Este artículo menciona y expone algunas de las mejores bibliotecas de Python para los científicos de datos y el equipo de aprendizaje automático.
Python es un lenguaje ideal utilizado en estos dos campos principalmente por las bibliotecas que ofrece.
Esto se debe a las aplicaciones de las bibliotecas de Python, como la E/S de entrada/salida de datos y el análisis de datos, entre otras operaciones de manipulación de datos que los científicos de datos y los expertos en aprendizaje automático utilizan para manejar y explorar datos.
Tabla de contenido
Bibliotecas de Python, ¿qué son?
Una biblioteca de Python es una amplia colección de módulos integrados que contienen código precompilado, incluidas clases y métodos, lo que elimina la necesidad de que el desarrollador implemente el código desde cero.
Importancia de Python en la ciencia de datos y el aprendizaje automático
Python tiene las mejores bibliotecas para que las usen los expertos en aprendizaje automático y ciencia de datos.
Su sintaxis es fácil, lo que lo hace eficiente para implementar algoritmos complejos de aprendizaje automático. Además, la sintaxis simple acorta la curva de aprendizaje y facilita la comprensión.
Python también admite el desarrollo rápido de prototipos y la prueba fluida de aplicaciones.
La gran comunidad de Python es útil para que los científicos de datos busquen fácilmente soluciones a sus consultas cuando sea necesario.
¿Qué tan útiles son las bibliotecas de Python?
Las bibliotecas de Python son fundamentales para crear aplicaciones y modelos en aprendizaje automático y ciencia de datos.
Estas bibliotecas contribuyen en gran medida a ayudar al desarrollador con la reutilización del código. Por lo tanto, puede importar una biblioteca relevante que implemente una función específica dentro de su programa que no sea reinventar la rueda.
Bibliotecas de Python utilizadas en aprendizaje automático y ciencia de datos
Los expertos en ciencia de datos recomiendan varias bibliotecas de Python con las que los entusiastas de la ciencia de datos deben estar familiarizados. Según su relevancia en la aplicación, los expertos en aprendizaje automático y ciencia de datos aplican diferentes bibliotecas de Python clasificadas en bibliotecas para implementar modelos, extraer y raspar datos, procesar datos y visualizar datos.
Este artículo identifica algunas bibliotecas de Python de uso común en ciencia de datos y aprendizaje automático.
Veámoslos ahora.
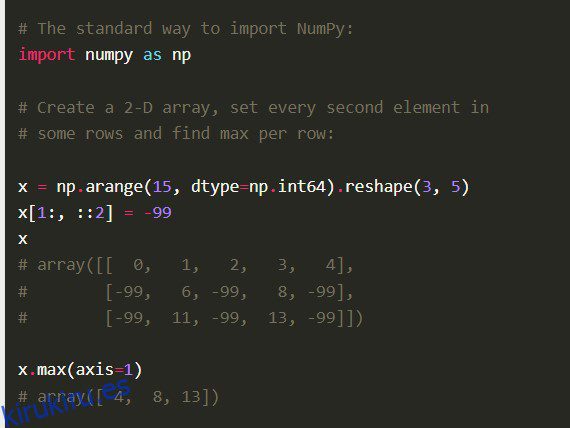
entumecido
La biblioteca Numpy Python, también Numerical Python Code en su totalidad, está construida con código C bien optimizado. Los científicos de datos lo prefieren por sus profundos cálculos matemáticos y cálculos científicos.
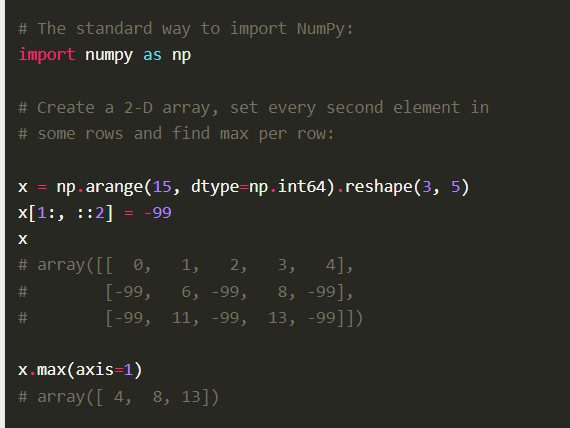
Características
Numpy viene con otras características integrales como la vectorización de operaciones matemáticas, indexación y conceptos clave en la implementación de arreglos y matrices.
pandas
Pandas es una biblioteca famosa en Machine Learning que proporciona estructuras de datos de alto nivel y numerosas herramientas para analizar conjuntos de datos masivos sin esfuerzo y de manera efectiva. Con muy pocos comandos, esta biblioteca puede traducir operaciones complejas con datos.
