
En este artículo, analizaremos la vectorización, una técnica de PNL, y comprenderemos su importancia con una guía completa sobre los diferentes tipos de vectorización.
Hemos discutido los conceptos fundamentales del preprocesamiento de PNL y la limpieza de texto. Analizamos los conceptos básicos de la PNL, sus diversas aplicaciones y técnicas como tokenización, normalización, estandarización y limpieza de texto.

Antes de discutir la vectorización, revisemos qué es la tokenización y en qué se diferencia de la vectorización.
Tabla de contenido
¿Qué es la tokenización?
La tokenización es el proceso de dividir oraciones en unidades más pequeñas llamadas tokens. Token ayuda a las computadoras a comprender y trabajar con texto fácilmente.
EX. ‘Este artículo es bueno’
Fichas- [‘This’, ‘article’, ‘is’, ‘good’.]
¿Qué es la vectorización?
Como sabemos, los modelos y algoritmos de aprendizaje automático comprenden datos numéricos. La vectorización es un proceso de convertir datos textuales o categóricos en vectores numéricos. Al convertir datos en datos numéricos, puede entrenar su modelo con mayor precisión.
¿Por qué necesitamos la vectorización?
❇️ La tokenización y la vectorización tienen diferente importancia en el procesamiento del lenguaje natural (NPL). La tokenización divide las oraciones en pequeños tokens. La vectorización lo convierte a un formato numérico para que el modelo de computadora/ML pueda entenderlo.
❇️ La vectorización no solo es útil para convertirla a forma numérica sino también para capturar el significado semántico.
❇️ La vectorización puede reducir la dimensionalidad de los datos y hacerlos más eficientes. Esto podría resultar muy útil al trabajar con un gran conjunto de datos.
❇️ Muchos algoritmos de aprendizaje automático requieren entrada numérica, como las redes neuronales, por lo que la vectorización puede ayudarnos.
Existen diferentes tipos de técnicas de vectorización, las cuales entenderemos a través de este artículo.
Bolsa de palabras
Si tiene un montón de documentos u oraciones y desea analizarlos, una Bolsa de palabras simplifica este proceso al tratar el documento como una bolsa llena de palabras.
El enfoque de bolsa de palabras puede resultar útil en la clasificación de textos, el análisis de opiniones y la recuperación de documentos.
Supongamos que está trabajando en mucho texto. Una bolsa de palabras le ayudará a representar datos de texto creando un vocabulario de palabras únicas en nuestros datos de texto. Después de crear vocabulario, codificará cada palabra como un vector según la frecuencia (con qué frecuencia aparece cada palabra en ese texto) de estas palabras.
Estos vectores constan de números no negativos (0,1,2…..) que representan el número de frecuencias en ese documento.
La bolsa de palabras implica tres pasos:
Paso 1: Tokenización
Dividirá los documentos en tokens.
Ej – (Oración: “Me encanta la pizza y me encantan las hamburguesas”)
Paso 2: Separación de palabras única/creación de vocabulario
Crea una lista de todas las palabras únicas que aparecen en tus oraciones.
[“I”, “love”, “Pizza”, “and”, “Burgers”]
Paso 3: Contar la aparición de palabras/creación de vectores
Este paso contará cuántas veces se repite cada palabra del vocabulario y la almacenará en una matriz dispersa. En la matriz dispersa, cada fila de un vector de oración cuya longitud (las columnas de la matriz) es igual al tamaño del vocabulario.
Importar CountVectorizer
Vamos a importar CountVectorizer para entrenar nuestro modelo de Bolsa de palabras.
from sklearn.feature_extraction.text import CountVectorizer
Crear vectorizador
En este paso, crearemos nuestro modelo usando CountVectorizer y lo entrenaremos usando nuestro documento de texto de muestra.
# Sample text documents
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a CountVectorizer
cv = CountVectorizer()
# Fit and Transform X = cv.fit_transform(documents)
Convertir a una matriz densa
En este paso, convertiremos nuestras representaciones en una matriz densa. Además, obtendremos nombres de funciones o palabras.
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert to dense array X_dense = X.toarray()
Imprimamos la matriz de términos del documento y las palabras características.
# Print the DTM and feature names
print("Document-Term Matrix (DTM):")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Documento – Matriz de términos (DTM):
 Matriz
Matriz
Nombres de funciones:
 Palabras destacadas
Palabras destacadas
Como puede ver, los vectores constan de números no negativos (0,1,2…) que representan la frecuencia de las palabras en el documento.
