Averigüemos cómo puede mantener su producción confiable con la ayuda de las herramientas de Chaos Engineering.
La ingeniería del caos es una disciplina en la que experimenta en su sistema o aplicación para revelar sus debilidades y fallas de capacidad. Esto es algo que no pensaste que podría suceder mientras lo creabas. Por lo tanto, causaría algunas fallas a propósito en su sistema para mostrar sus debilidades para hacer las correcciones y hacer que su sistema y su aplicación sean más resistentes.
Muchas organizaciones populares como Netflix, LinkedIn y Facebook realizan ingeniería del caos para comprender mejor su arquitectura de microservicios y sistemas distribuidos. Ayuda a encontrar nuevos problemas antes que las quejas de los usuarios reales y a tomar las medidas necesarias para corregirlos. Así es como estas organizaciones pueden atender a millones de usuarios, aumentar su productividad y ahorrar millones de dólares 🤑.
Beneficios de la ingeniería del caos:
- Controle las pérdidas de ingresos encontrando problemas críticos
- Reducción de fallas en el sistema o la aplicación
- Mejor experiencia de usuario con menos interrupciones y alta disponibilidad del servicio
- Le ayuda a aprender sobre el sistema y ganar confianza.
¿Qué confianza tiene en la confiabilidad de su producción? ¿Es realmente a prueba de desastres?
Averigüémoslo con la ayuda de las siguientes herramientas populares de prueba de caos.
Tabla de contenido
Malla del caos
Malla del caos es una solución de gestión de ingeniería del caos que inyecta fallas en cada capa de un sistema Kubernetes. Esto incluye los pods, la red, la E/S del sistema y el kernel. Chaos Mesh puede matar automáticamente los pods de Kubernetes y simular latencias. Puede interrumpir la comunicación de pod a pod y simular errores de lectura/escritura. Puede programar reglas para los experimentos y definir su alcance. Estos experimentos se especifican mediante archivos YAML.
Chaos Mesh tiene un tablero para ver análisis de experimentos. Se ejecuta sobre Kubernetes y es compatible con la mayoría de la plataforma en la nube. Es de código abierto y recientemente fue aceptado como un proyecto sandbox CNCF. Con los principios de la ingeniería del caos, puede agregar Chaos Mesh a su flujo de trabajo de DevOps para crear aplicaciones resilientes.
Características de la ingeniería del caos:
- Fácilmente implementable en clústeres de Kubernetes sin modificar la lógica de implementación
- No se requieren dependencias únicas para la implementación
- Define objetos de caos usando CustomResourceDefinitions (CRD)
- Proporciona un panel para realizar un seguimiento de todos los experimentos.
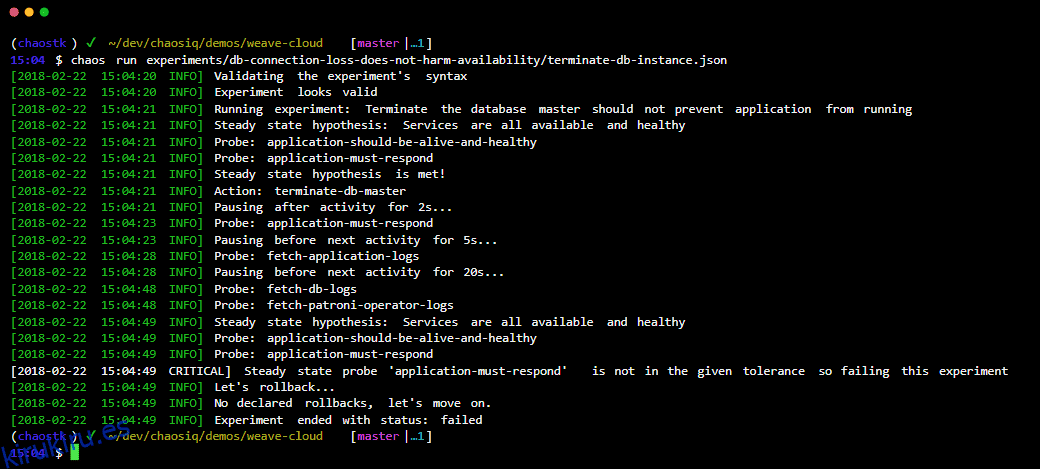
Kit de herramientas del caos es una herramienta sencilla y de código abierto para la automatización de experimentos de ingeniería del caos.
