
Es hora de elegir la mejor opción de base de datos sin servidor que se adapte mejor a su aplicación moderna.
Serverless Database se diseñó específicamente para manejar cargas de trabajo impredecibles que pueden cambiar rápidamente. Como resultado, muchas organizaciones han adoptado la arquitectura sin servidor para crear arquitecturas modernas basadas en eventos. Esto ha visto un aumento en la popularidad dentro del ecosistema de tecnologías sin servidor.
Tabla de contenido
Introducción a la base de datos sin servidor
La informática sin servidor requiere una base de datos sin servidor. Estas bases de datos están diseñadas específicamente para manejar cargas de trabajo impredecibles que pueden cambiar rápidamente. ¿Y lo que es más?
Puede pagar solo por los recursos de la base de datos que utiliza por segundo. Además, las bases de datos en la nube como Amazon Aurora, que son compatibles con MySQL y PostgreSQL, se pueden administrar por completo y escalar hasta 64 TB.
Esta base de datos se puede crear eligiendo el tamaño de la instancia. Esto funciona bien cuando hay una carga de trabajo, una tasa de solicitudes y requisitos de procesamiento predecibles.
Puede ser difícil organizar la cantidad correcta de capacidad en los casos en que la carga de trabajo es impredecible y hay un gran volumen de solicitudes de solo unos minutos cada semana o un día. Sin embargo, puede que no sea la mejor opción pagarlo de forma continua.
Aquí es donde entra en juego la base de datos sin servidor.
Características de la base de datos sin servidor

Estas son las principales características de las bases de datos sin servidor:
- Acceso en tiempo real: el acceso a sus datos está disponible a un nivel excelente. Indexa automáticamente los datos y los pone a disposición de inmediato. Esto le permite consultar, leer, actualizar y agregar elementos a su base de datos sin servidor de manera constante. ¿Y lo que es más? Podrás acceder a él instantáneamente a través de funciones.
- Escalabilidad infinita: puede ampliar o reducir las bases de datos sin servidor en cualquier momento. Se encienden y apagan según las necesidades de la aplicación. Escalará las unidades informáticas (ACU en el caso de Aurora Serverless) para gestionar sus consultas, leer y escribir en el mismo grupo de datos. Esta automatización le permitirá ejecutar todas sus funciones simultáneamente y garantizar que sus datos permanezcan consistentes.
- Alta seguridad: las aplicaciones modernas pueden estar expuestas a audiencias maliciosas y no confiables a escala global. Garantiza que todas las aplicaciones que interactúan con la misma base de datos pasen el mismo protocolo de control de acceso. Reduce la superficie de ataque, que es un riesgo crucial para las empresas.
- Disponibilidad: la base de datos sin servidor le brinda la capacidad de reducir la latencia. Este enfoque permite que el usuario lea directamente los datos de las funciones basadas en eventos.
- Schemaless: Schemaless le permite manejar todas las salidas de datos de sus funciones. Es fácil integrar la base de datos sin servidor con sus funciones utilizando este enfoque de «manejar todo». Esta es una característica única en las bases de datos sin servidor.
Ahora exploremos algunas de las mejores bases de datos sin servidor para aplicaciones modernas.
Fauna
Fauna es una base de datos distribuida sin servidor. Fauna ofrece una flexibilidad extrema. Puede ajustar varios parámetros para satisfacer las necesidades de su proyecto. Fauna se puede utilizar como una base de datos relacional tradicional, basada en documentos, de valores clave o de gráficos. Puede crear un esquema o soltar los datos.
Es extremadamente versátil. Fauna se puede ejecutar en la nube, en las instalaciones o incrustado en nuestra aplicación. También ofrece las opciones de implementación más populares, como imágenes de máquinas o imágenes acoplables. Esta aplicación puede ejecutarse a velocidades muy altas y funciona bien con transacciones ACID.
amazona aurora
Amazon Aurora es un servicio de almacenamiento de datos relacionales al que se puede acceder desde la nube de Amazon. Este servicio es ampliamente utilizado para el almacenamiento de datos. Permite el almacenamiento de datos de baja latencia y basado en el valor.
