Amazon Glue está ganando popularidad porque muchas empresas han comenzado a utilizar servicios de integración de datos administrados.
ETL es un proceso que transfiere datos desde una base de datos de origen a un almacén de datos. ETL es complejo y difícil de implementar para todos los datos empresariales debido a su complejidad. Amazon introdujo AWS Glue para abordar este problema.
Los desarrolladores de ETL y los ingenieros de datos usan Glue para crear, monitorear y ejecutar flujos de trabajo de ETL.
Tabla de contenido
¿Qué es AWS Glue?
AWS Glue, un servicio de integración de datos sin servidor, facilita la búsqueda, preparación, movimiento e integración de datos de múltiples fuentes. Esto es útil para el aprendizaje automático (ML) y el análisis.
Reduce drásticamente el tiempo requerido para preparar los datos para el análisis. Encuentra y enumera automáticamente los datos, genera código Scala o Python para transmitir los datos desde la fuente y carga y transforma el trabajo de acuerdo con los eventos cronometrados.
Esto permite una programación flexible y crea un entorno de Apache Spark que se puede escalar para la carga de datos específicos. Además, AWS Glue proporciona monitoreo y alteración de flujos de datos complejos. AWS Glue es un servicio sin servidor que simplifica las operaciones complicadas del desarrollo de aplicaciones.
Permite la integración rápida de múltiples datos válidos. También desglosa y autoriza datos rápidamente.
¿Para qué se utiliza AWS Glue?
Es importante conocer los mejores lugares para usar Amazon Glue. Estos son solo algunos ejemplos de los usos de AWS Glue que debe considerar.
- Glue es una herramienta que le permite ejecutar consultas sin servidor en los lagos de datos de Amazon S3. Amazon Glue es una gran herramienta para comenzar. Hace que todos sus datos sean accesibles en una sola interfaz, lo que le permite analizarlos sin tener que moverlos.
- Amazon Glue se puede utilizar para comprender sus activos de datos. Amazon Glue le facilita la búsqueda de diferentes conjuntos de datos de AWS mediante el catálogo de datos. También puede guardar datos en varios servicios de AWS utilizando el Catálogo de datos sin dejar de tener una vista uniforme.
- Glue puede ser útil al crear flujos de trabajo de ETL basados en eventos. Puede ejecutar sus operaciones ETL desde Amazon S3 llamando a sus tareas ETL de Glue a través de un servicio AWS Lambda.
- AWS Glue también se puede utilizar para limpiar, verificar, formatear y organizar datos para su almacenamiento en un lago de datos o almacén.
¿Cuáles son los componentes de AWS Glue?
A continuación se muestran los componentes principales de AWS Glue:
- Catálogo de datos: este catálogo de datos contiene metadatos y la estructura de datos.
- Base de datos: esta es la clave para acceder y crear la base de datos para orígenes y destinos.
- Tabla: cree una o varias tablas en la base de datos que puedan utilizar tanto el destino como el origen.
- Rastreador y clasificador: el rastreador recupera datos del origen mediante clasificaciones integradas o personalizadas. Crea/utiliza tablas de metadatos predefinidas en el catálogo de datos.
- Trabajo: Este es el trabajo de la lógica empresarial para realizar una tarea ETL. Apache Spark escribe internamente esta lógica empresarial utilizando los lenguajes python y scala.
- Disparador: un disparador ETL es un dispositivo que inicia la ejecución de un trabajo ETL bajo demanda o en un momento determinado.
- Endpoint para desarrollo: esto crea un entorno en el que se prueba, desarrolla y depura el script de trabajo de ETL.
Beneficios de AWS Glue
Estos son los beneficios de usarlo en su lugar de trabajo o dentro de una organización.
- AWS Glue escanea todos los datos disponibles con un rastreador.
- Los datos procesados finales se pueden almacenar en muchos lugares (Amazon RDS y Amazon Redshift, Amazon S3, etc.
- Es un servicio basado en la nube. No hay necesidad de gastar dinero en infraestructuras locales.
- Debido a que es un ETL sin servidor, es una opción rentable.
- Es rápido. Inmediatamente le proporciona el código ETL de Python/Scala.
¿Características principales de AWS Glue?
Amazon Glue tiene todas las funciones que necesita para integrar datos para que pueda obtener mejores perspectivas y utilizar su conocimiento para hacer nuevos avances en minutos en lugar de meses. Estas son algunas de las características que debe conocer.
- Interfaz de arrastrar y soltar: un editor de trabajos de arrastrar y soltar le permite crear un proceso ETL. AWS Glue creará inmediatamente el código necesario para extraer, convertir y cargar los datos.
- Descubrimiento automático de esquemas: para crear rastreadores que se conecten a diferentes fuentes de datos, puede usar el servicio Glue. Organiza datos y extrae información relevante. Estos datos se pueden usar para monitorear los procesos de ETL mediante tareas de ETL.
- Programación de trabajos: el pegamento se puede usar a pedido o de acuerdo con un cronograma programado. El programador se puede usar para construir canalizaciones ETL complejas, estableciendo dependencias entre tareas.
- Generación de código: Glue Elastic Views le permite crear fácilmente vistas materializadas que combinan y replican datos de diferentes fuentes de datos sin tener que escribir ningún código propietario.
- Aprendizaje automático integrado: Glue viene con una función de aprendizaje automático integrada llamada «FindMatches». Deduplica los registros que no son copias perfectas entre sí.
- Puntos finales de desarrollador: si desea desarrollar activamente su código ETL, Glue proporciona puntos finales de desarrollador que le permiten modificar, depurar y probar el código que crea.
- Glue DataBrew: es una herramienta de preparación de datos que pueden usar los analistas de datos y los científicos de datos para ayudarlos a limpiar y normalizar los datos. Utiliza la interfaz activa y visual de Glue DataBrew.
¿Cómo funcionan los precios de AWS Glue?
AWS Glue cobra una tarifa por hora, que se factura por segundo para los rastreadores (que descubren los datos) y los trabajos de ETL (que procesan y cargan los datos). Se cobra una tarifa mensual simple por acceder y almacenar metadatos en AWS Glue Data Catalog.
Amazon Glue comienza en $ 0.44. Puedes elegir entre cuatro planes:
- Las tareas de ETL, los puntos finales de desarrollo y otras tareas de ETL están disponibles a $0.44
- Las sesiones interactivas de Crawlers están disponibles a $0.44
- Los trabajos de DataBrew comienzan en $0.48
- El almacenamiento mensual y las solicitudes al catálogo de datos cuestan $ 1.00
AWS no ofrece un plan Glue gratuito. Cada hora costará $0.44 por DPU. En promedio, le costaría $ 21 por día. Los precios pueden variar según el lugar donde vivas.
Pasos para configurar AWS Glue
El catálogo de datos se puede utilizar para encontrar y buscar rápidamente varios conjuntos de datos de AWS sin tener que mover los datos. Una vez catalogados los datos, están disponibles de inmediato para realizar consultas y búsquedas mediante Amazon Athena y Amazon EMR.
Referencia: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS y bases de datos en Amazon EC2: descubra sus datos, almacene metadatos y use AWS Glue Data Catalog para descubrirlos
- AWS Glue Data Catalog: administre datos con el catálogo de datos que actúa como un repositorio central para metadatos
- AWS Glue ETL: lea y escriba metadatos en su catálogo de datos
- Amazon Athena y Amazon Redshift, Amazon EMR, Amazon ETL: obtenga el catálogo de datos para ETL, análisis y más.
¿Cómo configurar AWS Glue?