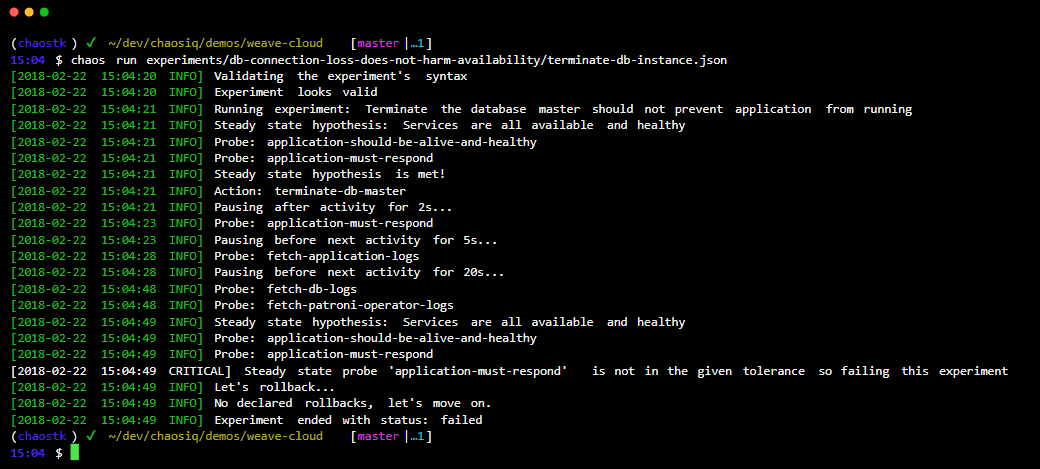
Integra Chaos ToolKit con su sistema utilizando un conjunto de controladores o complementos que admite AWS, Google Cloud, Slack, Prometheus, etc.
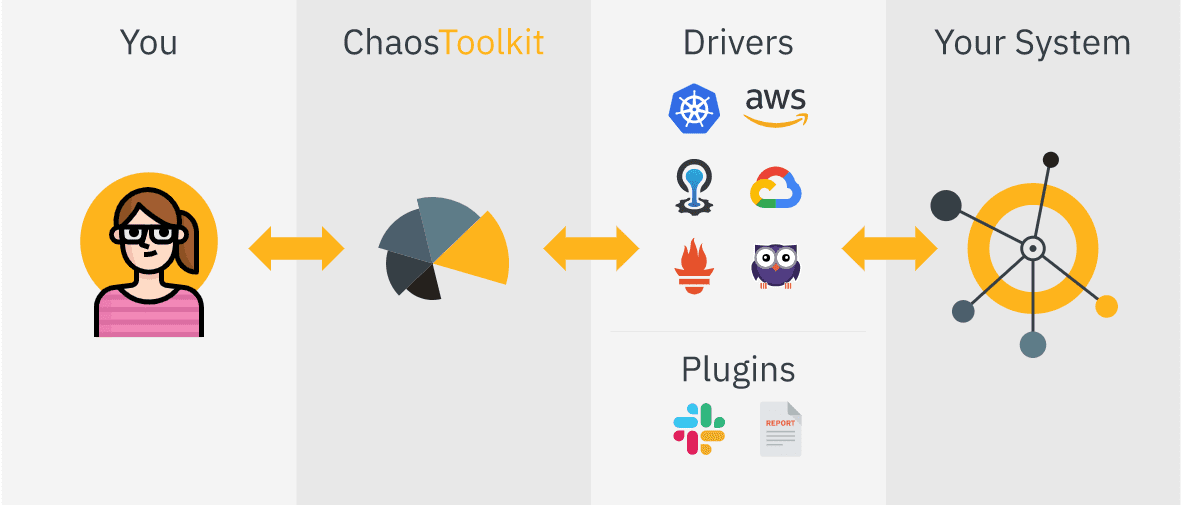
Características de Chaos ToolKit:
- Proporciona API abierta declarativa para crear experimentos de caos independientes de un proveedor o tecnología
- Se puede integrar fácilmente en tuberías CICD para la automatización
- Brinda apoyo comercial y empresarial también a través de CaosIQ
caoskube
Como puede adivinar por el nombre, es para Kubernetes.