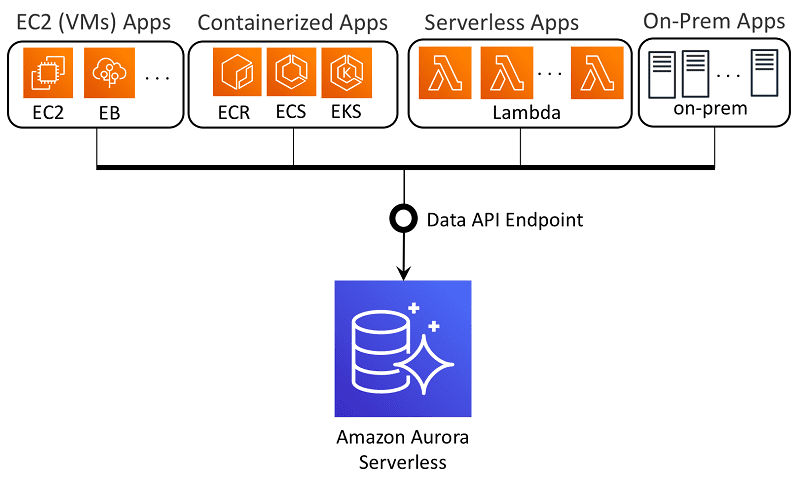 Crédito de la imagen: AWS
Crédito de la imagen: AWS
Amazon Aurora es una base de datos relacional compatible con PostgreSQL y MySQL que consolida la accesibilidad y el rendimiento de las bases de datos tradicionales con la confiabilidad y la simplicidad de las bases de datos comerciales a 1/10 del costo. Utiliza un enfoque agrupado para la replicación de datos en la zona de accesibilidad de AWS para una disponibilidad de datos eficiente.
Amazon Aurora tiene muchos subsistemas de alto rendimiento. Los motores MySQL y PostgreSQL utilizan el almacenamiento distribuido más rápido. Aurora acelera el rendimiento y el rendimiento de MySQL en 5 y 3 veces, respectivamente, en comparación con el sistema actual.
La base de datos se puede escalar hasta 64 terabytes, lo que brinda soporte para la implementación empresarial. Amazon Aurora está completamente administrado por Amazon Relational Database Service (RDS), que automatiza las tareas administrativas, como el aprovisionamiento de hardware, la organización de datos, la reparación, los refuerzos y más.
bit.io
bit.io le permite configurar rápida y fácilmente una base de datos PostgreSQL. Arrastre y suelte archivos para cargar datos en una base de datos PostgreSQL. También puede ingresar una URL para un archivo, enviar datos desde R o Python, o usar cualquier otro cliente de Postgres/HTTP.
El editor de SQL en el navegador le permite trabajar con los datos utilizando cualquiera de sus herramientas de análisis de datos favoritas, incluidos los clientes de SQL, los cuadernos de R y Python, la línea de comandos y muchos más.
bit.io proporciona una base de datos PostgreSQL con todas las funciones. Se puede utilizar rápidamente y prácticamente sin configuración. También se integra con un número creciente de herramientas de datos. bit.io funcionará con cualquier herramienta que admita PostgreSQL.
upstash
Upstash, una base de datos en la nube de memoria sin servidor creada por Upstash Inc (una empresa con sede en California). Se puede utilizar como capa de almacenamiento en caché o como base de datos. No requiere que administre clústeres o servidores de bases de datos. Es completamente sin servidor.
Es por eso que las tecnologías Serverless como Upstash son tan útiles. Upstash no cobra nada si no lo usas. Upstash se puede usar para casos de uso populares de Redis como:
- Almacenamiento en caché general
- Almacenamiento en caché de sesión
- Tablas de clasificación
- Colas
- Medición de uso (recuento)
- Filtrado de contenido
Características
- Diseñado para sin servidor
- Paga sobre la marcha
- Baja latencia
- Almacenamiento duradero y rápido
Xata
Xata, una base de datos sin servidor, tiene potentes funciones de búsqueda y análisis integradas. Xata utiliza un modelo de base de datos relacional con un esquema estricto (esquema) y admite objetos similares a JSON. Los registros se organizan en tablas que luego se agrupan en bases de datos.
