
Google JAX o Just After Execution es un marco desarrollado por Google para acelerar las tareas de aprendizaje automático.
Puede considerarlo una biblioteca para Python, que ayuda a una ejecución de tareas más rápida, computación científica, transformaciones de funciones, aprendizaje profundo, redes neuronales y mucho más.
Tabla de contenido
Acerca de Google JAX
El paquete de computación más fundamental en Python es el paquete NumPy que tiene todas las funciones como agregaciones, operaciones vectoriales, álgebra lineal, manipulaciones de matrices y arreglos n-dimensionales, y muchas otras funciones avanzadas.
¿Qué pasaría si pudiéramos acelerar aún más los cálculos realizados con NumPy, especialmente para grandes conjuntos de datos?
¿Tenemos algo que podría funcionar igual de bien en diferentes tipos de procesadores como GPU o TPU, sin cambios de código?
¿Qué tal si el sistema pudiera realizar transformaciones de funciones componibles de forma automática y más eficiente?
Google JAX es una biblioteca (o marco, como dice Wikipedia) que hace exactamente eso y quizás mucho más. Fue creado para optimizar el rendimiento y realizar de manera eficiente el aprendizaje automático (ML) y las tareas de aprendizaje profundo. Google JAX proporciona las siguientes características de transformación que lo hacen único de otras bibliotecas de ML y ayuda en el cálculo científico avanzado para el aprendizaje profundo y las redes neuronales:
- Diferenciación automática
- Vectorización automática
- Paralelización automática
- Compilación justo a tiempo (JIT)
Características únicas de Google JAX
Todas las transformaciones usan XLA (álgebra lineal acelerada) para un mayor rendimiento y optimización de la memoria. XLA es un motor compilador de optimización de dominio específico que realiza álgebra lineal y acelera los modelos de TensorFlow. ¡Usar XLA sobre su código Python no requiere cambios significativos en el código!
Exploremos en detalle cada una de estas características.
Características de Google JAX
Google JAX viene con importantes funciones de transformación componibles para mejorar el rendimiento y realizar tareas de aprendizaje profundo de manera más eficiente. Por ejemplo, diferenciación automática para obtener el gradiente de una función y encontrar derivadas de cualquier orden. Del mismo modo, paralelización automática y JIT para realizar múltiples tareas en paralelo. Estas transformaciones son clave para aplicaciones como la robótica, los juegos e incluso la investigación.
Una función de transformación componible es una función pura que transforma un conjunto de datos en otra forma. Se denominan componibles porque son autónomos (es decir, estas funciones no tienen dependencias con el resto del programa) y no tienen estado (es decir, la misma entrada siempre dará como resultado la misma salida).
Y(x) = T: (f(x))
En la ecuación anterior, f(x) es la función original sobre la que se aplica una transformación. Y(x) es la función resultante después de aplicar la transformación.
Por ejemplo, si tiene una función llamada ‘total_bill_amt’ y desea que el resultado sea una transformación de función, simplemente puede usar la transformación que desee, digamos gradiente (grad):
grad_total_bill = grad(total_bill_amt)
Al transformar funciones numéricas usando funciones como grad(), podemos obtener fácilmente sus derivados de orden superior, que podemos usar ampliamente en algoritmos de optimización de aprendizaje profundo como el descenso de gradiente, lo que hace que los algoritmos sean más rápidos y eficientes. De manera similar, al usar jit(), podemos compilar programas de Python justo a tiempo (perezosamente).
#1. Diferenciación automática
Python usa la función autograd para diferenciar automáticamente NumPy y el código nativo de Python. JAX usa una versión modificada de autograd (es decir, grad) y combina XLA (Álgebra lineal acelerada) para realizar diferenciación automática y encontrar derivados de cualquier orden para GPU (Unidades de procesamiento gráfico) y TPU (Unidades de procesamiento tensorial).]