Caoskube es una herramienta de caos de código abierto que elimina periódicamente pods aleatorios en el clúster de Kubernetes. Le ayuda a comprender cómo reaccionará su sistema cuando falle el pod. De forma predeterminada, mata un pod en cualquier espacio de nombres cada 10 minutos. Puede filtrar los pods de destino en Chaoskube usando espacios de nombres, etiquetas, anotaciones, etc. Se puede instalar fácilmente usando Chaoskube.

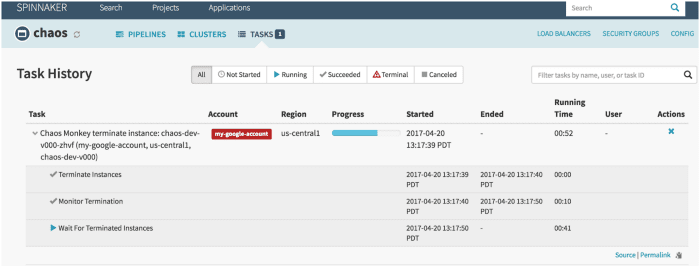
Mono del caos
Mono del caos es una herramienta que se utiliza para comprobar la resiliencia de los sistemas en la nube creando fallos a propósito para que esos sistemas comprendan su reacción. Netflix lo creó para probar la resiliencia y la capacidad de recuperación de su infraestructura de AWS. Fue llamado Chaos Monkey porque crea destrucción como un mono salvaje y armado para probar las fallas.
Además, fue Chaos Monkey, que dio origen a la nueva práctica de ingeniería Chaos Engineering. Fue creado sobre el principio de que es mejor fallar repetidamente para evitar cualquier falla significativa de repente.
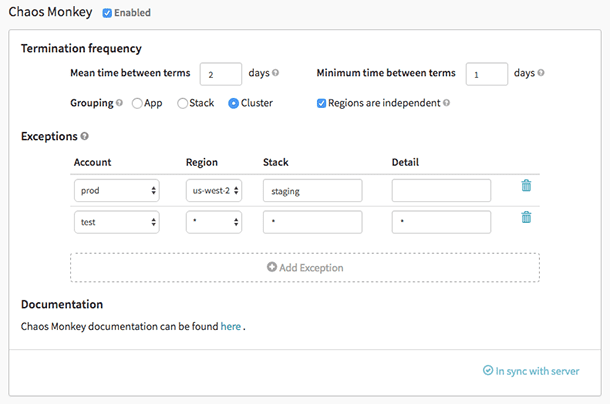
Características del mono del caos:
- Le ayuda a prepararse para fallas de instancias aleatorias.
- Fomenta la redundancia para fallas inesperadas
- Utiliza Spinnaker para habilitar la compatibilidad entre nubes
- Proporciona un programa configurable para simular fallas
- Integrado con gobernador para agregar nuevas dependencias al mono del caos
Simmy
Simmy es una herramienta de caos de inyección de fallas que se integra con el proyecto de resiliencia Polly para .NET. Le permite crear políticas de inyección de caos a través de Polly, donde ejecuta sus códigos. Ofrece diferentes políticas, como la política de excepciones para inyectar excepciones en el sistema, la política de comportamiento para inyectar cualquier comportamiento nuevo, etc. Estas políticas están diseñadas para inyectar el comportamiento de forma aleatoria.