Tenemos cuatro documentos de texto de muestra y hemos identificado nueve palabras únicas de estos documentos. Almacenamos estas palabras únicas en nuestro vocabulario asignándoles ‘Nombres de funciones’.
Luego, nuestro modelo Bolsa de palabras verifica si la primera palabra única está presente en nuestro primer documento. Si está presente asigna el valor 1, en caso contrario asigna 0.
Si la palabra aparece varias veces (por ejemplo, 2 veces), asigna un valor correspondiente.
Por ejemplo, en el segundo documento, la palabra ‘documento’ se repite dos veces, por lo que su valor en la matriz será 2.
Si queremos una sola palabra como característica en la clave de vocabulario: representación Unigram.
n – gramos = Unigramas, bigramas…….etc.
Hay muchas bibliotecas como scikit-learn para implementar bolsas de palabras: Keras, Gensim y otras. Esto es sencillo y puede resultar útil en diferentes casos.
Pero Bolsa de palabras es más rápido pero tiene algunas limitaciones.
Para resolver este problema podemos elegir mejores enfoques, uno de ellos es TF-IDF. Comprendamos en detalle.
TF-IDF
TF-IDF, o Frecuencia de términos: frecuencia de documento inversa, es una representación numérica para determinar la importancia de las palabras en el documento.
¿Por qué necesitamos TF-IDF en lugar de Bag of Words?
Una bolsa de palabras trata todas las palabras por igual y solo se preocupa por la frecuencia de palabras únicas en las oraciones. TF-IDF da importancia a las palabras en un documento considerando tanto la frecuencia como la singularidad.
Las palabras que se repiten con demasiada frecuencia no dominan a las palabras menos frecuentes y más importantes.
TF: La frecuencia de términos mide la importancia de una palabra en una sola oración.
IDF: La frecuencia inversa de documentos mide la importancia de una palabra en toda la colección de documentos.
TF = Frecuencia de palabras en un documento / Número total de palabras en ese documento
DF = Documento que contiene palabra w / Número total de documentos
IDF = log(Número total de documentos/Documentos que contienen la palabra w)
IDF es recíproco de DF. La razón detrás de esto es que cuanto más común es la palabra en todos los documentos, menor es su importancia en el documento actual.
Puntuación final de TF-IDF: TF-IDF = TF * IDF
Es una forma de averiguar qué palabras son comunes en un único documento y únicas en todos los documentos. Estas palabras pueden resultar útiles para encontrar el tema principal del documento.
Por ejemplo,
Doc1 = «Me encanta el aprendizaje automático»
Doc2 = «Me encanta kirukiru.es»
Tenemos que encontrar la matriz TF-IDF para nuestros documentos.
Primero, crearemos un vocabulario de palabras únicas.
Vocabulario = [“I,” “love,” “machine,” “learning,” “Geekflare”]
Entonces, tenemos 5 cinco palabras. Busquemos TF e IDF para estas palabras.
TF = Frecuencia de palabras en un documento / Número total de palabras en ese documento
TF:
- Para “I” = TF para Doc1: 1/4 = 0,25 y para Doc2: 1/3 ≈ 0,33
- Para “amor”: TF para Doc1: 1/4 = 0,25 y para Doc2: 1/3 ≈ 0,33
- Para “Máquina”: TF para Doc1: 1/4 = 0,25 y para Doc2: 0/3 ≈ 0
- Para “Aprendizaje”: TF para Doc1: 1/4 = 0,25 y para Doc2: 0/3 ≈ 0
- Para “kirukiru.es”: TF para Doc1: 0/4 = 0 y para Doc2: 1/3 ≈ 0,33
Ahora, calculemos las FDI.