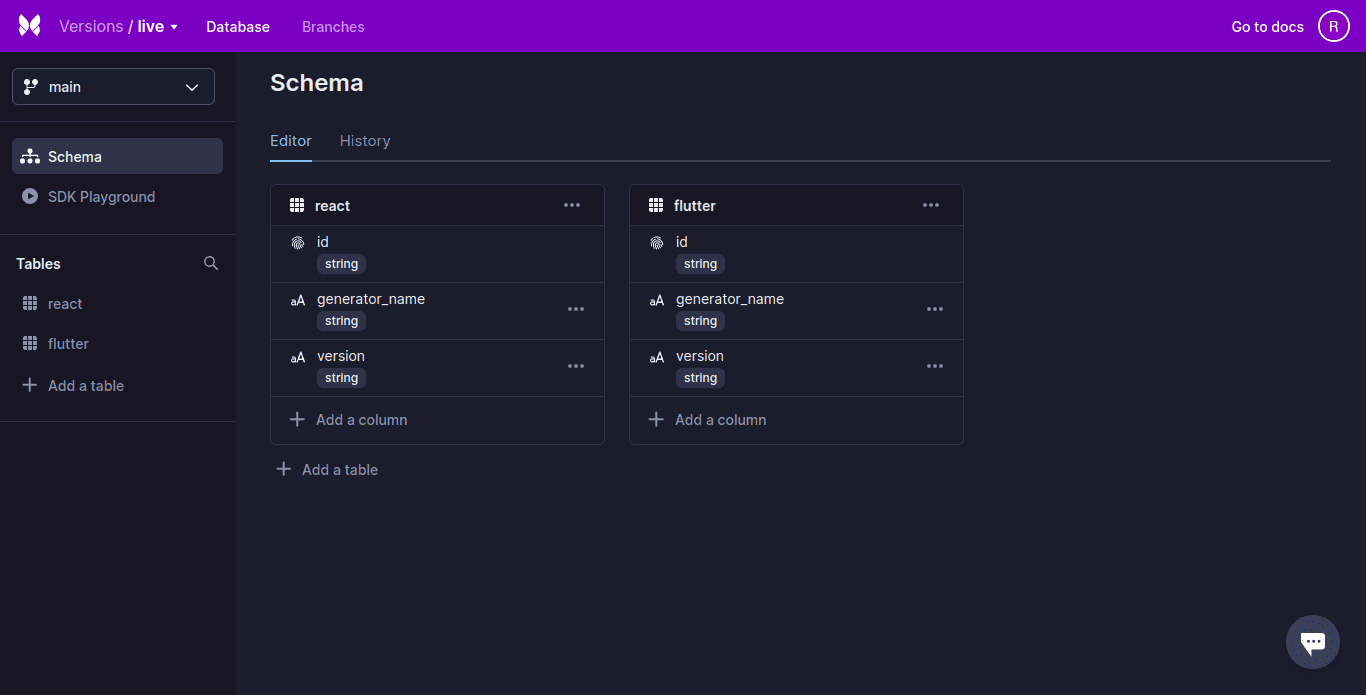
Xata admite columnas enriquecidas y las relaciones entre tablas se pueden representar mediante columnas de enlace. Estos son similares a la clave externa.
Xata, un nuevo tipo de servicio en la nube, ofrece una capa de abstracción sobre múltiples almacenes de datos para simplificar el desarrollo y la operación de aplicaciones. Este tipo de servicio se denomina Plataforma de datos sin servidor. Este documento puede usarse para ayudarte a replicar la arquitectura, lo que te dará algunas de las ventajas de usar Xata.
SurrealDB
SurrealDB, una base de datos en la nube NewSQL que es innovadora, se puede utilizar para aplicaciones sin servidor, jamstack, de una sola página, tradicionales y sin servidor. Ofrece una flexibilidad y un valor financiero incomparables. Se puede implementar en entornos informáticos locales, integrados o perimetrales, además de poder implementarse en la nube.
