma y los escribe en otro.
- Connectors API: Permite conectar temas a sistemas existentes, como bases de datos relacionales.
- API de productor y consumidor: permite que las aplicaciones publiquen y consuman datos de Kafka.
ventajas
Replicado, particionado y ordenado
Los mensajes en Kafka se replican en las particiones de los nodos del clúster en el orden en que llegan para garantizar la seguridad y la velocidad de entrega.
Transformación de datos
Con Apache Kafka, incluso es posible transformar el procesamiento por lotes en tiempo real utilizando la API de secuencias ETL por lotes.
Acceso secuencial al disco
Apache Kafka conserva el mensaje en el disco y no en la memoria, ya que se supone que es más rápido. De hecho, el acceso a la memoria es más rápido en la mayoría de las situaciones, especialmente cuando se considera acceder a datos que se encuentran en ubicaciones aleatorias en la memoria. Sin embargo, Kafka tiene acceso secuencial y, en este caso, el disco es más eficiente.
chispa apache
Apache Spark es un motor informático de big data y un conjunto de bibliotecas para procesar datos paralelos en clústeres. Spark es una evolución de Hadoop y el paradigma de programación Map-Reduce. Puede ser 100 veces más rápido gracias a su uso eficiente de la memoria que no conserva los datos en los discos durante el procesamiento.
Spark se organiza en tres niveles:
- API de bajo nivel: este nivel contiene la funcionalidad básica para ejecutar trabajos y otras funciones requeridas por los otros componentes. Otras funciones importantes de esta capa son la gestión de la seguridad, la red, la programación y el acceso lógico a los sistemas de archivos HDFS, GlusterFS, Amazon S3 y otros.
- API estructuradas: el nivel de API estructurada se ocupa de la manipulación de datos a través de DataSets o DataFrames, que se pueden leer en formatos como Hive, Parquet, JSON y otros. Usando SparkSQL (API que nos permite escribir consultas en SQL), podemos manipular los datos de la forma que queramos.
- Alto nivel: en el nivel más alto, tenemos el ecosistema Spark con varias bibliotecas, incluidas Spark Streaming, Spark MLlib y Spark GraphX. Son responsables de cuidar la ingestión de transmisión y los procesos circundantes, como la recuperación de fallas, la creación y validación de modelos clásicos de aprendizaje automático y el manejo de gráficos y algoritmos.
Trabajo de chispa
La arquitectura de una aplicación Spark consta de tres partes principales:
Programa Driver: Es el encargado de orquestar la ejecución del procesamiento de datos.
Cluster Manager: Es el componente encargado de administrar las diferentes máquinas en un clúster. Solo es necesario si Spark se ejecuta distribuido.
Nodos trabajadores: Son las máquinas que realizan las tareas de un programa. Si Spark se ejecuta localmente en su máquina, jugará un programa de controlador y un rol de Workes. Esta forma de ejecutar Spark se llama Standalone.
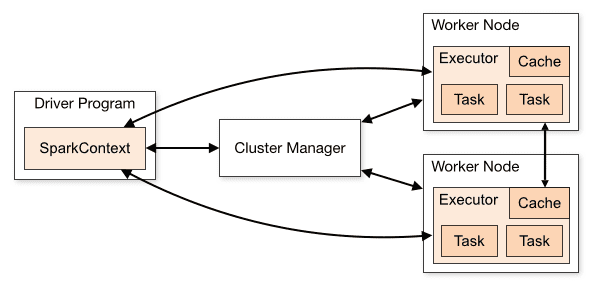 Descripción general del clúster
Descripción general del clúster
El código Spark se puede escribir en varios idiomas diferentes. La consola Spark, llamada Spark Shell, es interactiva para aprender y explorar datos.
La llamada aplicación Spark consta de uno o más trabajos, lo que permite admitir el procesamiento de datos a gran escala.
Cuando hablamos de ejecución, Spark tiene dos modos:
- Cliente: el controlador se ejecuta directamente en el cliente, que no pasa por el Administrador de recursos.
- Clúster: controlador que se ejecuta en el maestro de aplicaciones a través del administrador de recursos (en el modo de clúster, si el cliente se desconecta, la aplicación seguirá ejecutándose).
Es necesario utilizar Spark correctamente para que los servicios vinculados, como el Administrador de recursos, puedan identificar la necesidad de cada ejecución, brindando el mejor rendimiento. Así que le toca al desarrollador saber la mejor manera de ejecutar sus trabajos de Spark, estructurando la llamada realizada, y para ello, puede estructurar y configurar los ejecutores de Spark de la forma que desee.
Los trabajos de Spark utilizan principalmente la memoria, por lo que es común ajustar los valores de configuración de Spark para los ejecutores de nodos de trabajo. Según la carga de trabajo de Spark, es posible determinar que una determinada configuración de Spark no estándar proporciona ejecuciones más óptimas. Para ello, se pueden realizar pruebas comparativas entre las distintas opciones de configuración disponibles y la propia configuración por defecto de Spark.
Casos de uso
Apache Spark ayuda a procesar grandes cantidades de datos, ya sea en tiempo real o archivados, estructurados o no estructurados. Los siguientes son algunos de sus casos de uso populares.