IDF = log(Número total de documentos/Documentos que contienen la palabra w)
FDI:
- Para “I”: IDF es log(2/2) = 0
- Para “amor”: IDF es log(2/2) = 0
- Para “Máquina”: IDF es log(2/1) = log(2) ≈ 0,69
- Para “Aprendizaje”: IDF es log(2/1) = log(2) ≈ 0,69
- Para “kirukiru.es”: IDF es log(2/1) = log(2) ≈ 0,69
Ahora, calculemos la puntuación final de TF-IDF:
- Para “I”: TF-IDF para Doc1: 0,25 * 0 = 0 y TF-IDF para Doc2: 0,33 * 0 = 0
- Para “amor”: TF-IDF para Doc1: 0,25 * 0 = 0 y TF-IDF para Doc2: 0,33 * 0 = 0
- Para “Máquina”: TF-IDF para Doc1: 0,25 * 0,69 ≈ 0,17 y TF-IDF para Doc2: 0 * 0,69 = 0
- Para “Aprendizaje”: TF-IDF para Doc1: 0,25 * 0,69 ≈ 0,17 y TF-IDF para Doc2: 0 * 0,69 = 0
- Para “kirukiru.es”: TF-IDF para Doc1: 0 * 0,69 = 0 y TF-IDF para Doc2: 0,33 * 0,69 ≈ 0,23
La matriz TF-IDF se ve así:
I love machine learning kirukiru.es Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Los valores en una matriz TF-IDF le indican qué tan importante es cada término dentro de cada documento. Los valores altos indican que un término es importante en un documento en particular, mientras que los valores bajos sugieren que el término es menos importante o común en ese contexto.
TF-IDF se utiliza principalmente en la clasificación de texto, la creación de recuperación de información de chatbot y el resumen de texto.
Importar TfidfVectorizer
Importemos TfidfVectorizer desde sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
Crear vectorizador
Como puede ver, crearemos nuestro modelo Tf Idf usando TfidfVectorizer.
# Sample text documents
text = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a TfidfVectorizer
cv = TfidfVectorizer()
Crear matriz TF-IDF
Entrenemos nuestro modelo proporcionando texto. Después de eso, convertiremos la matriz representativa en una matriz densa.
# Fit and transform to create the TF-IDF matrix X = cv.fit_transform(text)
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert the TF-IDF matrix to a dense array for easier manipulation (optional) X_dense = X.toarray()
Imprima la matriz TF-IDF y las palabras destacadas
# Print the TF-IDF matrix and feature words
print("TF-IDF Matrix:")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Matriz TF-IDF:
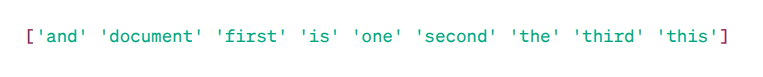 Palabras destacadas
Palabras destacadas
Como puede ver, estos números enteros con coma decimal indican la importancia de las palabras en documentos específicos.
Además, puedes combinar palabras en grupos de 2,3,4, etc. usando n-gramas.
Hay otros parámetros que podemos incluir: min_df, max_feature, subliner_tf, etc.
Hasta ahora, hemos explorado técnicas básicas basadas en frecuencia.
Pero TF-IDF no puede proporcionar significado semántico ni comprensión contextual del texto.
Comprendamos técnicas más avanzadas que han cambiado el mundo de la incrustación de palabras y cuál es mejor para el significado semántico y la comprensión contextual.
Palabra2Vec
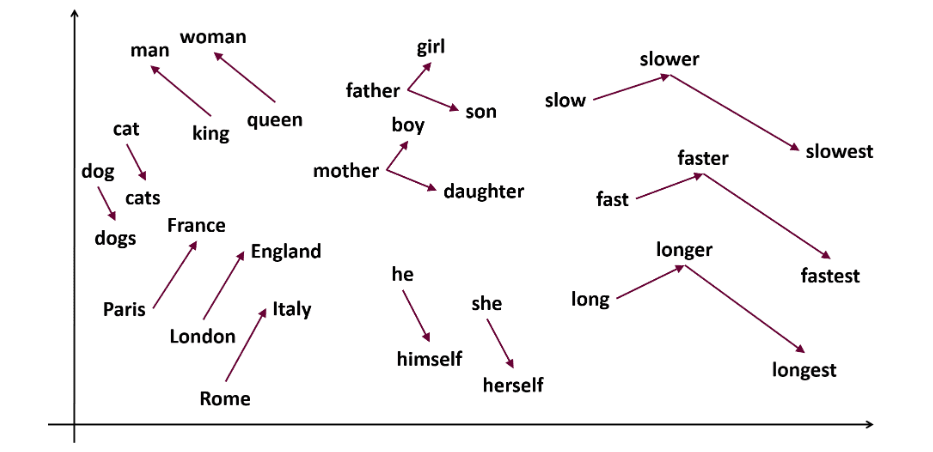
Word2vec es un popular incrustación de palabras (tipo de vector de palabras y útil para capturar similitudes semánticas y sintácticas) en PNL. Fue desarrollado por Tomas Mikolov y su equipo en Google en 2013. Word2vec representa palabras como vectores continuos en un espacio multidimensional.