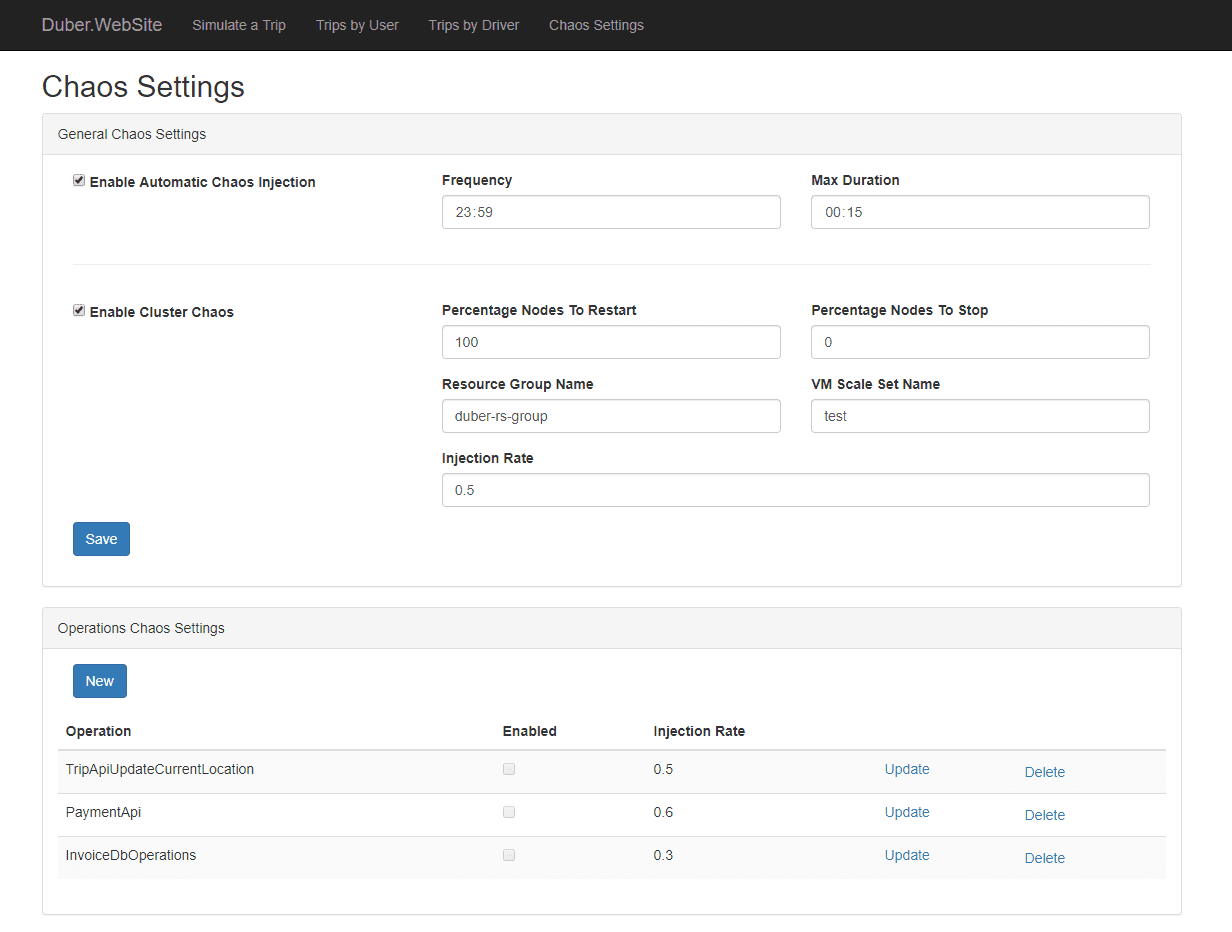
Características de Simmy:
- Proporciona políticas de mono o políticas de caos para inyectar caos.
- Fácil de probar cualquier falla de dependencia
- Ayuda a volver rápidamente al modelo de trabajo y controla el radio de explosión.