Nota rápida sobre TPU, GPU y CPU: la CPU o unidad central de procesamiento administra todas las operaciones en la computadora. La GPU es un procesador adicional que mejora la potencia informática y ejecuta operaciones de alto nivel. TPU es una unidad poderosa desarrollada específicamente para cargas de trabajo complejas y pesadas como IA y algoritmos de aprendizaje profundo.
En la misma línea que la función autograd, que puede diferenciar a través de bucles, recursiones, ramas, etc., JAX usa la función grad() para gradientes en modo inverso (propagación hacia atrás). Además, podemos diferenciar una función a cualquier orden usando grad:
grado(grado(grado(sen θ))) (1.0)
Diferenciación automática de orden superior
Como mencionamos antes, grad es bastante útil para encontrar las derivadas parciales de una función. Podemos usar una derivada parcial para calcular el descenso del gradiente de una función de costo con respecto a los parámetros de la red neuronal en el aprendizaje profundo para minimizar las pérdidas.
Cálculo de derivadas parciales
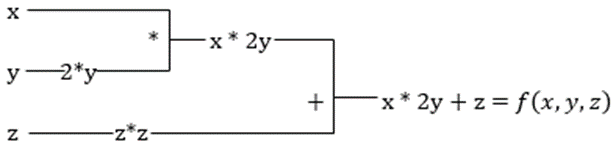
Supongamos que una función tiene múltiples variables, x, y y z. Encontrar la derivada de una variable manteniendo las otras variables constantes se llama derivada parcial. Supongamos que tenemos una función,
f(x,y,z) = x + 2y + z2
Ejemplo para mostrar derivada parcial
La derivada parcial de x será ∂f/∂x, que nos dice cómo cambia una función para una variable cuando las demás son constantes. Si hacemos esto manualmente, debemos escribir un programa para diferenciar, aplicarlo para cada variable y luego calcular el descenso del gradiente. Esto se convertiría en un asunto complejo y lento para múltiples variables.
La diferenciación automática descompone la función en un conjunto de operaciones elementales, como +, -, *, / o sin, cos, tan, exp, etc., y luego aplica la regla de la cadena para calcular la derivada. Podemos hacer esto tanto en modo de avance como de retroceso.
¡Esto no lo es! Todos estos cálculos ocurren muy rápido (bueno, ¡piense en un millón de cálculos similares a los anteriores y el tiempo que puede tomar!). XLA se encarga de la velocidad y el rendimiento.
#2. Álgebra lineal acelerada
Tomemos la ecuación anterior. Sin XLA, el cálculo tomará tres (o más) kernels, donde cada kernel realizará una tarea más pequeña. Por ejemplo,
Núcleo k1 –> x * 2y (multiplicación)
k2 –> x * 2y + z (suma)
k3 –> Reducción
Si XLA realiza la misma tarea, un solo kernel se encarga de todas las operaciones intermedias fusionándolas. Los resultados intermedios de las operaciones elementales se transmiten en lugar de almacenarlos en la memoria, lo que ahorra memoria y mejora la velocidad.
#3. Compilación justo a tiempo
JAX utiliza internamente el compilador XLA para aumentar la velocidad de ejecución. XLA puede aumentar la velocidad de la CPU, la GPU y la TPU. Todo esto es posible utilizando la ejecución de código JIT. Para usar esto, podemos usar jit vía import:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Otra forma es decorando jit sobre la definición de la función:
@jit def my_function(x): …………some lines of code
Este código es mucho más rápido porque la transformación devolverá la versión compilada del código a la persona que llama en lugar de usar el intérprete de Python. Esto es particularmente útil para entradas de vectores, como arreglos y matrices.