Word2vec tiene como objetivo representar palabras de una manera que capture su significado semántico. Los vectores de palabras generados por word2vec se colocan en un espacio vectorial continuo.
Ej: los vectores ‘gato’ y ‘perro’ estarían más cerca que los vectores de ‘gato’ y ‘niña’.
 Fuente: usna.edu
Fuente: usna.edu
Word2vec puede utilizar dos arquitecturas modelo para crear incrustaciones de palabras.
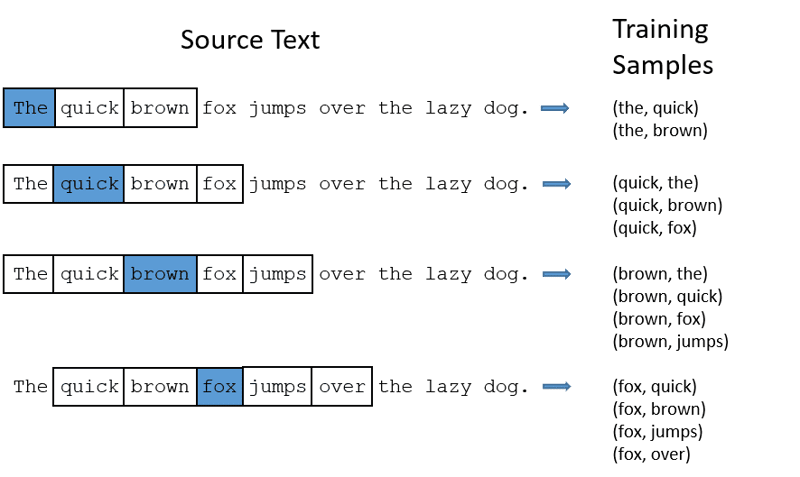
CBOW: Bolsa continua de palabras o CBOW intenta predecir una palabra promediando el significado de las palabras cercanas. Toma un número fijo o una ventana de palabras alrededor de la palabra objetivo, luego la convierte en forma numérica (incrustación), luego promedia todo y usa ese promedio para predecir la palabra objetivo con la red neuronal.
Ex- Objetivo de predicción: ‘Fox’
Palabras de oración: ‘El’, ‘rápido’, ‘marrón’, ‘salta’, ‘sobre’, ‘el’
 Palabra2Vec
Palabra2Vec
- CBOW toma una ventana de tamaño fijo (número) de palabras como 2 (2 a la izquierda y 2 a la derecha)
- Convertir a incrustación de palabras.
- CBOW promedia la palabra incrustación.
- CBOW promedia la palabra incrustada en las palabras de contexto.
- El vector promediado intenta predecir una palabra objetivo utilizando una red neuronal.
Ahora, comprendamos en qué se diferencia skip-gram de CBOW.
Skip-gram: es un modelo de incrustación de palabras, pero funciona de manera diferente. En lugar de predecir la palabra objetivo, skip-gram predice las palabras de contexto dadas las palabras objetivo.
Skip-grams captura mejor las relaciones semánticas entre palabras.
Ex- ‘Rey – Hombres + Mujeres = Reina’
Si desea trabajar con Word2Vec, tiene dos opciones: puede entrenar su propio modelo o utilizar un modelo previamente entrenado. Pasaremos por un modelo previamente entrenado.
Importar gensim
Puedes instalar gensim usando pip install:
pip install gensim
Tokeniza la oración usando word_tokenize:
Primero, convertiremos oraciones a palabras más bajas. Después de eso, tokenizaremos nuestras oraciones usando word_tokenize.
# Import necessary libraries
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample sentences
sentences = [
"I love thor",
"Hulk is an important member of Avengers",
"Ironman helps Spiderman",
"Spiderman is one of the popular members of Avengers",
]
# Tokenize the sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Entrenemos nuestro modelo:
Entrenaremos nuestro modelo proporcionando oraciones tokenizadas. Estamos utilizando 5 ventanas para este modelo de capacitación, puede adaptarlo según sus necesidades.
# Train a Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Find similar words
similar_words = model.wv.most_similar("avengers")
# Print similar words
print("Similar words to 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Palabras similares a ‘vengadores’:
 Similitud Word2Vec
Similitud Word2Vec
Estas son algunas de las palabras similares a “vengadores” según el modelo Word2Vec, junto con sus puntuaciones de similitud.