Numerosos métodos incorporados que pueden agrupar, indexar, recuperar, dividir, reestructurar datos y filtrar conjuntos antes de insertarlos en tablas unidimensionales y multidimensionales; compone esta biblioteca.
Características principales de la biblioteca Pandas
Es altamente eficiente por su buena funcionalidad de análisis de datos y alta flexibilidad.
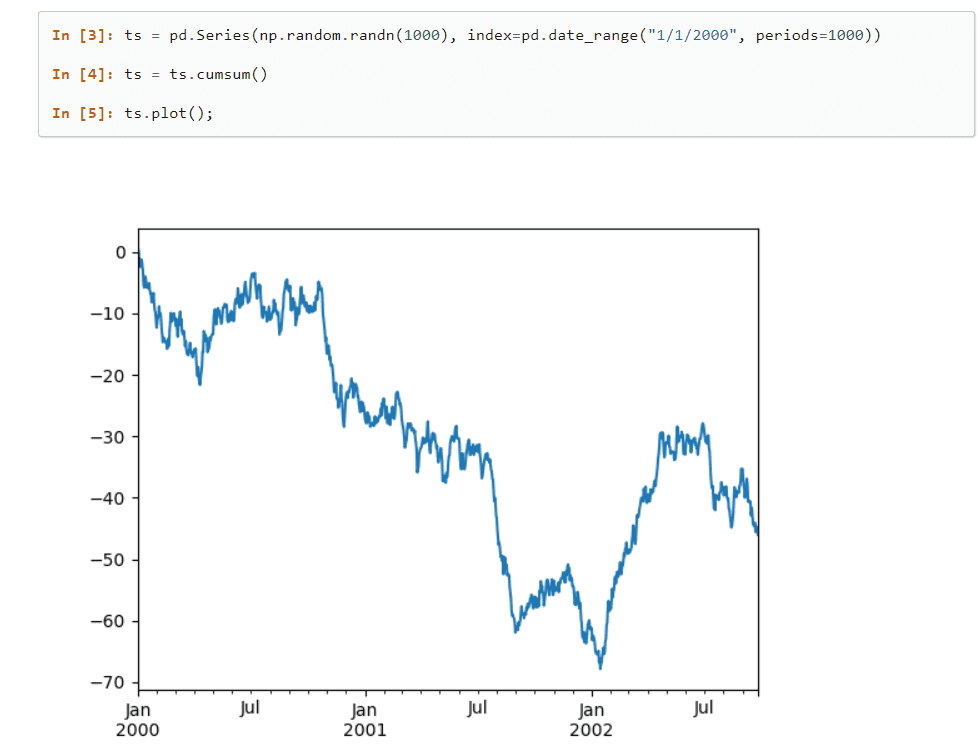
matplotlib
La biblioteca Python gráfica 2D de Matplotlib puede manejar fácilmente datos de numerosas fuentes. Las visualizaciones que crea son estáticas, animadas e interactivas y el usuario puede ampliarlas, lo que lo hace eficiente para las visualizaciones y la creación de gráficos. También permite la personalización del diseño y el estilo visual.
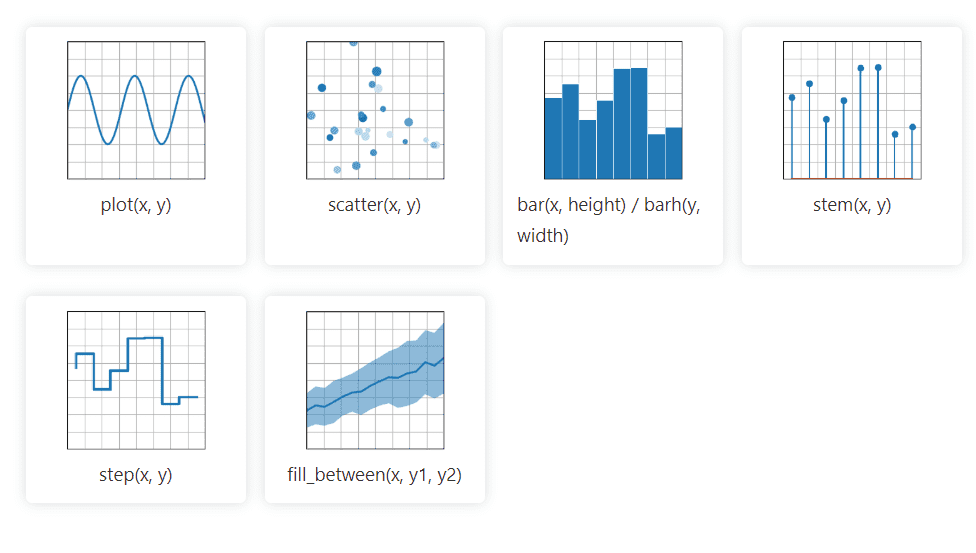
Su documentación es de código abierto y ofrece una colección profunda de herramientas necesarias para la implementación.