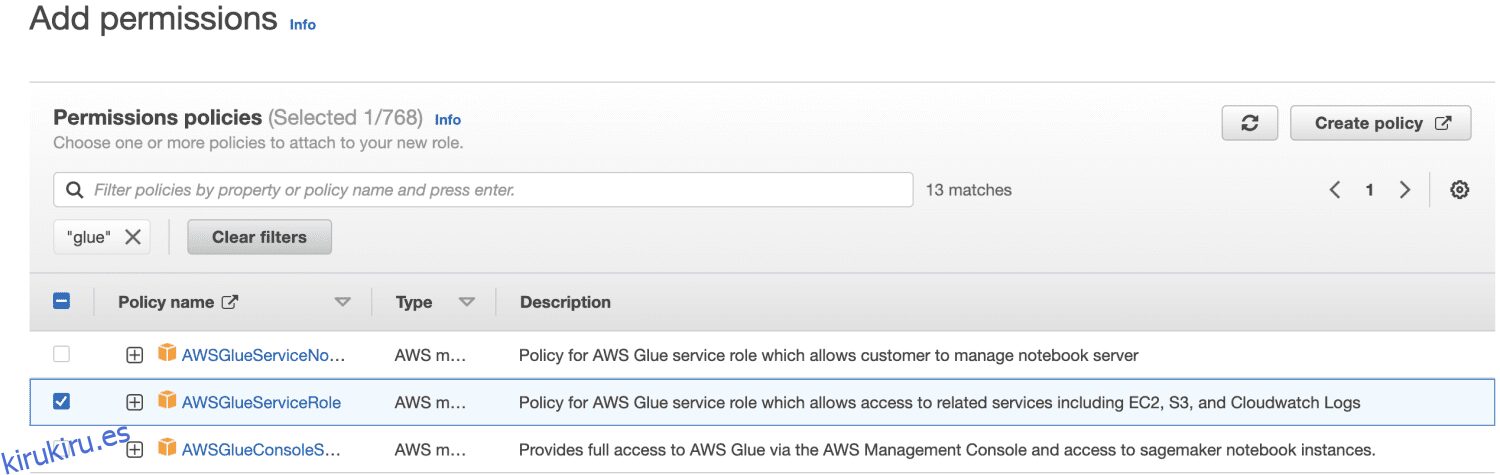
En primer lugar, inicie sesión en la consola de administración de AWS y abra la consola de IAM. Haga clic en Crear rol. Luego, para el tipo de función, busque Glue y seleccione Permisos.
Elijo AWSGlueServiceRole para los permisos generales de AWS Glue Studio y AWS Glue y la política administrada por AWS AmazonS3FullAccess para acceder a los recursos de Amazon S3.
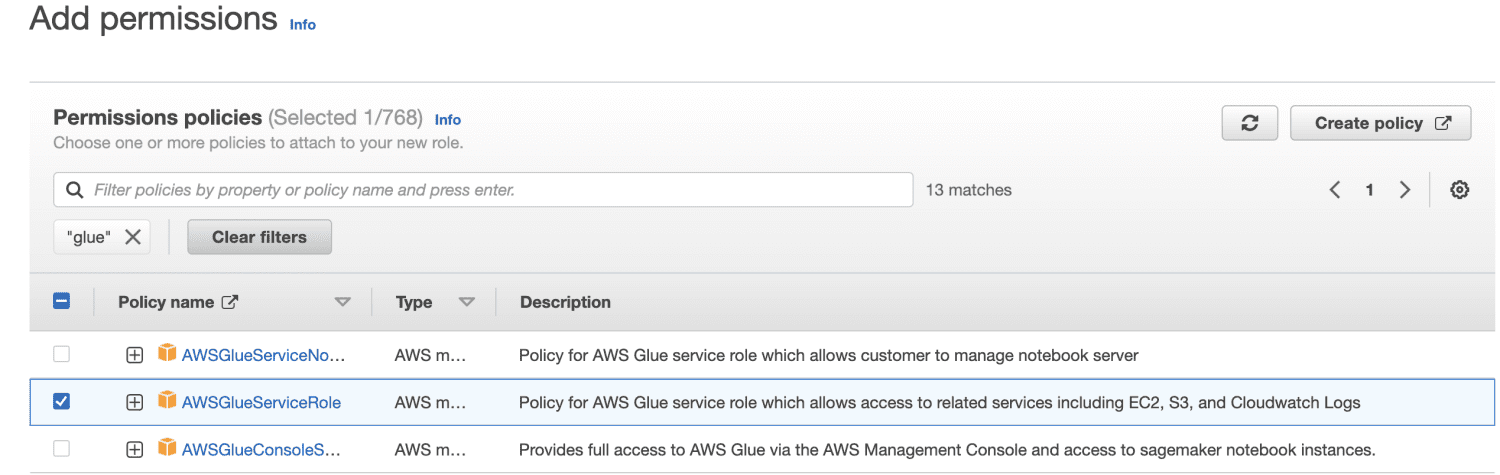
Introduzca un nombre de función.
Haga clic en Crear rol.
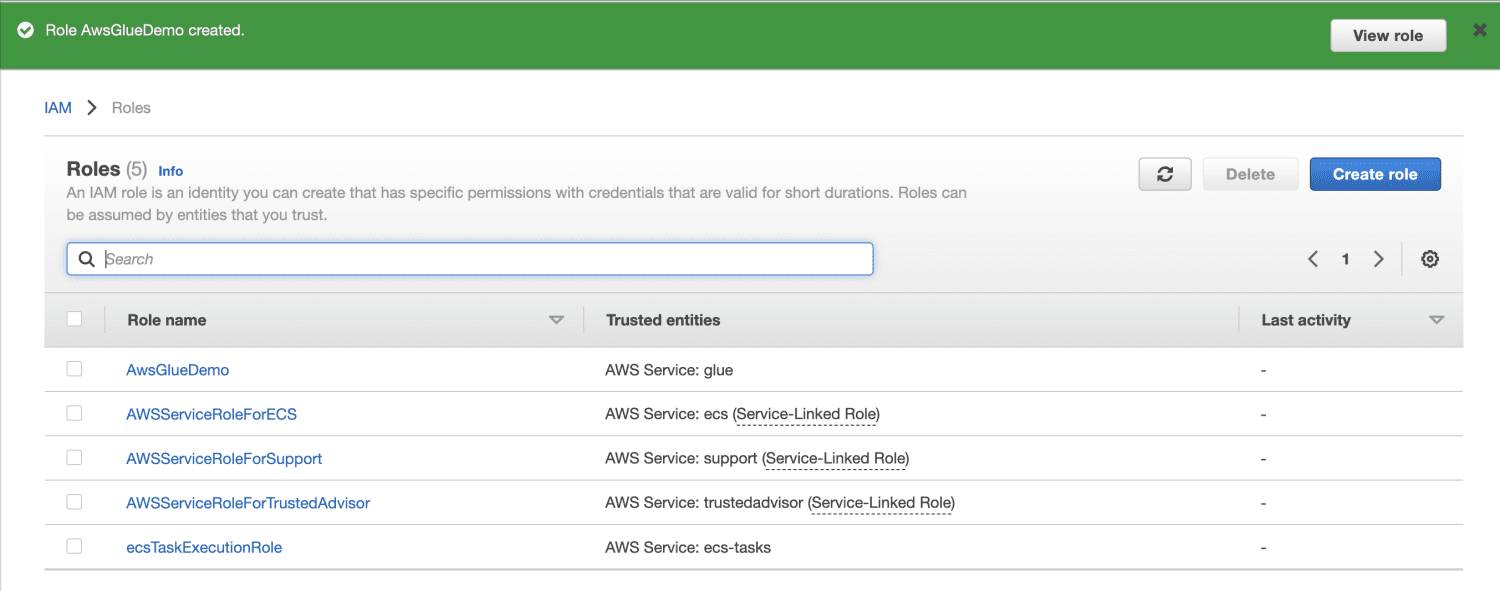
Cree un depósito de Amazon S3.