El modelo calcula una puntuación de similitud (principalmente similitud de coseno) entre los vectores de palabras de «vengadores» y otras palabras de su vocabulario. La puntuación de similitud indica qué tan estrechamente relacionadas están dos palabras en el espacio vectorial.
Ex –
Aquí, la palabra ‘ayuda’ con similitud de coseno -0.005911458611011982 con la palabra ‘vengadores’. El valor negativo sugiere que podrían ser diferentes entre sí.
Los valores de similitud del coseno varían de -1 a 1, donde:
- 1 indica que los dos vectores son idénticos y tienen similitud positiva.
- Los valores cercanos a 1 indican una alta similitud positiva.
- Los valores cercanos a 0 indican que los vectores no están fuertemente relacionados.
- Los valores cercanos a -1 indican una alta disimilitud.
- -1 indica que los dos vectores son totalmente opuestos y tienen una similitud negativa perfecta.
visita esto enlace si desea comprender mejor los modelos de word2vec y una representación visual de cómo funcionan. Es una herramienta realmente genial para ver CBOW y skip-gram en acción.
Similar a Word2Vec, tenemos GloVe. GloVe puede producir incrustaciones que requieren menos memoria en comparación con Word2Vec. Entendamos más sobre GloVe.
Guante
Los vectores globales para representación de palabras (GloVe) son una técnica como word2vec. Se utiliza para representar palabras como vectores en un espacio continuo. El concepto detrás de GloVe es el mismo que el de Word2Vec: produce incrustaciones de palabras contextuales teniendo en cuenta el rendimiento superior de Word2Vec.
¿Por qué necesitamos GloVe?
Word2vec es un método basado en ventanas y utiliza palabras cercanas para comprender palabras. Esto significa que el significado semántico de la palabra objetivo sólo se ve afectado por las palabras que la rodean en las oraciones, lo que constituye un uso ineficiente de las estadísticas.
Mientras que GloVe captura estadísticas globales y locales para incorporar palabras.
¿Cuándo utilizar GloVe?
Utilice GloVe cuando desee incrustar palabras que capturen relaciones semánticas más amplias y asociaciones globales de palabras.
GloVe es mejor que otros modelos en tareas de reconocimiento de entidades nombradas, analogía de palabras y similitud de palabras.
Primero, necesitamos instalar Gensim:
pip install gensim
Paso 1: Vamos a instalar bibliotecas importantes
# Import the required libraries import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Paso 2: Importar modelo de guante
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Paso 3: recuperar la representación vectorial de la palabra «lindo»
glove_model["cute"]
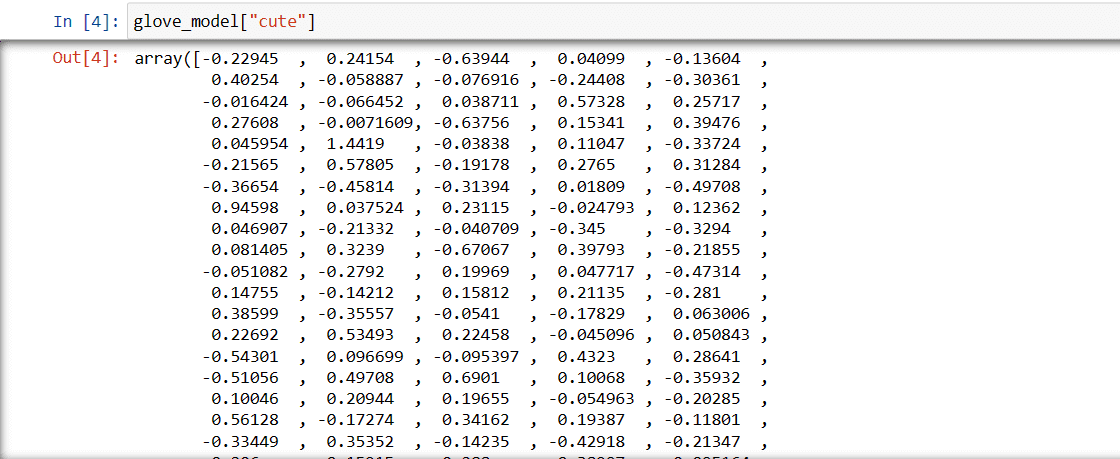 Vector de la palabra «lindo»
Vector de la palabra «lindo»
Estos valores capturan el significado de la palabra y las relaciones con otras palabras. Los valores positivos indican asociaciones positivas con ciertos conceptos, mientras que los valores negativos indican asociaciones negativas con otros conceptos.