- Está listo para producción.
- También puede definir fallas basadas en factores externos (por ejemplo, fallas debido a la configuración global)
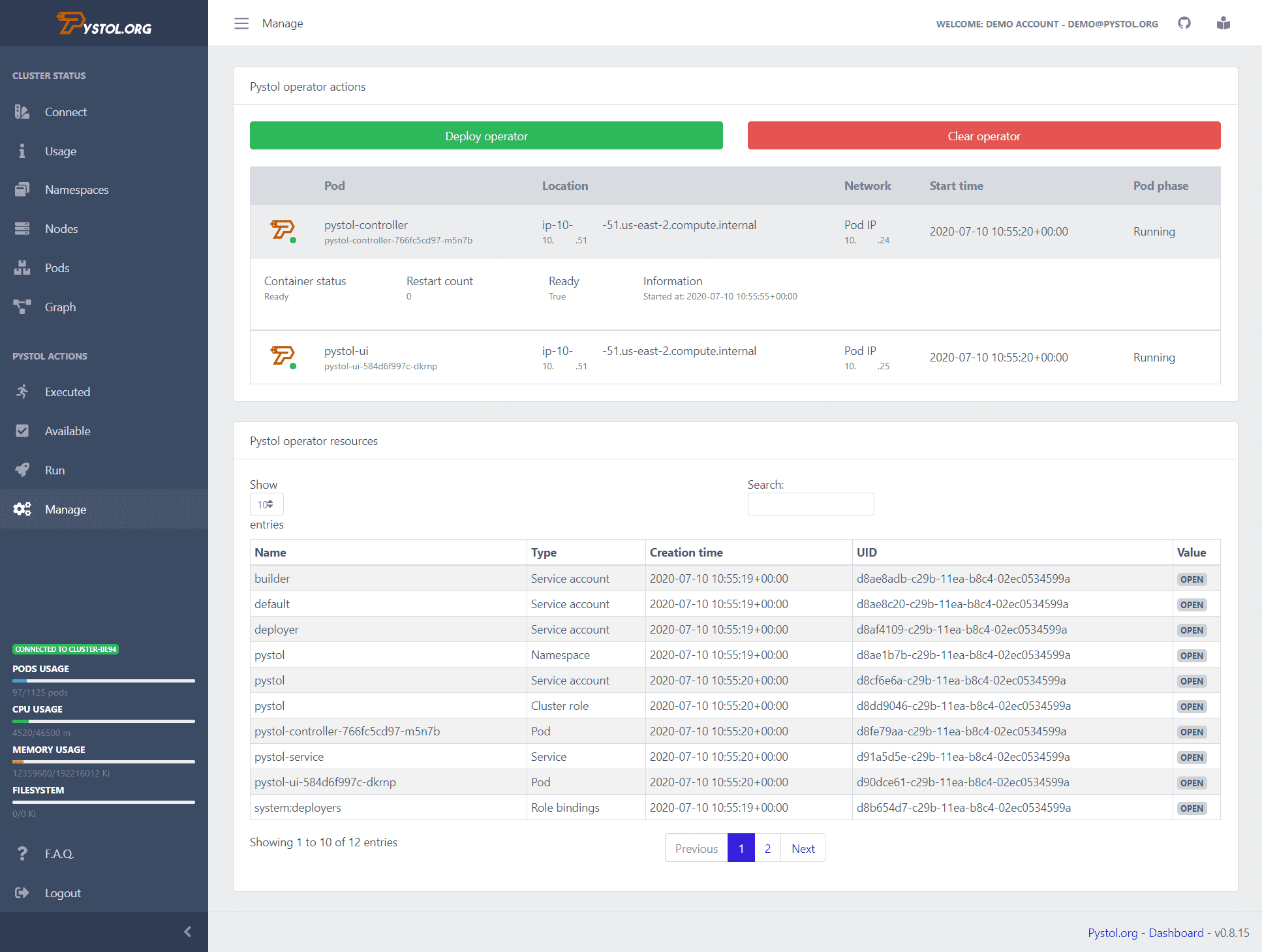
pistola
pistola es una herramienta que se utiliza para inyectar inyecciones defectuosas en entornos nativos de la nube. Vigila eventos en el ETCD a través de operadores de Kubernetes. Cuando se ejecuta una acción de inyección de errores, los operadores crean los pods y ejecutan algunas recopilaciones de Ansible. Por lo tanto, los desarrolladores no necesitan escribir sus propias acciones para realizarlas.