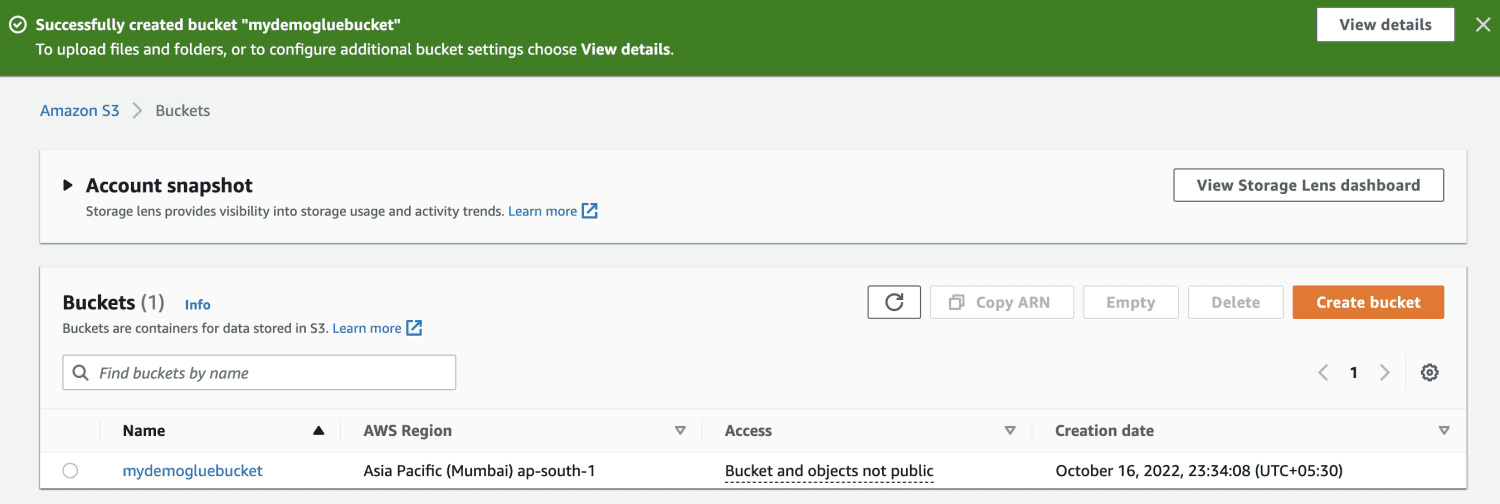
Cree una carpeta dentro del depósito S3.
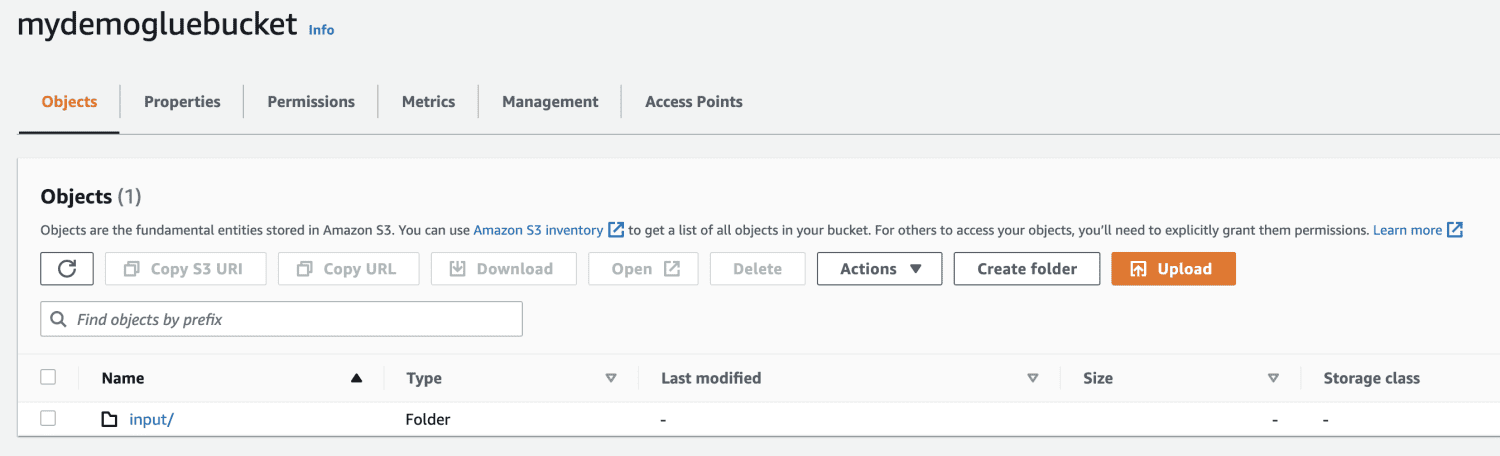
Elija el archivo para cargar.
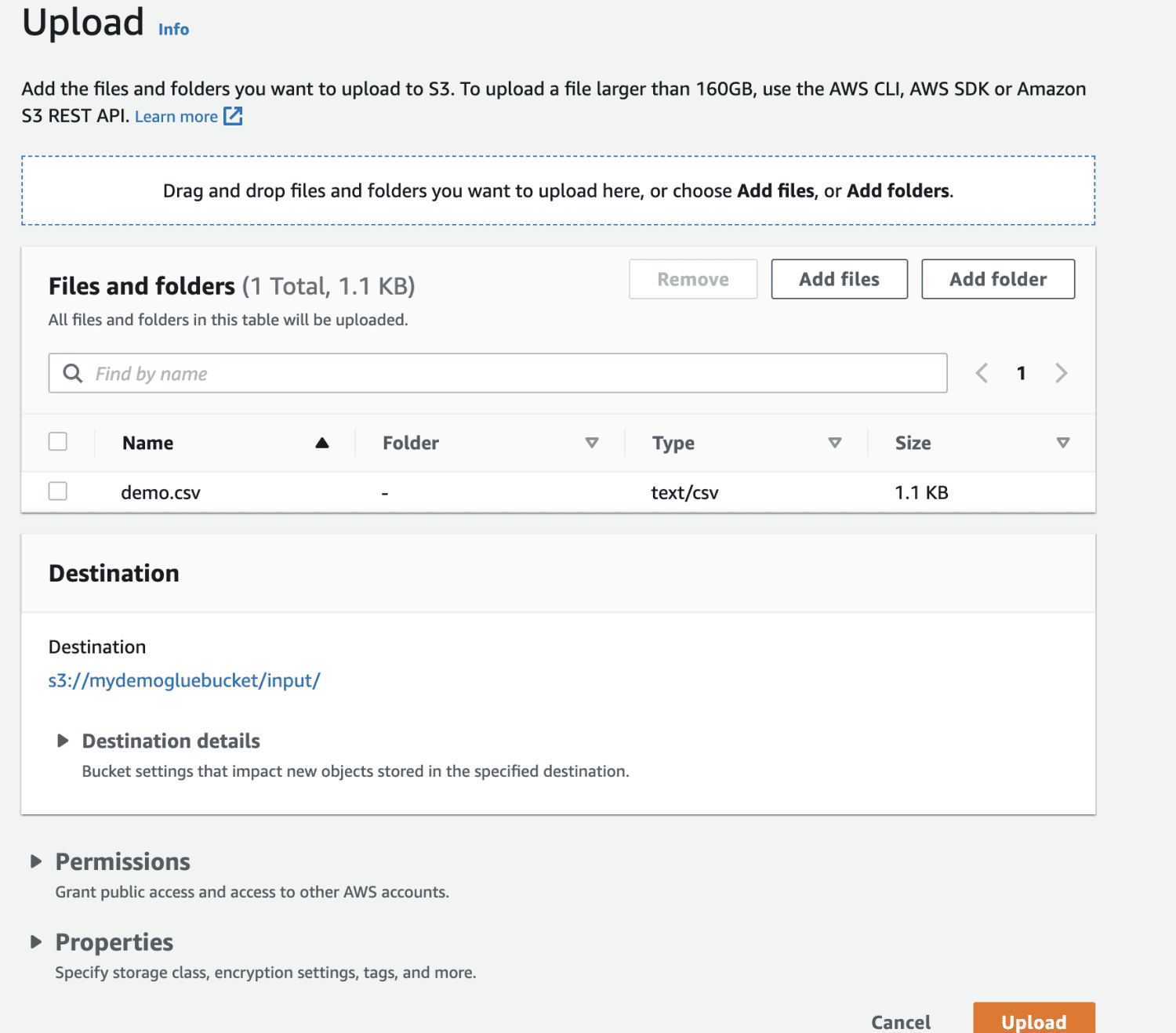
Finalmente, cargue el archivo en el cubo.