En un modelo GloVe, cada dimensión del vector de palabras representa un determinado aspecto del significado o contexto de la palabra.
Los valores negativos y positivos en estas dimensiones contribuyen a cómo se relaciona semánticamente “lindo” con otras palabras en el vocabulario del modelo.
Los valores pueden ser diferentes para diferentes modelos. Busquemos algunas palabras similares a la palabra ‘niño’
Top 10 de palabras similares que el modelo cree que son más similares a la palabra ‘niño’
# find similar word
glove_model.most_similar("boy")
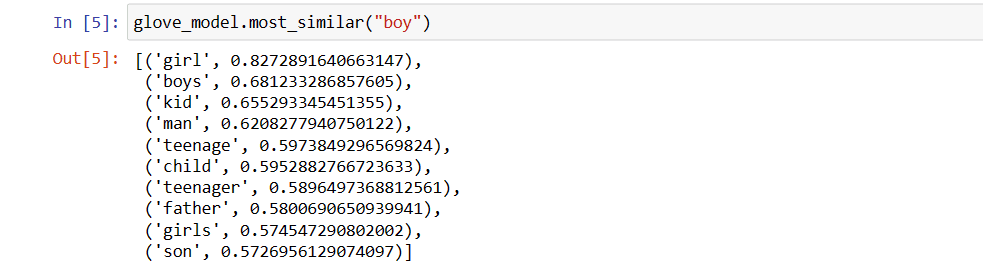 10 palabras similares a ‘niño’
10 palabras similares a ‘niño’
Como puedes ver, la palabra más similar a «niño» es «niña».
Ahora, intentaremos encontrar con qué precisión el modelo obtendrá el significado semántico de las palabras proporcionadas.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
 La palabra más relevante para ‘reina’
La palabra más relevante para ‘reina’
Nuestro modelo es capaz de encontrar la relación perfecta entre palabras.
Definir lista de vocabulario:
Ahora, intentemos comprender el significado semántico o la relación entre palabras usando una trama. Defina la lista de palabras que desea visualizar.
# Define the list of words you want to visualize vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Crear matriz de incrustación:
Escribamos código para crear una matriz de incrustación.
# Your code for creating the embedding matrix
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Defina una función para la visualización t-SNE:
A partir de este código, definiremos la función para nuestro gráfico de visualización.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Veamos cómo se ve nuestra trama:
# Call the tsne_plot function with your embedding matrix and list of words tsne_plot(embedding_matrix, vocab)
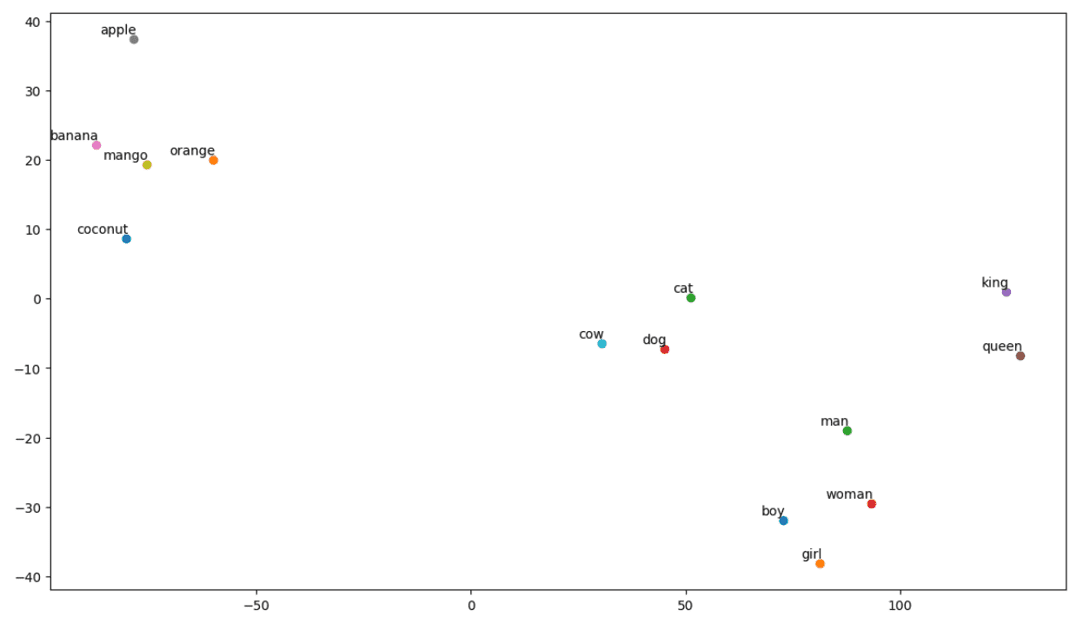 gráfico t-SNE
gráfico t-SNE
Entonces, como podemos ver, hay palabras como «plátano», «mango», «naranja», «coco» y «manzana» en el lado izquierdo de nuestra gráfica. Mientras que «vaca», «perro» y «gato» son similares entre sí porque son animales.