Lo mismo es cierto para todas las funciones de python existentes. Por ejemplo, funciones del paquete NumPy. En este caso, deberíamos importar jax.numpy como jnp en lugar de NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Una vez que haga esto, el objeto de matriz JAX central llamado DeviceArray reemplaza la matriz NumPy estándar. DeviceArray es perezoso: los valores se mantienen en el acelerador hasta que se necesitan. Esto también significa que el programa JAX no espera a que los resultados regresen al programa de llamada (Python), siguiendo así un envío asíncrono.
#4. Vectorización automática (vmap)
En un mundo típico de aprendizaje automático, tenemos conjuntos de datos con un millón o más puntos de datos. Lo más probable es que realicemos algunos cálculos o manipulaciones en cada uno o la mayoría de estos puntos de datos, ¡lo cual es una tarea que consume mucho tiempo y memoria! Por ejemplo, si desea encontrar el cuadrado de cada uno de los puntos de datos en el conjunto de datos, lo primero que pensaría es crear un ciclo y tomar el cuadrado uno por uno, ¡argh!
Si creamos estos puntos como vectores, podríamos hacer todos los cuadrados de una sola vez realizando manipulaciones de vectores o matrices en los puntos de datos con nuestro NumPy favorito. Y si su programa pudiera hacer esto automáticamente, ¿puede pedir algo más? ¡Eso es exactamente lo que hace JAX! Puede vectorizar automáticamente todos sus puntos de datos para que pueda realizar fácilmente cualquier operación en ellos, lo que hace que sus algoritmos sean mucho más rápidos y eficientes.
JAX usa la función vmap para la vectorización automática. Considere la siguiente matriz:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Al hacer lo anterior, el método cuadrado se ejecutará para cada punto de la matriz. Pero si haces lo siguiente:
vmap(jnp.square(x))
El cuadrado del método se ejecutará solo una vez porque los puntos de datos ahora se vectorizan automáticamente usando el método vmap antes de ejecutar la función, y el bucle se reduce al nivel elemental de operación, lo que da como resultado una multiplicación matricial en lugar de una multiplicación escalar, lo que brinda un mejor rendimiento. .
#5. Programación SPMD (pmap)
SPMD, o la programación de datos múltiples de programa único es esencial en contextos de aprendizaje profundo; a menudo aplicaría las mismas funciones en diferentes conjuntos de datos que residen en múltiples GPU o TPU. JAX tiene una función llamada bomba, que permite la programación paralela en múltiples GPU o cualquier acelerador. Al igual que JIT, los programas que usan pmap serán compilados por XLA y ejecutados simultáneamente en todos los sistemas. Esta paralelización automática funciona tanto para cálculos directos como inversos.