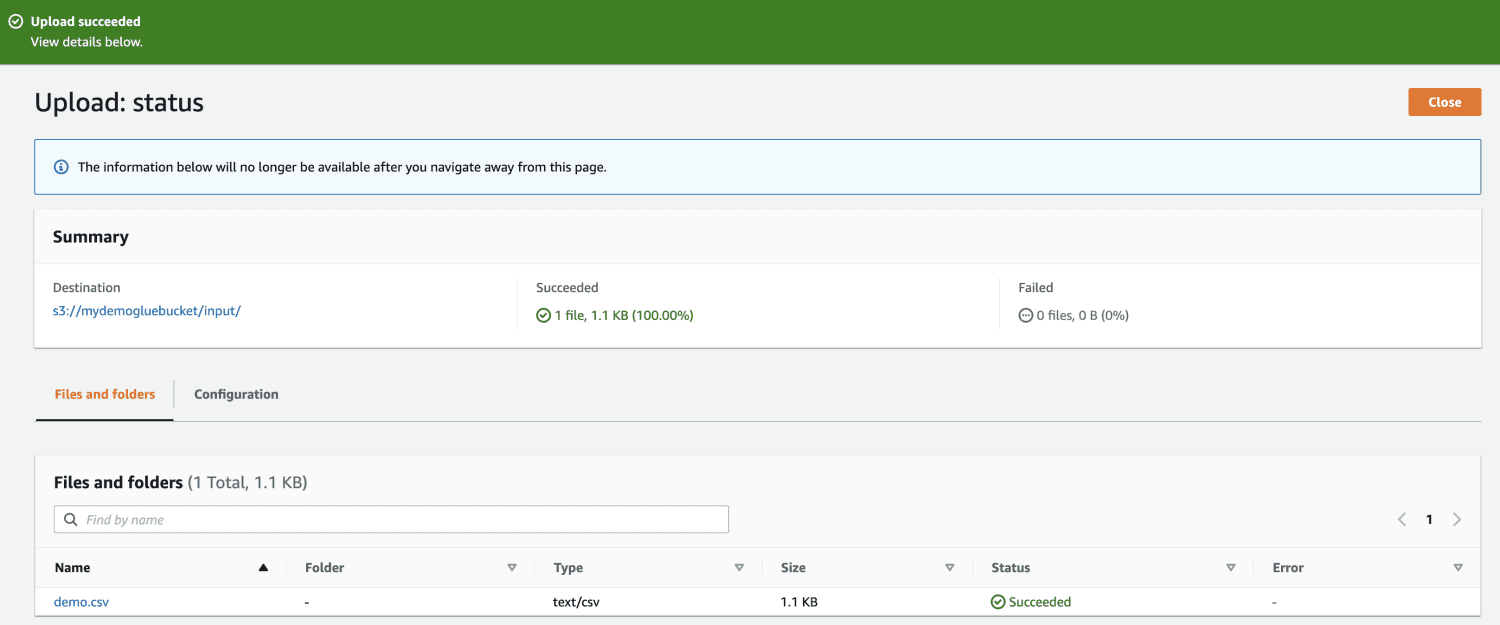
A continuación, abra AWS Glue desde la consola de administración de AWS y cree una base de datos.
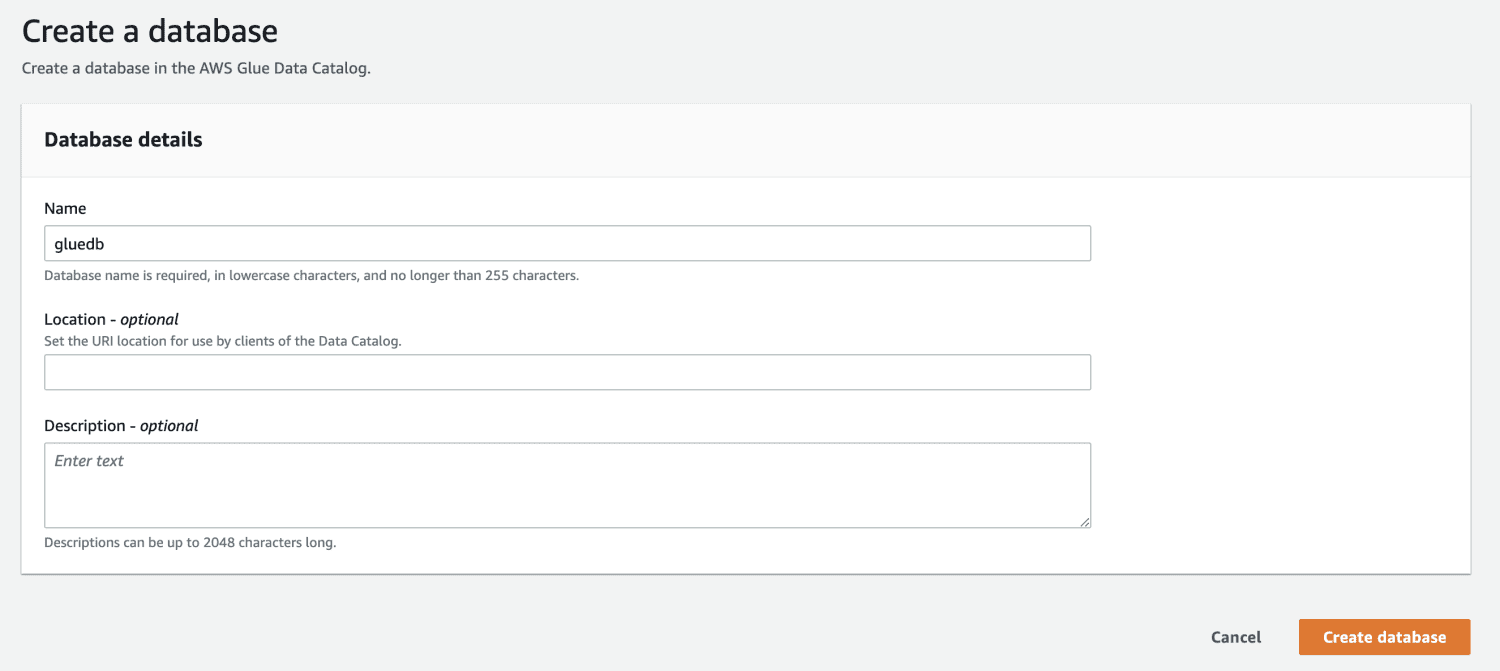