Entonces, ¡nuestro modelo también puede encontrar significados semánticos y relaciones entre palabras!
Con solo cambiar el vocabulario o crear tu modelo desde cero, puedes experimentar con diferentes palabras.
Puede utilizar esta matriz de incrustación como desee. Puede aplicarse solo a tareas de similitud de palabras o incorporarse a la capa de incrustación de una red neuronal.
GloVe se entrena en una matriz de coocurrencia para derivar significado semántico. Se basa en la idea de que las coocurrencias palabra-palabra son una pieza esencial de conocimiento y que su uso es una forma eficaz de utilizar estadísticas para producir incrustaciones de palabras. Así es como GloVe logra agregar “estadísticas globales” al producto final.
Y ese es GloVe; Otro método popular de vectorización es FastText. Discutamos más al respecto.
Texto rápido
FastText es una biblioteca de código abierto presentada por el equipo de investigación de inteligencia artificial de Facebook para clasificación de texto y análisis de sentimientos. FastText proporciona herramientas para entrenar la incrustación de palabras, que son palabras densas que representan vectores. Esto es útil para capturar el significado semántico del documento. FastText admite clasificación de múltiples etiquetas y múltiples clases.
¿Por qué texto rápido?
FastText es mejor que otros modelos debido a su capacidad de generalizar a palabras desconocidas, que faltaba en otros métodos. FastText proporciona vectores de palabras previamente entrenados para diferentes idiomas, lo que podría resultar útil en diversas tareas en las que necesitamos conocimientos previos sobre las palabras y su significado.
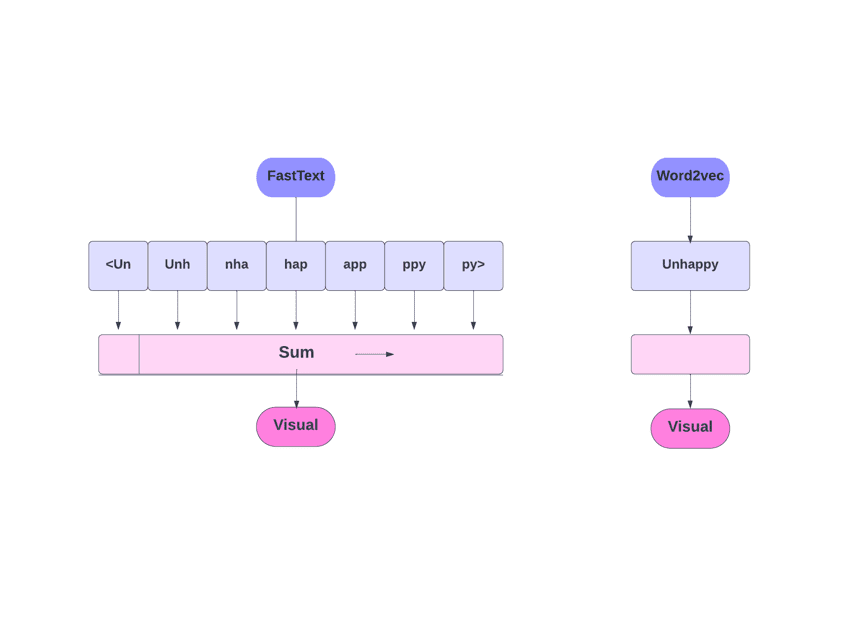 FastText y Word2Vec
FastText y Word2Vec
¿Como funciona?
Como comentamos, otros modelos, como Word2Vec y GloVe, usan palabras para incrustar palabras. Pero el componente básico de FastText son las letras en lugar de las palabras. Lo que significa que usan letras para incrustar palabras.
Usar caracteres en lugar de palabras tiene otra ventaja. Se necesitan menos datos para el entrenamiento. A medida que una palabra se convierte en su contexto, se puede extraer más información del texto.