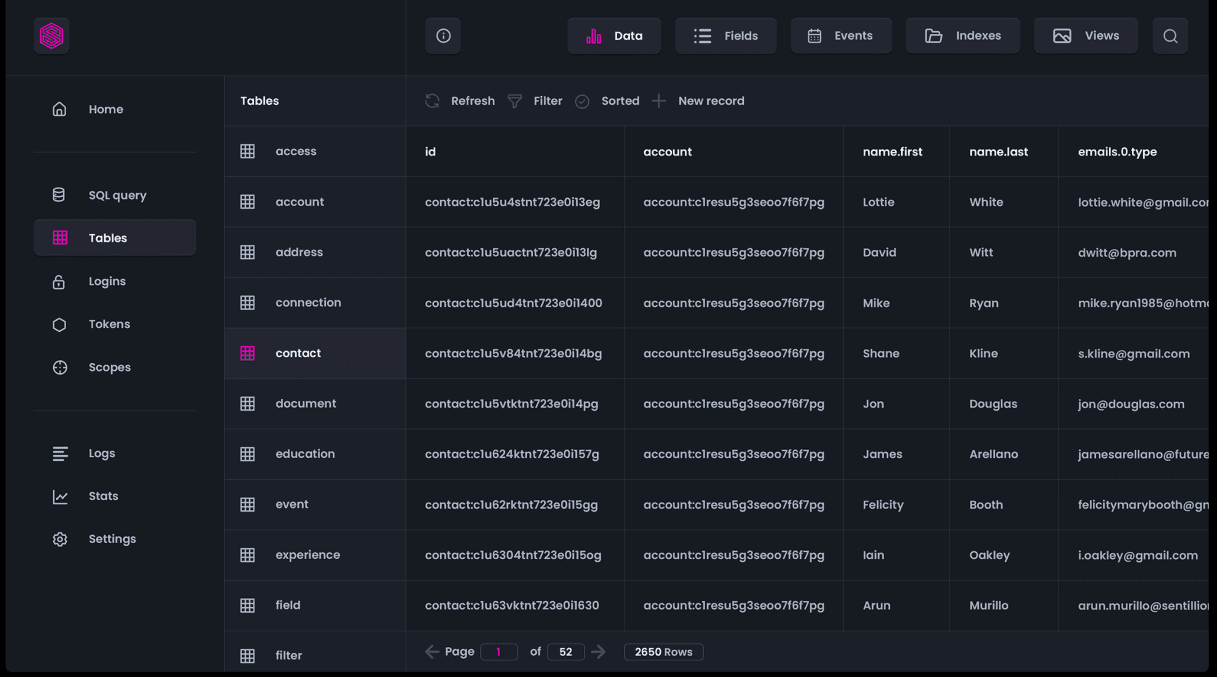
Su equipo no necesita dominar lenguajes de base de datos complejos. La funcionalidad avanzada también es simple y directa, pero sigue siendo rápida y eficaz. Puede olvidarse de escalar servidores, bases de datos, balanceadores de carga y puntos finales de API.
SurrealDB elimina la complejidad de su pila y le permite escalar con una plataforma distribuida y de alta disponibilidad. SurrealDB Cloud le permite implementar en cualquier lugar.
Cosmos DB
Azure Cosmos DB, una base de datos distribuida global basada en JSON, está disponible como ‘Plataforma como servicio (PaaS) en Microsoft Azure. Permite a los usuarios crear y distribuir automáticamente aplicaciones en los centros de datos de Azure sin configuración.
Es parte de Azure y está disponible en todas las regiones. También replica datos a través de múltiples centros de datos en la red.