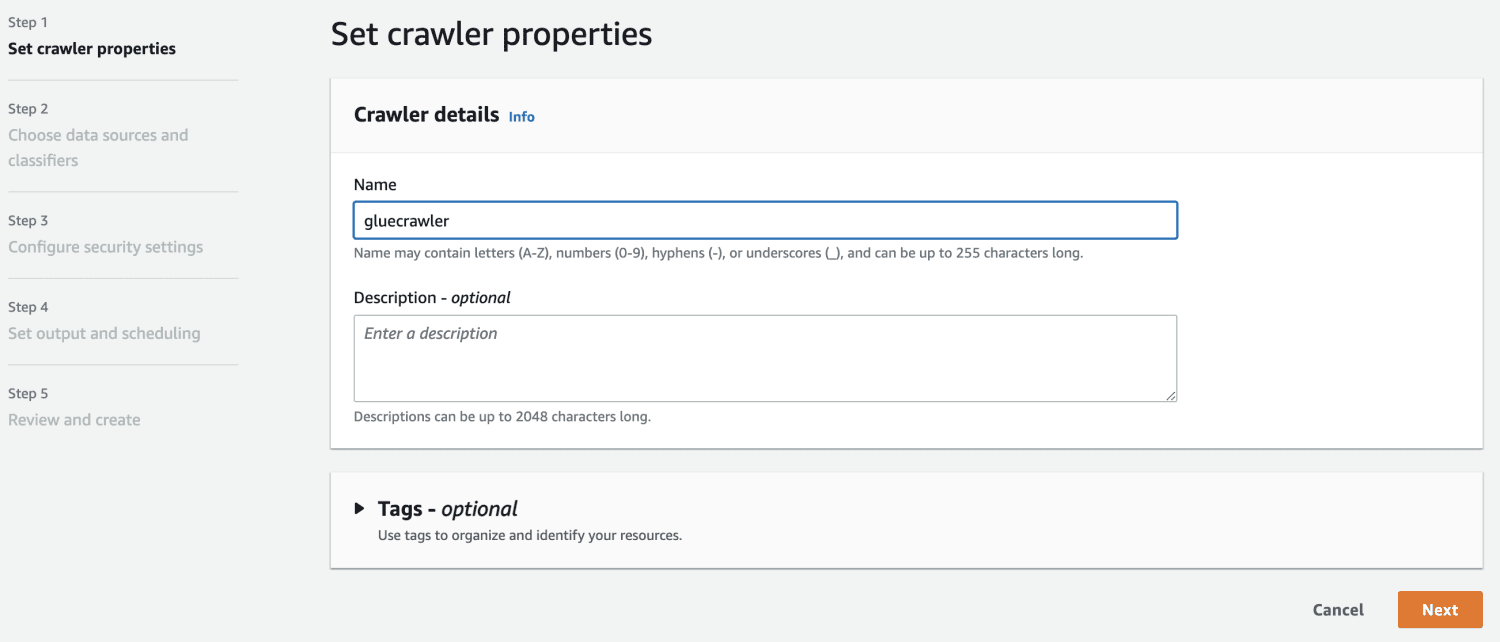
Ahora que tiene una base de datos en AWS Glue, cree un rastreador.
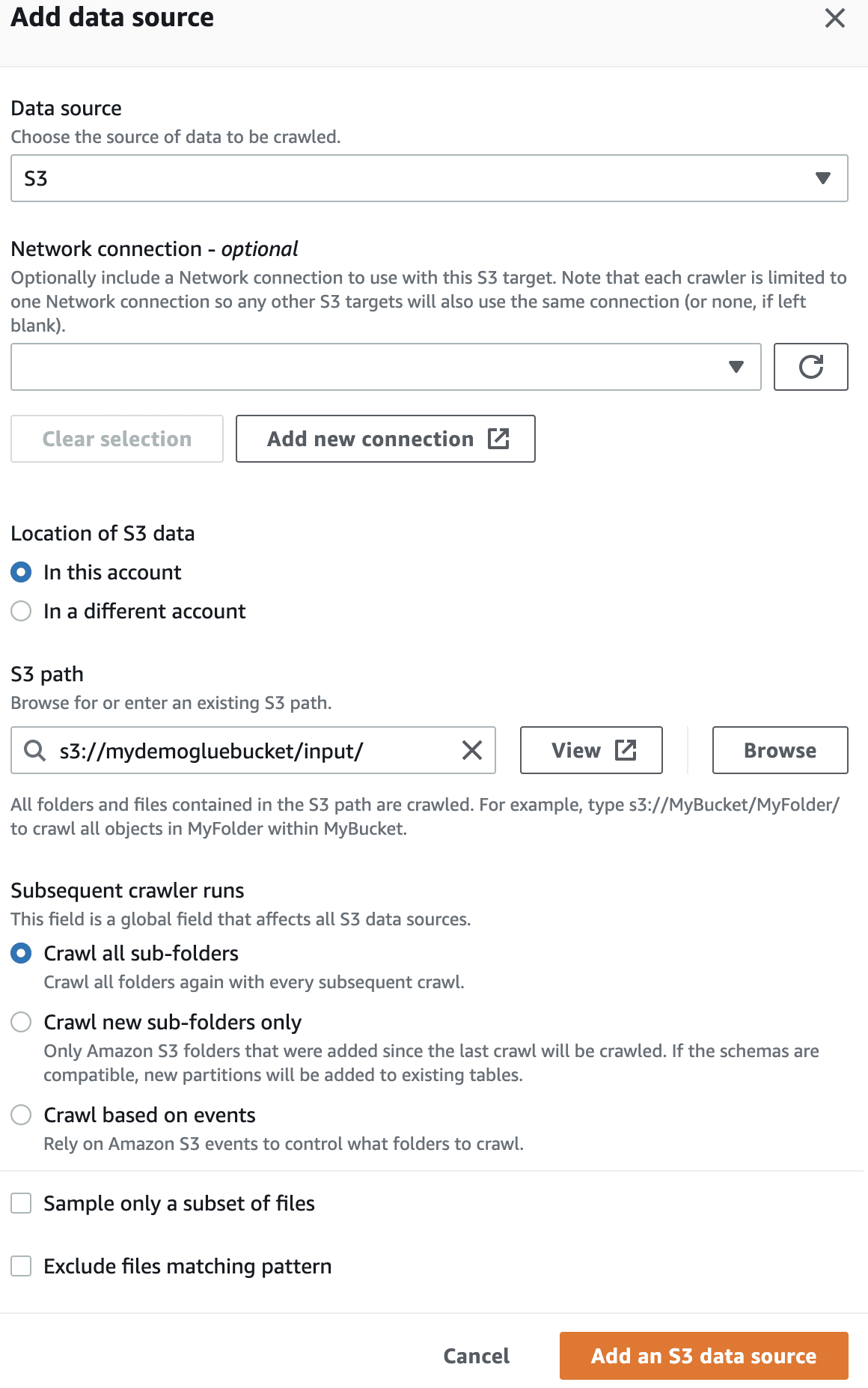
En la fuente de datos, seleccione el depósito S3 que creó.