La incrustación de Word obtenida a través de FastText es una combinación de incrustaciones de nivel inferior.
Ahora, veamos cómo FastText utiliza la información de las subpalabras.
Digamos que tenemos la palabra «lectura». Para esta palabra, los n-gramas de caracteres de longitud 3-6 se generarían de la siguiente manera:
- El principio y el final se indican entre paréntesis angulares.
- Se utiliza hash porque podría haber una gran cantidad de n-gramas; en lugar de aprender una incrustación para cada n-grama distinto, aprendemos incrustaciones B totales, donde B representa el tamaño del cubo. En el artículo original se utilizó el tamaño de cubo de 2 millones.
- Cada n-grama de carácter, como «eadi», se asigna a un número entero entre 1 y B usando esta función hash, y ese índice tiene la incrustación correspondiente.
- Al promediar estas incrustaciones de n-gramas constituyentes, se obtiene la incrustación de palabras completa.
- Incluso si este enfoque de hash resulta en colisiones, ayuda en gran medida a manejar el tamaño del vocabulario.
- La red utilizada en FastText es similar a Word2Vec. Al igual que allí, podemos entrenar FastText en dos modos: CBOW y skip-gram. Por lo tanto, no necesitamos repetir esa parte aquí nuevamente.
Puede entrenar su propio modelo o puede utilizar un modelo previamente entrenado. Usaremos un modelo previamente entrenado.
Primero, necesitas instalar FastText.
pip install fasttext
Usaremos un conjunto de datos que consta de textos conversacionales sobre algunos medicamentos y tenemos que clasificar esos textos en 3 tipos. Como con el tipo de drogas con las que están asociados.
 Conjunto de datos
Conjunto de datos
Ahora, para entrenar un modelo FastText en cualquier conjunto de datos, necesitamos preparar los datos de entrada en un formato determinado, que es:
__label__
Hagamos esto también para nuestro conjunto de datos.
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample="__label__"+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
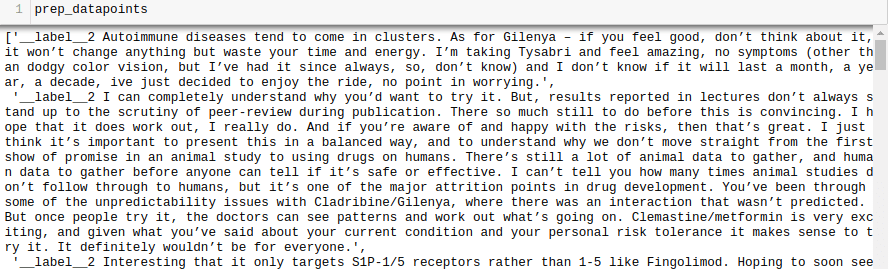 puntos_datos_prep
puntos_datos_prep
Omitimos mucho preprocesamiento en este paso. De lo contrario, nuestro artículo será demasiado extenso. En problemas del mundo real, es mejor realizar un preprocesamiento para que los datos sean aptos para el modelado.
Ahora, escriba los puntos de datos preparados en un archivo .txt.
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Entrenemos nuestro modelo.
model = fasttext.train_supervised('train_fasttext.txt')
Obtendremos predicciones de nuestro modelo.

El modelo predice la etiqueta y le asigna una puntuación de confianza.
Como ocurre con cualquier otro modelo, el rendimiento de este depende de una variedad de variables, pero si desea tener una idea rápida de cuál es la precisión esperada, FastText podría ser una excelente opción.
Conclusión
En conclusión, los métodos de vectorización de texto como Bag of Words (BoW), TF-IDF, Word2Vec, GloVe y FastText brindan una variedad de capacidades para tareas de PNL.
Mientras que Word2Vec captura la semántica de las palabras y se adapta a una variedad de tareas de PNL, BoW y TF-IDF son simples y adecuados para la clasificación y recomendación de textos.
Para aplicaciones como el análisis de sentimientos, GloVe ofrece incrustaciones previamente entrenadas y FastText funciona bien en el análisis a nivel de subpalabras, lo que lo hace útil para lenguajes estructuralmente ricos y reconocimiento de entidades.
La elección de la técnica depende de la tarea, los datos y los recursos. Discutiremos las complejidades de la PNL más profundamente a medida que avance esta serie. ¡Feliz aprendizaje!
A continuación, consulte los mejores cursos de PNL para aprender el procesamiento del lenguaje natural.