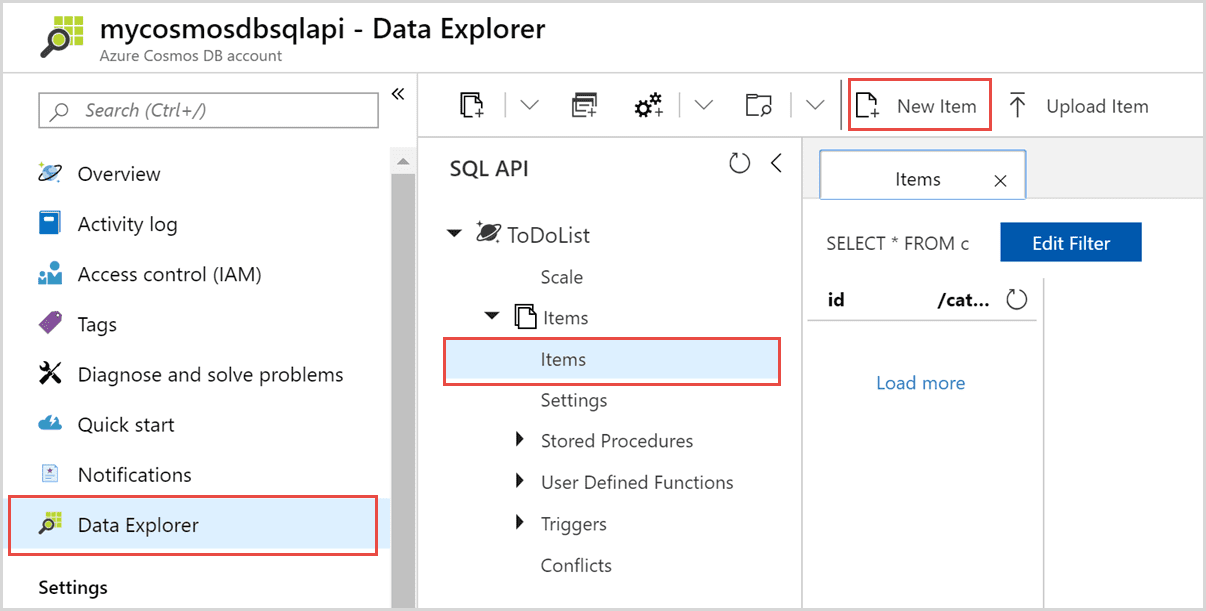
Hay muchas interfaces disponibles, siendo la más interesante la basada en SQL. CosmosDB es el servicio ideal para las organizaciones que procesan, consultan y administran muchas piezas de información importantes y de corta duración.
CucarachaDB
CockroachDB, una base de datos SQL distribuida construida sobre una clave-valor consistente y un almacén transaccional, se llama CockroachDB.
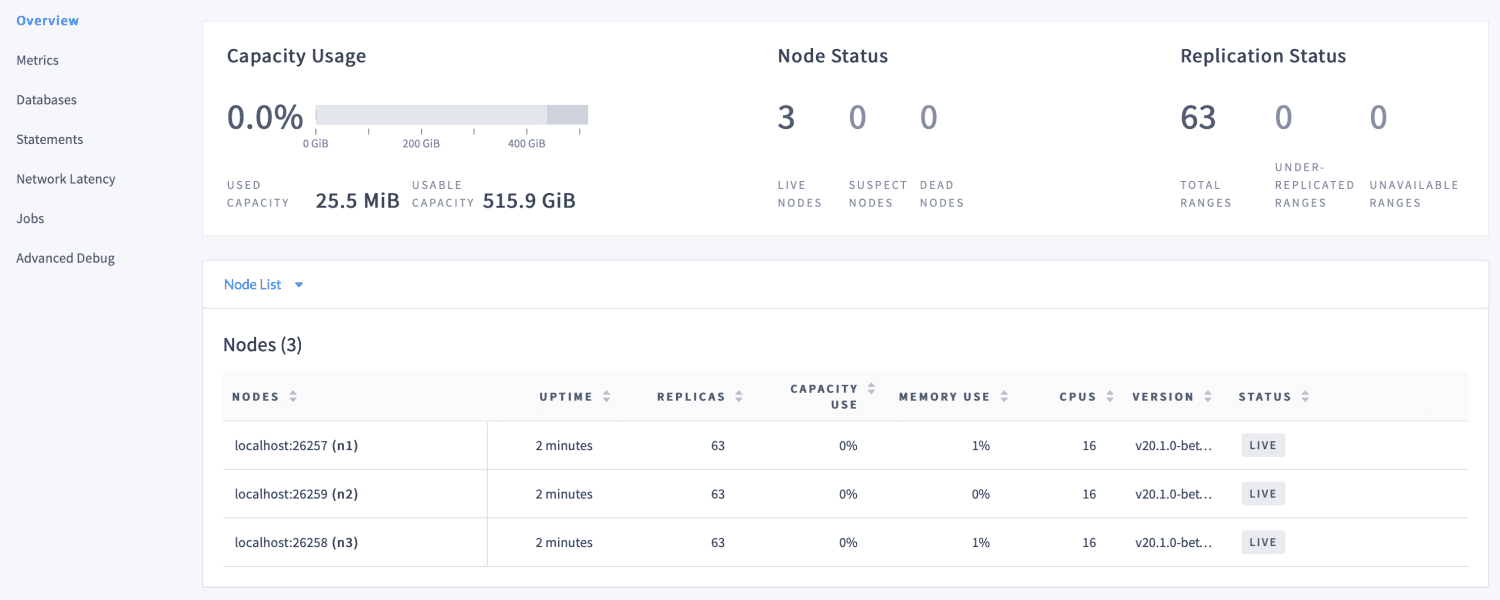
Está escrito en Go y es totalmente de código abierto. Sus objetivos principales incluyen el soporte de transacciones ACID, escalado horizontal y capacidad de supervivencia. Su objetivo es tolerar cualquier cosa, desde una falla de un solo disco hasta una operación completa de recuperación ante desastres, sin ninguna intervención manual y con una mínima interrupción de la latencia.