Matplotlib importa clases auxiliares para implementar el año, el mes, el día y la semana, lo que facilita la manipulación de datos de series temporales.
Scikit-aprender
Si está considerando una biblioteca que lo ayude a trabajar con datos complejos, Scikit-learn debería ser su biblioteca ideal. Los expertos en aprendizaje automático utilizan ampliamente Scikit-learn. La biblioteca está asociada con otras bibliotecas como NumPy, SciPy y matplotlib. Ofrece algoritmos de aprendizaje tanto supervisados como no supervisados que se pueden utilizar para aplicaciones de producción.

Características de la biblioteca Scikit-learn Python
La biblioteca Scikit-learn es eficiente en la extracción de características de conjuntos de datos de texto e imágenes. Además, es posible verificar la precisión de los modelos supervisados en datos no vistos. Sus numerosos algoritmos disponibles hacen posible la minería de datos y otras tareas de aprendizaje automático.
SciPy
SciPy (Scientific Python Code) es una biblioteca de aprendizaje automático que proporciona módulos aplicados a funciones y algoritmos matemáticos que son ampliamente aplicables. Sus algoritmos resuelven ecuaciones algebraicas, interpolación, optimización, estadística e integración.
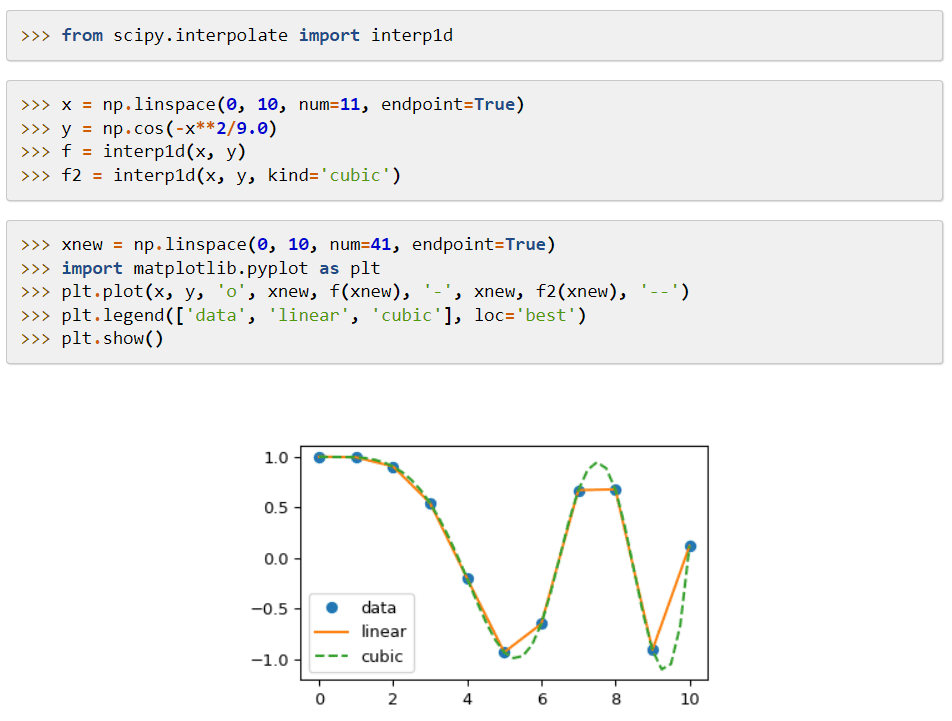
Su característica principal es su extensión a NumPy, que agrega herramientas para resolver las funciones matemáticas y proporciona estructuras de datos como matrices dispersas.