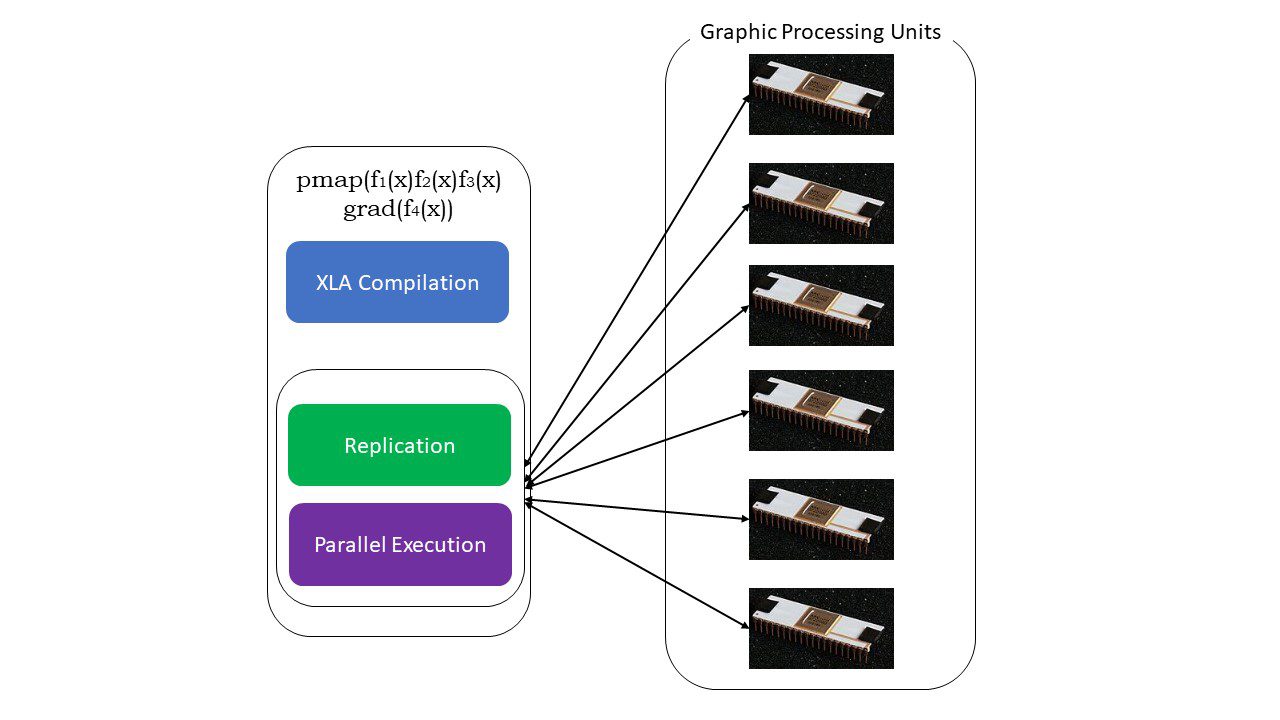 ¿Cómo funciona pmap?
¿Cómo funciona pmap?
También podemos aplicar múltiples transformaciones de una sola vez en cualquier orden en cualquier función como:
pmap(vmap(jit(graduado(f(x)))))
Múltiples transformaciones componibles
Limitaciones de Google JAX
Los desarrolladores de Google JAX han pensado bien en acelerar los algoritmos de aprendizaje profundo al tiempo que introducen todas estas impresionantes transformaciones. Las funciones y los paquetes de computación científica están en la línea de NumPy, por lo que no tiene que preocuparse por la curva de aprendizaje. Sin embargo, JAX tiene las siguientes limitaciones:
- Google JAX aún se encuentra en las primeras etapas de desarrollo y, aunque su objetivo principal es la optimización del rendimiento, no brinda muchos beneficios para la computación de la CPU. NumPy parece funcionar mejor, y el uso de JAX solo puede aumentar la sobrecarga.
- JAX aún se encuentra en su investigación o en sus primeras etapas y necesita más ajustes para alcanzar los estándares de infraestructura de marcos como TensorFlow, que están más establecidos y tienen más modelos predefinidos, proyectos de código abierto y material de aprendizaje.
- A partir de ahora, JAX no es compatible con el sistema operativo Windows; necesitaría una máquina virtual para que funcione.
- JAX funciona solo en funciones puras, las que no tienen efectos secundarios. Para funciones con efectos secundarios, JAX puede no ser una buena opción.
Cómo instalar JAX en su entorno de Python
Si tiene una configuración de python en su sistema y desea ejecutar JAX en su máquina local (CPU), use los siguientes comandos:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Si desea ejecutar Google JAX en una GPU o TPU, siga las instrucciones proporcionadas en GitHub JAX página. Para configurar Python, visite el descargas oficiales de python página.
Conclusión
Google JAX es excelente para escribir algoritmos eficientes de aprendizaje profundo, robótica e investigación. A pesar de las limitaciones, se usa ampliamente con otros marcos como Haiku, Flax y muchos más. Podrá apreciar lo que hace JAX cuando ejecuta programas y ver las diferencias de tiempo en la ejecución de código con y sin JAX. Puedes empezar leyendo el documentación oficial de Google JAXque es bastante completo.