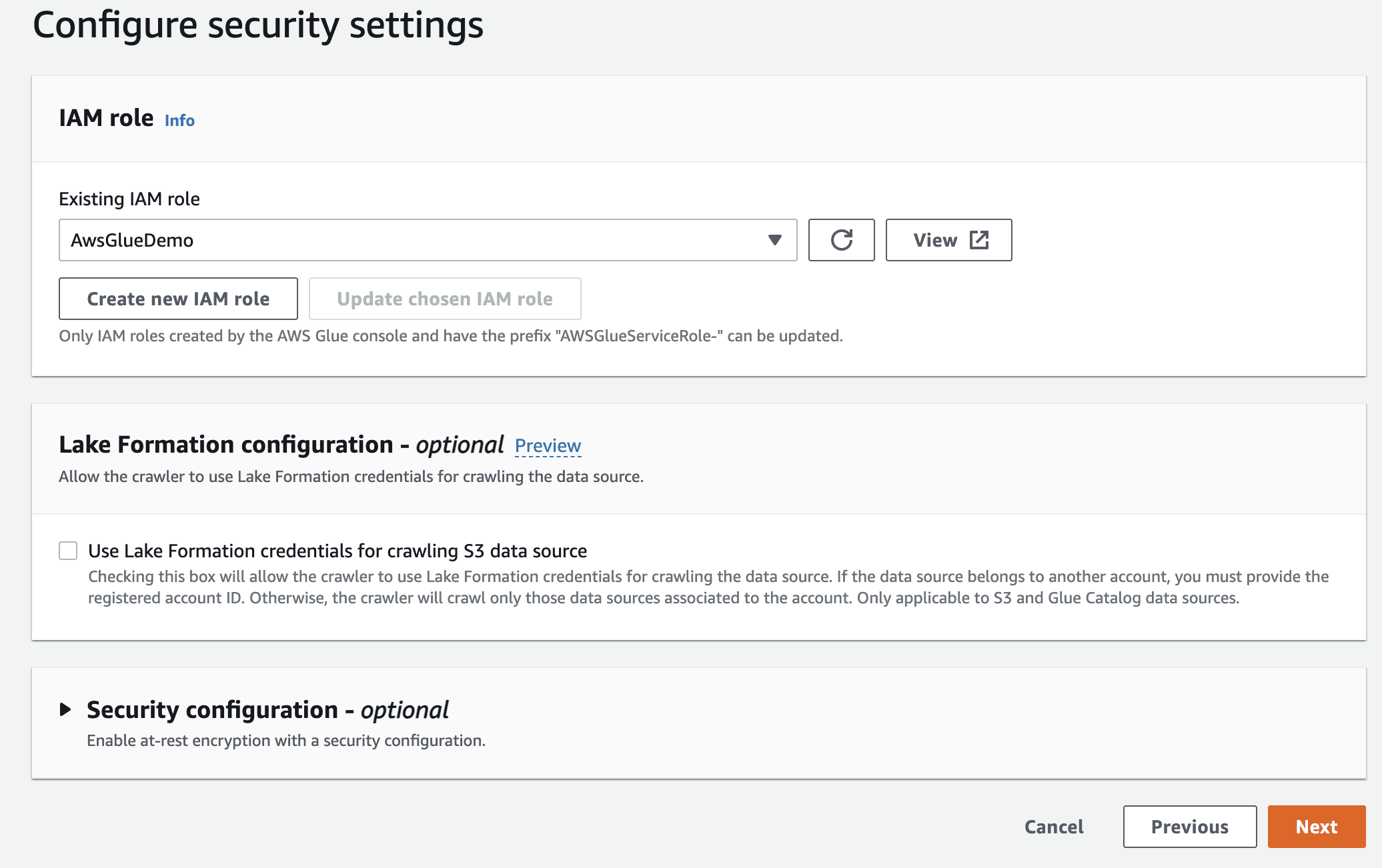
A continuación, seleccione el rol de IaM para AWS Glue que creó al principio.
Finalmente, en la salida, seleccione la base de datos pegada que creó.
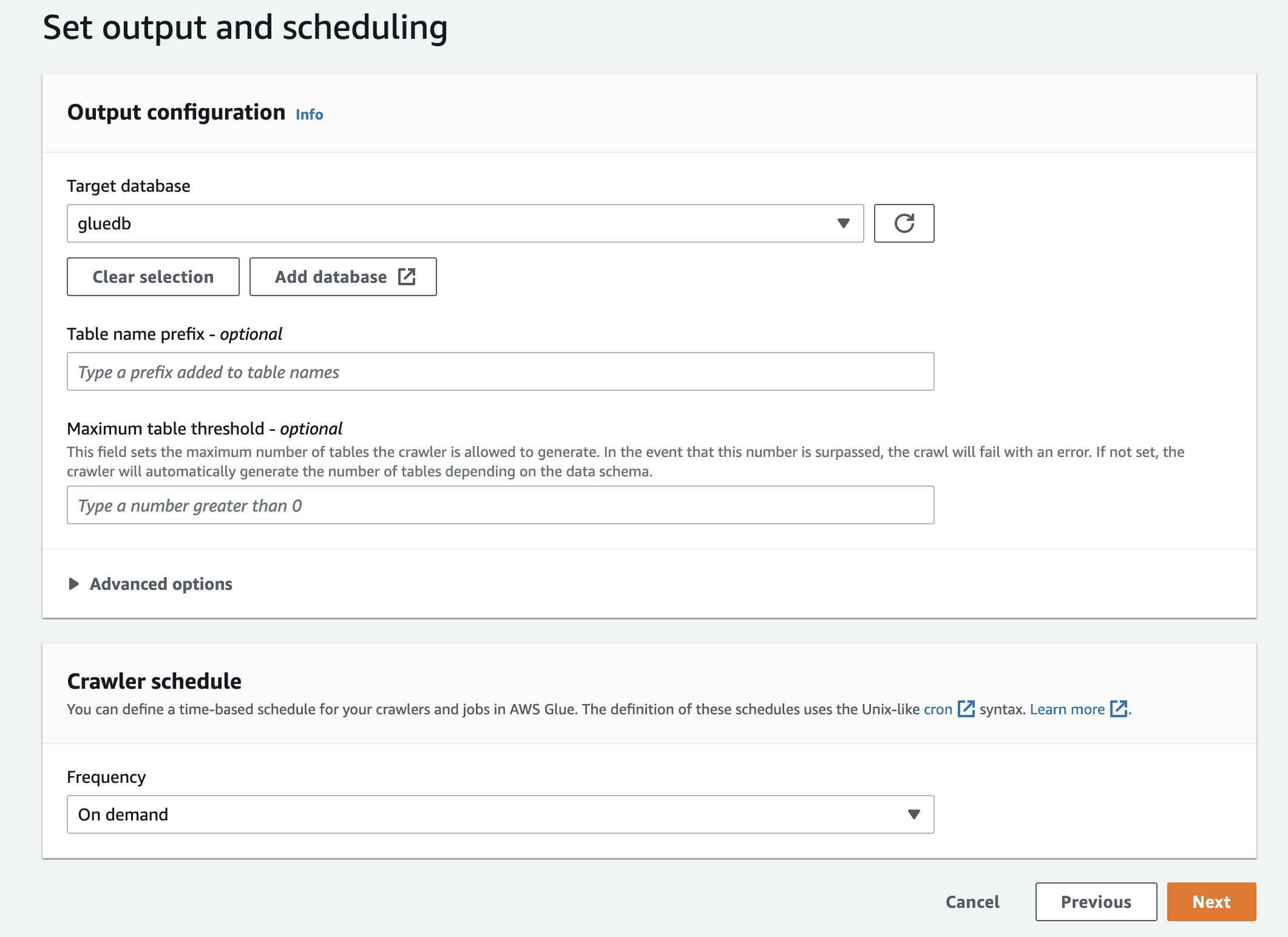
Revise todas las configuraciones y cree el rastreador.