Pystol proporciona acciones preparadas para probar el sistema. Aún así, si un desarrollador quiere crear una nueva acción, puede hacerlo usando GoLang y Python.
Proporciona un panel de control de integración continua para brindar una vista resumida de todas las operaciones de trabajo. Puede ejecutar Pystol localmente o implementarlo en un contenedor utilizando su imagen acoplable. Pystol proporciona dos interfaces, una es la interfaz de usuario web y la otra es a través de la CLI. Obviamente, la interfaz de usuario web es una mejor opción.
Muxy
Muxy es un proxy para probar sus patrones de resiliencia y tolerancia a fallas para fallas de sistemas distribuidos del mundo real. Puede alterar el nivel de transporte (capa 4), el nivel de sesión TCP (capa 5) y el nivel de protocolo HTTP (capa 7).
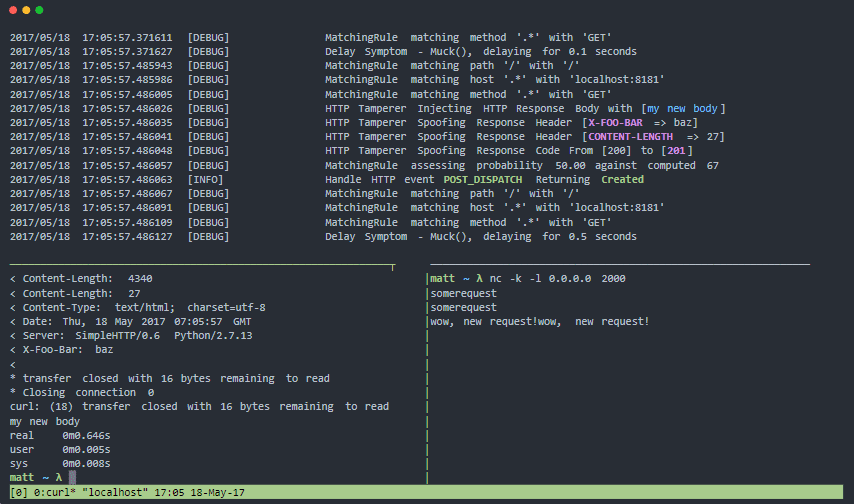
Muxy caracteristicas:
- Arquitectura modular y fácilmente extensible
- Tiene contenedor docker oficial
- Fácil de instalar, no requiere dependencias.
- Ideal para pruebas continuas de resiliencia.
- Simula problemas de conectividad de red para sistemas distribuidos y dispositivos móviles
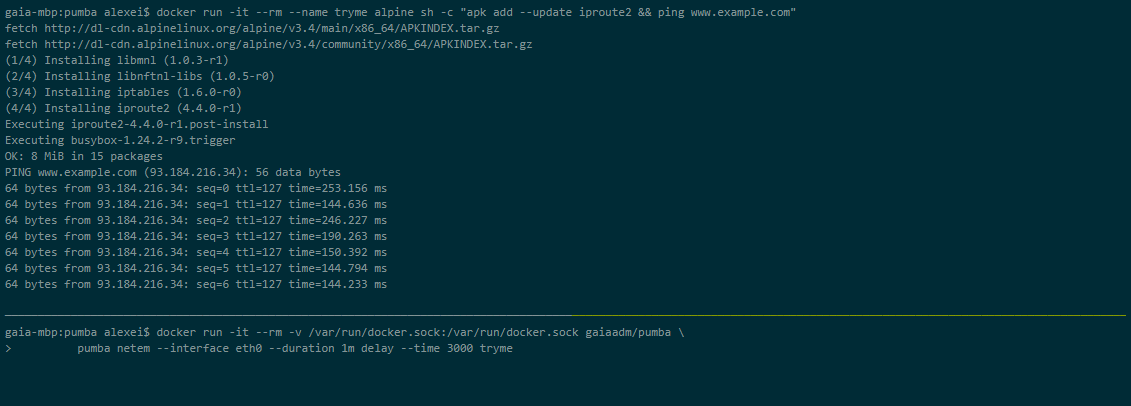
Pumba
Pumba es una herramienta de línea de comandos que realiza pruebas de caos para contenedores docker. Con Pumba, bloquea deliberadamente los contenedores acoplables de la aplicación para ver cómo reacciona el sistema. También puede realizar pruebas de estrés en los recursos del contenedor, como CPU, memoria, sistema de archivos, entrada/salida, etc.