SciPy utiliza clases y comandos de alto nivel para manipular y visualizar datos. Sus sistemas de procesamiento de datos y prototipos lo convierten en una herramienta aún más efectiva.
Además, la sintaxis de alto nivel de SciPy hace que sea fácil de usar para los programadores de cualquier nivel de experiencia.
La única desventaja de SciPy es su único enfoque en objetos numéricos y algoritmos; por lo tanto, no puede ofrecer ninguna función de trazado.
PyTorch
Esta diversa biblioteca de aprendizaje automático implementa eficientemente cálculos de tensor con aceleración de GPU, creando gráficos computacionales dinámicos y cálculos de gradientes automáticos. La biblioteca Torch, una biblioteca de aprendizaje automático de código abierto desarrollada en C, crea la biblioteca PyTorch.

Las características clave incluyen:
Puede usar PyTorch en el desarrollo de aplicaciones NLP.
Keras
Keras es una biblioteca Python de aprendizaje automático de código abierto que se utiliza para experimentar con redes neuronales profundas.
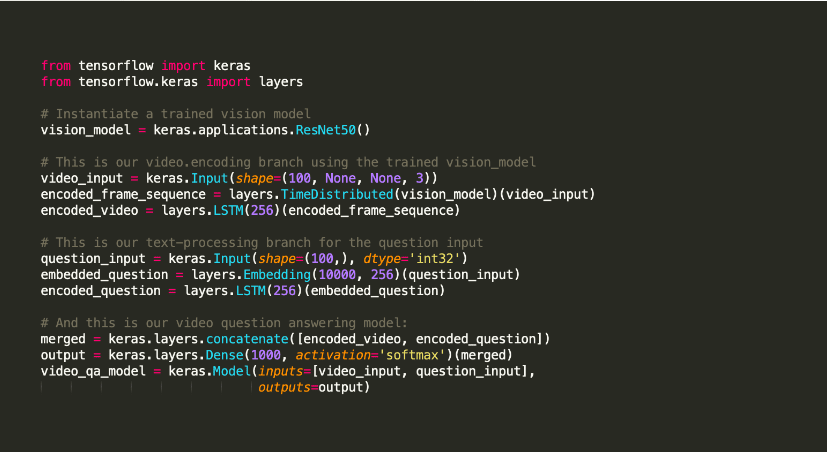
Es famoso por ofrecer utilidades que soportan tareas como compilación de modelos y visualización de gráficos, entre otras. Aplica Tensorflow para su backend. Alternativamente, puede usar Theano o redes neuronales como CNTK en el backend. Esta infraestructura de back-end lo ayuda a crear gráficos computacionales utilizados para implementar operaciones.
Características clave de la biblioteca
Las aplicaciones de Keras incluyen bloques de construcción de redes neuronales como capas y objetivos, entre otras herramientas que facilitan el trabajo con imágenes y datos de texto.
nacido en el mar
Seaborn es otra herramienta valiosa en la visualización de datos estadísticos.
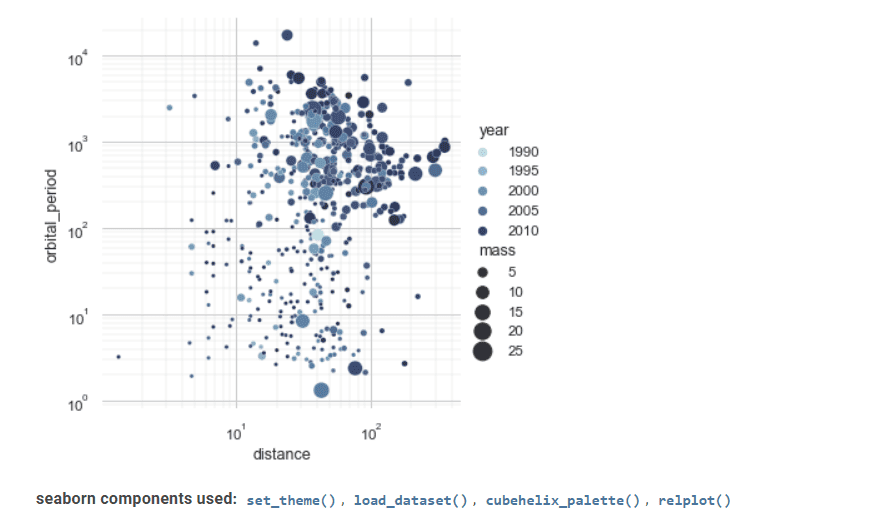
Su interfaz avanzada puede implementar dibujos gráficos estadísticos atractivos e informativos.
trama
Plotly es una herramienta de visualización 3D basada en la web construida sobre la biblioteca Plotly JS. Tiene un amplio soporte para varios tipos de gráficos, como gráficos de líneas, diagramas de dispersión y minigráficos de tipos de cuadros.