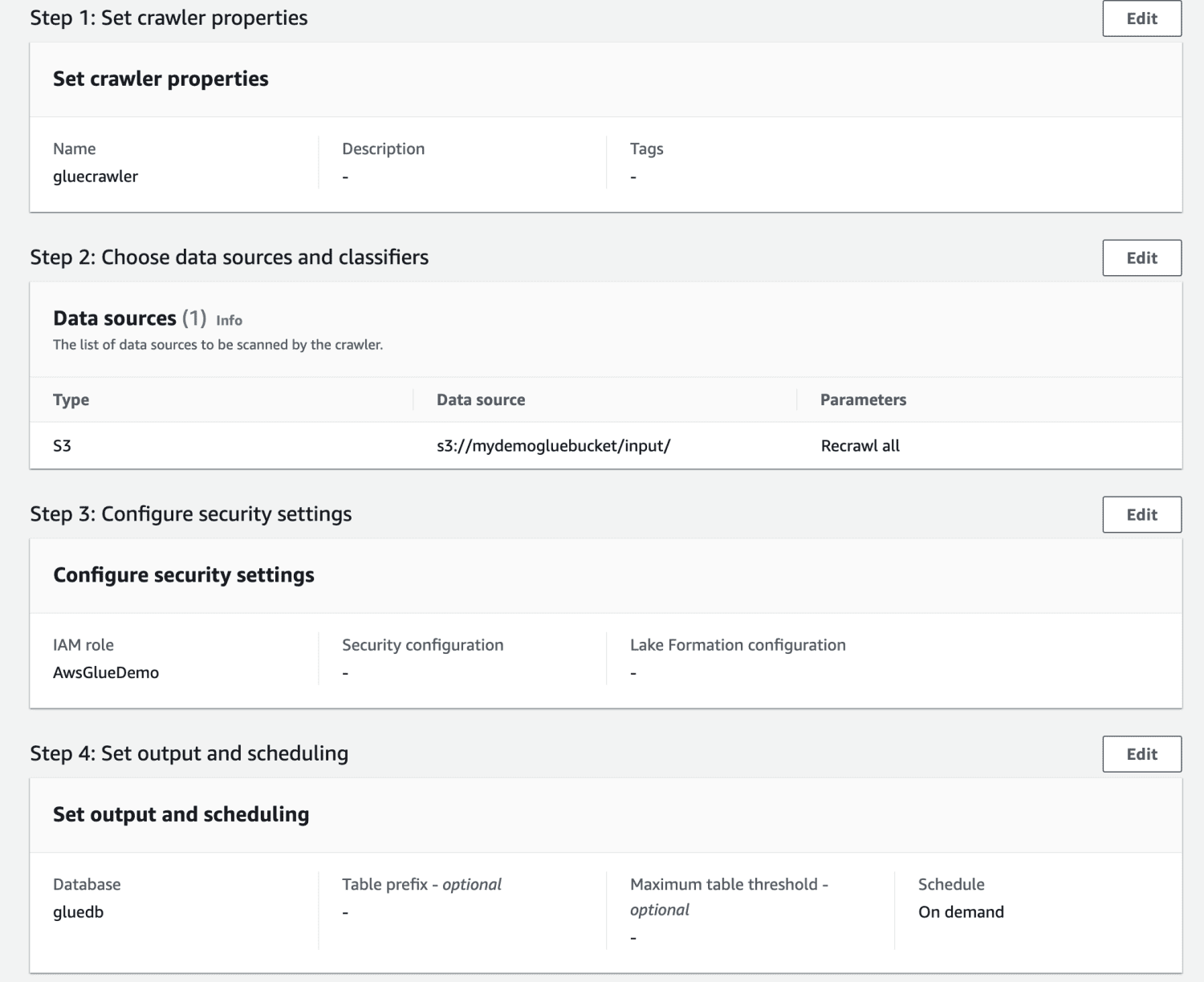
Una vez creado el rastreador, selecciónelo y haga clic en Ejecutar. Después de un tiempo, obtendrá el estado listo.
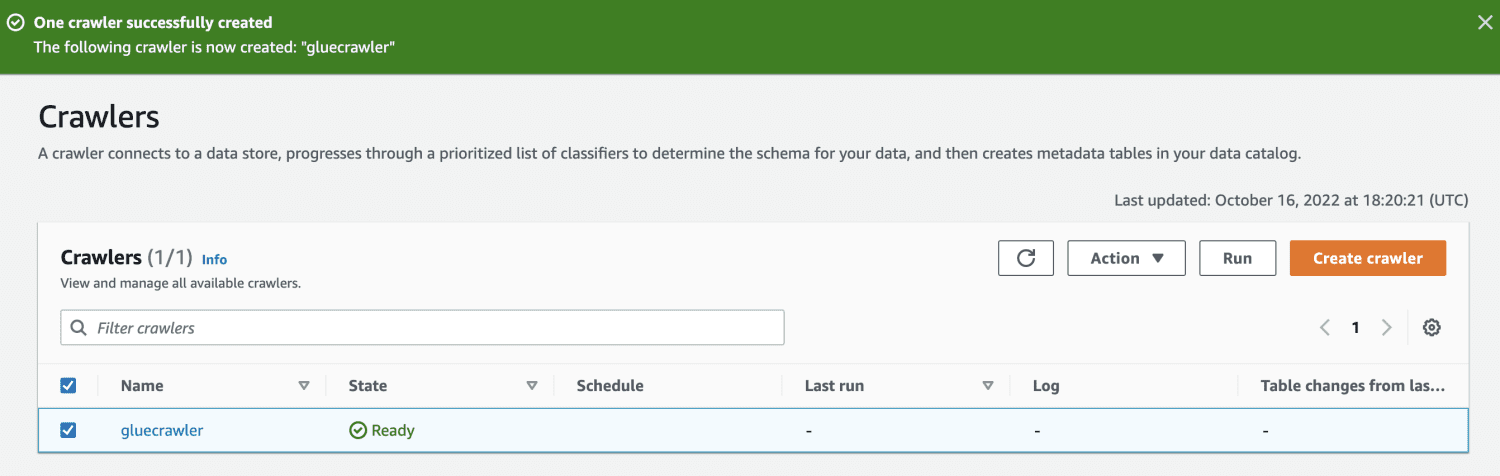
Al ejecutar el rastreador, la base de datos obtendrá una tabla con todos los datos del archivo CSV.
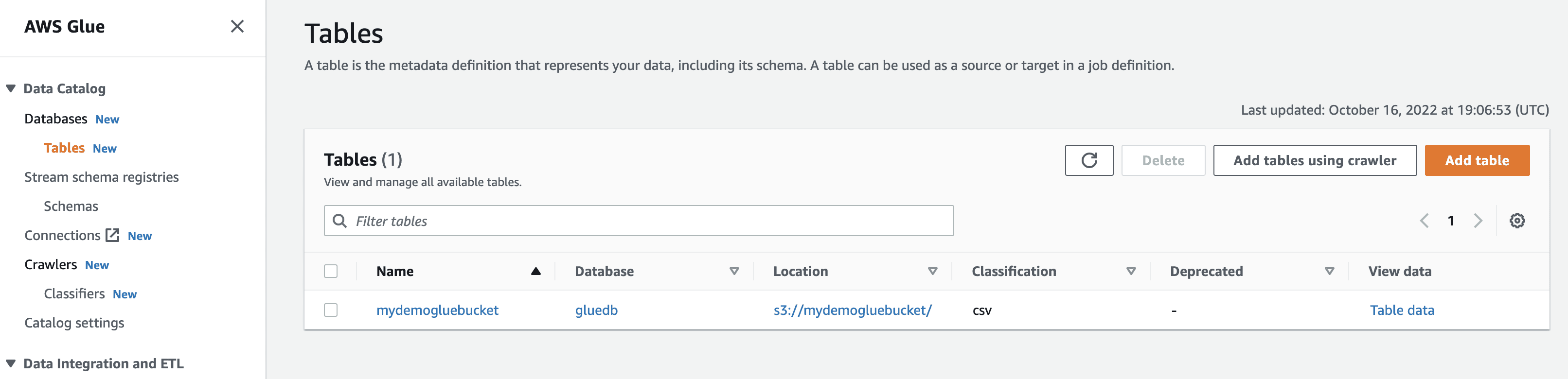
Cuando haga clic en ver datos, será llevado a Amazon Athena (editor de consultas). Cuando ejecuta la consulta, puede ver los datos de la tabla.