CockroachDB es una buena opción para aplicaciones que necesitan datos confiables, precisos y disponibles en todas las escalas. Puede acceder a la interfaz de usuario de administración, que viene en un paquete con CockroachDB en http://localhost:8080 tan pronto como el clúster esté en funcionamiento.
Proporciona información sobre la configuración del clúster y la base de datos y nos ayuda a optimizar el rendimiento del clúster al monitorear métricas como el estado, las métricas de tiempo de ejecución, la replicación y los detalles de los nodos.
PlanetaEscala
PlanetScale, una nueva plataforma DBaaS, le permite activar rápidamente una base de datos sin ninguna administración de conexión. Las bases de datos de PlanetScale se diseñaron para los desarrolladores y sus flujos de trabajo. Puede implementar una base de datos completamente administrada que tenga la confiabilidad y flexibilidad de MySQL. Sus bases de datos están construidas sobre MySQL 8.0.
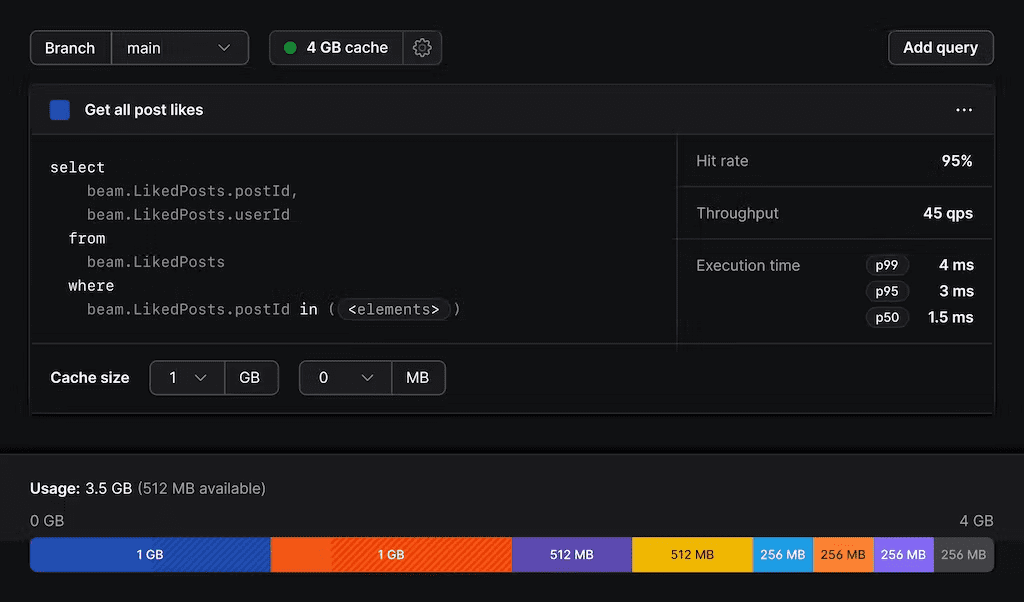
PlanetScale ofrece dos tipos de ramas de bases de datos: producción y desarrollo. Su función de bifurcación le permite tratar sus bases de datos como código. Puede crear una rama a partir de su esquema de base de datos de producción que se utilizará para entornos de desarrollo aislados.
Conclusión
Eso fue todo sobre las mejores bases de datos sin servidor para aplicaciones modernas. Las bases de datos sin servidor, y especialmente Amazon Aurora Serverless, son un futuro prometedor. Porque ahora podemos centrarnos en lo esencial del acceso en tiempo real a los datos, la escalabilidad y la seguridad con esta nueva tecnología.
También te pueden interesar las 7 formas en que la informática sin servidor es una tecnología en auge.