También puede ejecutar Pumba en un clúster de Kubernetes. Debe usar DaemonSets para implementar Pumba en los nodos de Kubernetes. Puede usar varios contenedores de Pumba para ejecutar varios comandos de Pumba en el mismo DaemonSet.
ChaosBlade
ChaosBlade es una herramienta de código abierto para inyectar experimentos en los sistemas de Alibaba. Pone a prueba todas las fallas a las que se ha enfrentado Alibaba en los últimos diez años y aplica las mejores prácticas para evitarlas. Sigue los principios de ingeniería del caos para verificar la tolerancia a fallas de los sistemas distribuidos.
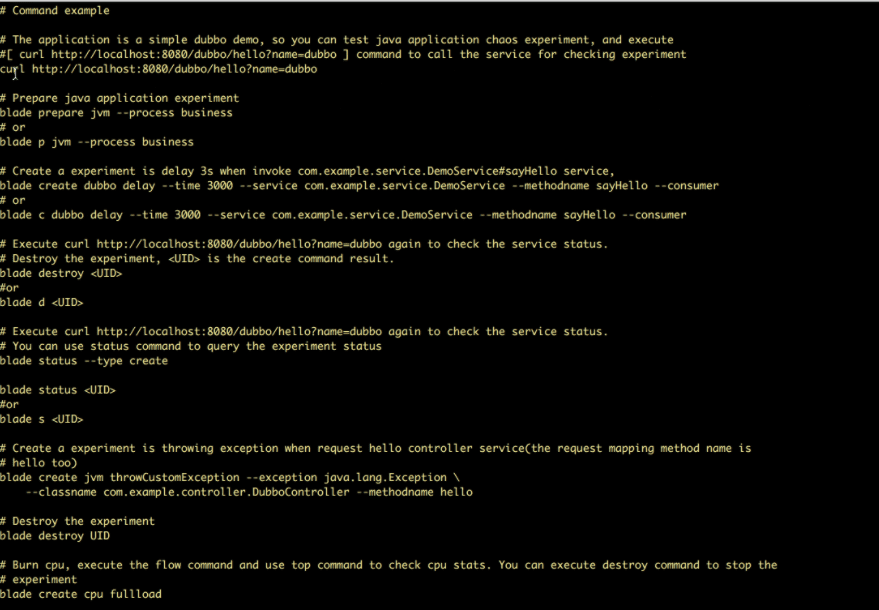
Características de ChaosBlade:
- Proporciona escenarios experimentales para múltiples recursos como CPU, red, memoria, disco, etc.
- Proporciona escenarios experimentales para nodos, redes y pods en la plataforma Kubernetes
- Proporciona comandos CLI fáciles de usar para ejecutar experimentos
Tornasol
Tornasol sigue los principios de ingeniería del caos nativos de la nube. La misión de la herramienta litmus es ofrecer un marco completo para encontrar debilidades en sus sistemas Kubernetes y sus aplicaciones en ejecución en Kubernetes.