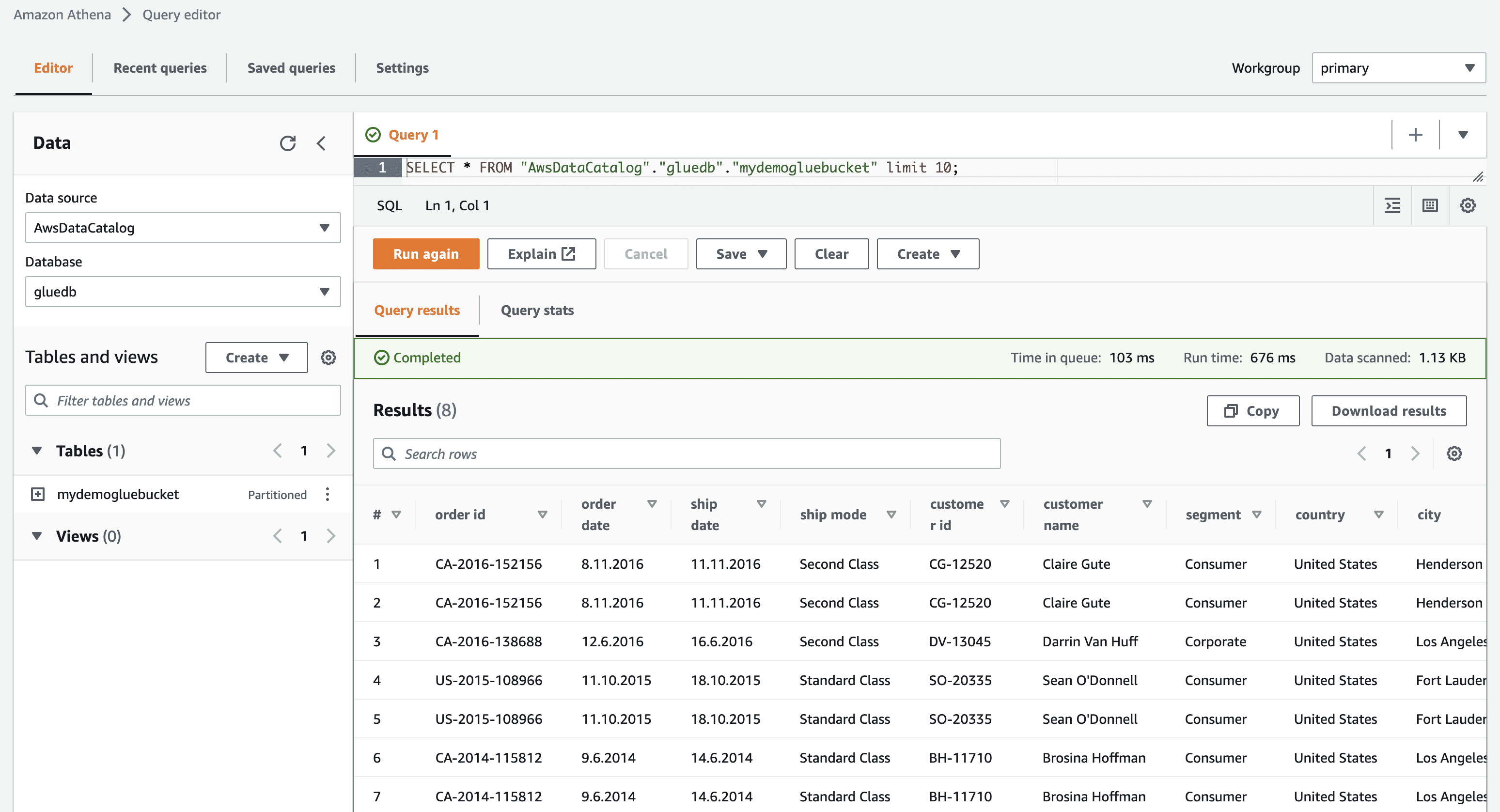
Ahora puede usar con éxito este rastreador de AWS Glue en cualquier trabajo de ETL.
¿Qué es AWS Glue Databrew?
AWS Glue DataBrew permite a los usuarios normalizar y limpiar datos sin escribir ningún código. DataBrew puede reducir el tiempo necesario para preparar los datos para el aprendizaje automático y el análisis hasta en un 80 % en comparación con la preparación de datos desarrollada a medida.
Hay más de 250 transformaciones de datos prefabricadas que se pueden usar para automatizar tareas de preparación de datos, como filtrar anomalías, corregir valores no válidos y convertir datos a formatos estándar.
DataBrew facilita que los científicos de datos, los analistas de negocios y los ingenieros colaboren en la extracción de información de los datos sin procesar. DataBrew no tiene servidor, por lo que no necesita administrar la infraestructura ni crear clústeres para explorar y transformar terabytes de datos sin procesar.
Características de DataBrew para empresas
Preparación de datos visualizados
DataBrew es una forma diferente de ver los datos que normalmente se ven en las bases de datos en columnas como números alfanuméricos. DataBrew visualiza todas las fuentes de datos cargadas para ayudarlo a comprender las relaciones y la jerarquía de los datos.
Más de 250 automatizaciones de preparación de datos
Se espera que los científicos de datos sigan una variedad de flujos de trabajo aislados y repetibles como parte de su trabajo. Estos flujos de trabajo y procesos han sido modelados por AWS como módulos de módulos independientes de datos y lenguaje. Esta biblioteca incluye acciones que pueden utilizar los usuarios finales.
Linaje de datos
Al igual que los registros de auditoría que se utilizan para realizar un seguimiento de la actividad del cliente en la red de TI de una red de TI, el linaje de datos le permite realizar un seguimiento de las actividades de transformación de datos dentro de AWS DataBrew. Esta información incluye la fuente de datos, las transformaciones aplicadas y la salida de datos, incluida la ubicación de destino.
Mapeo de datos
Databrew le permite encontrar campos coincidentes en dos fuentes de datos. Una vez que se han identificado los campos coincidentes, se pueden cargar en un esquema.
AWS Glue DataBrew: Beneficios
A continuación se muestran las características de AWS Glue DataBrew:
- Menor barrera de entrada para la preparación de datos
- Generación automatizada de perfiles de datos
- Automatice más de 250 procesos de preparación de datos
- Sugerencias prescriptivas inteligentes
Alternativas a AWS Glue
Flujo de aire
Airflow pertenece a la sección Workflow Manager de una pila tecnológica. Es una herramienta de código abierto que admite estrellas de GitHub, bifurcaciones de GitHub y otras funciones. Airflow le permite crear flujos de trabajo utilizando diagramas acíclicos dirigidos (DAG). El programador de Airflow ejecuta sus tareas utilizando una matriz de trabajadores y siguiendo las dependencias especificadas.
matillion

Matillion ETL, una herramienta ETL/ELT, se diseñó explícitamente para plataformas de bases de datos en la nube como Amazon Redshift y Google BigQuery. Es una interfaz de usuario moderna basada en navegador con potentes capacidades ETL/ELT push-down. Puede estar listo y funcionando en minutos con una configuración rápida.
Puntada
Stitch es un servicio ETL de código abierto que conecta varias fuentes de datos y replica los datos en los destinos preferidos. Es muy fácil de usar, ya que no necesita ningún conocimiento de codificación para mover datos entre fuentes y destinos en Stitch. Es fácil de usar, tiene una GUI amigable y es rápido.
Stitch no le permite elegir un tablero prefabricado, a diferencia de otras herramientas ETL. En su lugar, debe integrar sus datos en los almacenes de datos abiertos que seleccione como destino. Puede ser difícil navegar por los inventarios.
Alteryx

Alteryx es una plataforma de automatización de análisis que ayuda con la preparación y combinación de recopilación de datos. Estos datos se pueden utilizar para acelerar los procesos y proporcionar información empresarial. Debido a que es una herramienta de arrastrar y soltar, no necesita ningún conocimiento de programación. Alteryx es un gran lugar para buscar consejos y respuestas de profesionales de la industria.
Conclusión
Entonces, eso fue todo sobre AWS Glue, que es una solución basada en la nube que le permite trabajar con canalizaciones ETL. En resumen, el proceso de interacción con el usuario de AWS Glue consta de tres fases. Para crear un catálogo de datos, primero usa rastreadores de datos. A continuación, crea el código ETL requerido por la canalización de datos de AWS. Finalmente, se crea el cronograma ETL. Espero que este blog le haya brindado una buena descripción general de Amazon Glue.
También puede explorar los mejores consejos para proteger el almacenamiento de AWS S3.