Enriquecimiento de datos
A menudo, las empresas utilizan una combinación de datos históricos de clientes con datos de comportamiento en tiempo real. Spark puede ayudar a construir una canalización ETL continua para convertir datos de eventos no estructurados en datos estructurados.
Detección de eventos desencadenantes
Spark Streaming permite una rápida detección y respuesta a algún comportamiento raro o sospechoso que podría indicar un posible problema o fraude.
Análisis de datos de sesión compleja
Con Spark Streaming, los eventos relacionados con la sesión del usuario, como sus actividades después de iniciar sesión en la aplicación, se pueden agrupar y analizar. Esta información también se puede utilizar de forma continua para actualizar los modelos de aprendizaje automático.
ventajas
Procesamiento iterativo
Si la tarea es procesar datos repetidamente, los conjuntos de datos distribuidos (RDD) resistentes de Spark permiten múltiples operaciones de mapas en memoria sin tener que escribir resultados intermedios en el disco.
Procesamiento gráfico
El modelo computacional de Spark con GraphX API es excelente para los cálculos iterativos típicos del procesamiento de gráficos.
Aprendizaje automático
Spark tiene MLlib, una biblioteca de aprendizaje automático integrada que tiene algoritmos listos para usar que también se ejecutan en la memoria.
Kafka contra Spark
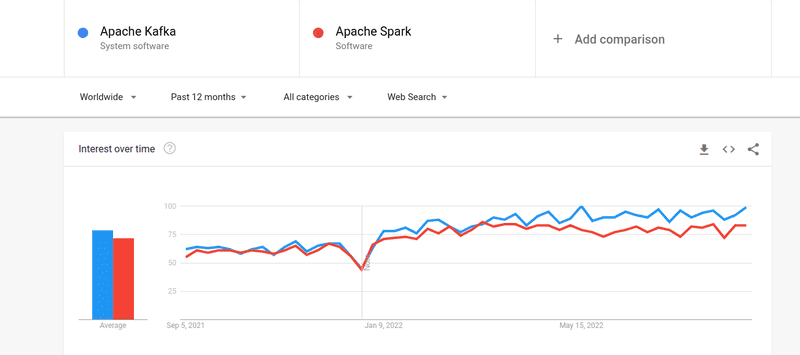
Aunque el interés de la gente por Kafka y Spark ha sido casi similar, existen algunas diferencias importantes entre los dos; echemos un vistazo.
#1. Procesamiento de datos
Kafka es una herramienta de almacenamiento y transmisión de datos en tiempo real responsable de transferir datos entre aplicaciones, pero no es suficiente para crear una solución completa. Por lo tanto, se necesitan otras herramientas para tareas que no hace Kafka, como Spark. Spark, por otro lado, es una plataforma de procesamiento de datos por lotes que extrae datos de los temas de Kafka y los transforma en esquemas combinados.
#2. Gestión de la memoria
Spark utiliza conjuntos de datos distribuidos robustos (RDD) para la gestión de la memoria. En lugar de tratar de procesar grandes conjuntos de datos, los distribuye en múltiples nodos en un clúster. Por el contrario, Kafka utiliza un acceso secuencial similar a HDFS y almacena datos en una memoria intermedia.
#3. Transformación ETL
Tanto Spark como Kafka admiten el proceso de transformación ETL, que copia registros de una base de datos a otra, generalmente de una base transaccional (OLTP) a una base analítica (OLAP). Sin embargo, a diferencia de Spark, que viene con una capacidad integrada para el proceso ETL, Kafka confía en la API de Streams para admitirlo.
#4. Persistencia de datos

El uso de RRD de Spark le permite almacenar los datos en múltiples ubicaciones para su uso posterior, mientras que en Kafka, debe definir los objetos del conjunto de datos en la configuración para conservar los datos.
#5. Dificultad
Spark es una solución completa y más fácil de aprender gracias a su compatibilidad con varios lenguajes de programación de alto nivel. Kafka depende de varias API diferentes y módulos de terceros, lo que puede dificultar el trabajo.
#6. Recuperación
Tanto Spark como Kafka ofrecen opciones de recuperación. Spark usa RRD, lo que le permite guardar datos continuamente y, si hay una falla en el clúster, se puede recuperar.

Kafka replica continuamente los datos dentro del clúster y la replicación entre los intermediarios, lo que le permite pasar a los diferentes intermediarios si se produce una falla.
Similitudes entre Spark y Kafka
Apache SparkApache KafkaOpenSourceOpenSourceCrear aplicación de transmisión de datosCrear aplicación de transmisión de datosAdmite procesamiento con estadoAdmite procesamiento con estadoAdmite SQLAdmite SQLSimilitudes entre Spark y Kafka
Ultimas palabras
Kafka y Spark son herramientas de código abierto escritas en Scala y Java, que le permiten crear aplicaciones de transmisión de datos en tiempo real. Tienen varias cosas en común, incluido el procesamiento con estado, la compatibilidad con SQL y ETL. Kafka y Spark también se pueden utilizar como herramientas complementarias para ayudar a resolver el problema de la complejidad de la transferencia de datos entre aplicaciones.