Tiene un operador de caos y los CRD (CustomResourceDefinitions) alrededor de eso, lo que permite la capacidad plug-and-play. Se trata de poner la lógica del caos en una imagen acoplable, colocarla en un marco tornasol y orquestarla mediante los CRD.

Características del tornasol:
- Ayuda a los ingenieros y desarrolladores de Site Reliability a encontrar debilidades en el sistema Kubernetes
- Proporciona experimentos genéricos listos para usar
- Proporciona Chaos API para la gestión del flujo de trabajo del caos
- Litmus SDK es compatible con Go, Python y Ansible para crear sus propios experimentos.
Duendecillo
Duendecillo ayuda a los ingenieros a crear software más resistente. Proporciona una plataforma para ejecutar experimentos de ingeniería del caos de forma segura y sencilla.

Puede inyectar fallas cuidadosamente en hosts o contenedores con gremlin independientemente de dónde se encuentren, ya sea en la nube pública o en su propio centro de datos.
Características de Gremlin:
- Instala un agente ligero en sus hosts o contenedores para inyectar fallas
- Proporciona más de 10 modos de ataque de infraestructura diferentes
- Los gremlins estatales le permiten manipular la hora del sistema, apagar o reiniciar hosts y eliminar procesadores.
- Los gremlins de la red pueden inyectar latencia para introducir la pérdida de paquetes o eliminar el tráfico.
- Los ataques a la biblioteca Alfi de Gremlin se pueden configurar, iniciar y detener a través de la aplicación web. API o CLI
- Le permite apuntar al radio de explosión que desea atacar con precisión
- Le permite detener todos los ataques y hacer que el sistema vuelva a un estado estable
Steadybit
Steadybit tiene como objetivo reducir el tiempo de inactividad de forma proactiva y proporciona visibilidad de los problemas del sistema. Puede ejecutar esta herramienta localmente en su infraestructura o en la nube como servicio (SaaS).
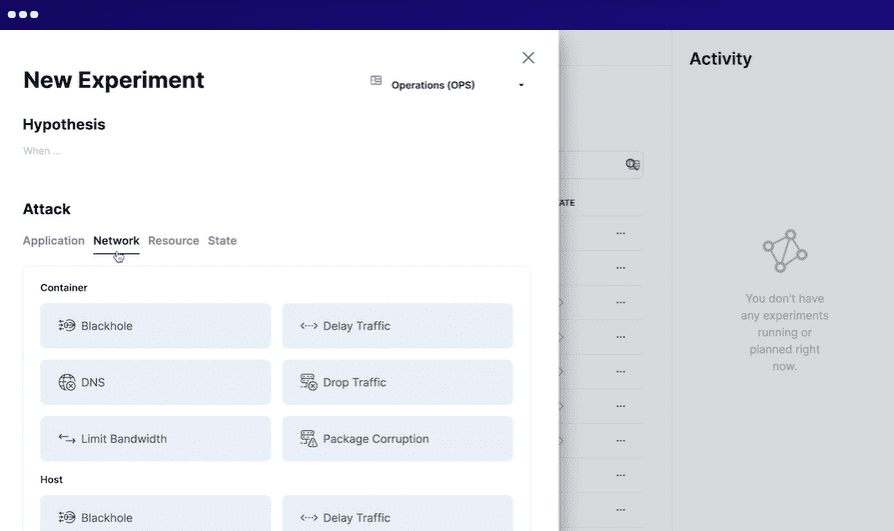
Para usar Steadybit, usted define la situación, simula los experimentos, ejecuta los experimentos simulados en producción y automatiza todos los experimentos. Ejecuta agentes inteligentes en su sistema para descubrir posibles problemas y debilidades. Se integra con múltiples sistemas con facilidad.
Conclusión
Continúe y sea lo suficientemente valiente como para aplicar los principios de ingeniería del caos y pruebe su producción con las herramientas mencionadas anteriormente. Estas herramientas lo ayudarán a encontrar múltiples debilidades no identificadas en su sistema y lo ayudarán a hacer que su sistema sea más resistente.