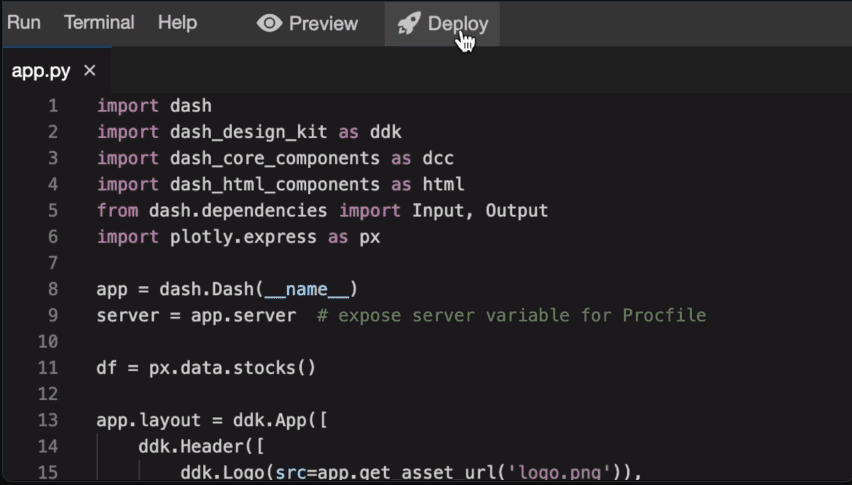
Su aplicación incluye la creación de visualizaciones de datos basadas en la web en cuadernos Jupyter.
Plotly es adecuado para la visualización porque puede señalar valores atípicos o anomalías en el gráfico con su herramienta de desplazamiento. También puede personalizar los gráficos para que se ajusten a sus preferencias.
La desventaja de Plotly es que su documentación está desactualizada; por lo tanto, usarlo como guía puede ser difícil para el usuario. Además, tiene numerosas herramientas que el usuario debe aprender. Puede ser un desafío hacer un seguimiento de todos ellos.
Características de la biblioteca de Plotly Python
SimpleITK
SimpleITK es una biblioteca de análisis de imágenes que ofrece una interfaz para Insight Toolkit (ITK). Está basado en C++ y es de código abierto.
Características de la biblioteca SimpleITK
Su interfaz simplificada está disponible en varios lenguajes de programación como R, C#, C++, Java y Python.
Modelo de estadísticas
Statsmodel estima modelos estadísticos, implementa pruebas estadísticas y explora datos estadísticos usando clases y funciones.
La especificación de modelos utiliza fórmulas de estilo R, matrices NumPy y marcos de datos de Pandas.
raspado
Este paquete de código abierto es una herramienta preferida para recuperar (raspar) y rastrear datos de un sitio web. Es asíncrono y, por lo tanto, relativamente rápido. Scrapy tiene una arquitectura y características que lo hacen eficiente.
En el lado negativo, su instalación difiere para diferentes sistemas operativos. Además, no puede usarlo en sitios web creados en JS. Además, solo puede funcionar con Python 2.7 o versiones posteriores.
Los expertos en ciencia de datos lo aplican en minería de datos y pruebas automatizadas.
Características
Almohada
Pillow es una biblioteca de imágenes de Python que manipula y procesa imágenes.
Se suma a las funciones de procesamiento de imágenes del intérprete de Python, admite varios formatos de archivo y ofrece una excelente representación interna.
Se puede acceder fácilmente a los datos almacenados en formatos de archivo básicos gracias a Pillow.
Terminando💃
Eso resume nuestra exploración de algunas de las mejores bibliotecas de Python para científicos de datos y expertos en aprendizaje automático.
Como muestra este artículo, Python tiene paquetes de ciencia de datos y aprendizaje automático más útiles. Python tiene otras bibliotecas que puede aplicar en otras áreas.
Es posible que desee conocer algunos de los mejores cuadernos de ciencia de datos.
¡Feliz aprendizaje!