
Si es nuevo en el análisis de big data, la gran cantidad de herramientas de Apache podría estar en su radar; sin embargo, la variedad de herramientas diferentes puede volverse confusa y, a veces, abrumadora.
¡Esta publicación resolverá esta confusión y explicará qué son Apache Hive e Impala y qué los hace diferentes entre sí!
Tabla de contenido
colmena apache
Apache Hive es una interfaz de acceso a datos SQL para la plataforma Apache Hadoop. Hive le permite consultar, agregar y analizar datos utilizando la sintaxis SQL.
Se utiliza un esquema de acceso de lectura para los datos en el sistema de archivos HDFS, lo que le permite tratar los datos como si fueran una tabla ordinaria o un DBMS relacional. Las consultas de HiveQL se traducen a código Java para los trabajos de MapReduce.
Las consultas de Hive se escriben en el lenguaje de consulta de HiveQL, que se basa en el lenguaje SQL pero no es totalmente compatible con el estándar SQL-92.
Sin embargo, este lenguaje permite a los programadores usar sus consultas cuando es inconveniente o ineficiente usar las características de HiveQL. HiveQL se puede ampliar con funciones escalares definidas por el usuario (UDF), agregaciones (códigos UDAF) y funciones de tabla (UDTF).
¿Cómo funciona Apache Hive?
Apache Hive traduce programas escritos en lenguaje HiveQL (cercano a SQL) en una o más tareas de MapReduce, Apache Tez o Apache Spark. Estos son tres motores de ejecución que se pueden ejecutar en Hadoop. Luego, Apache Hive organiza los datos en una matriz para que el archivo del sistema de archivos distribuidos de Hadoop (HDFS) ejecute los trabajos en un clúster para producir una respuesta.
Las tablas de Apache Hive son similares a las bases de datos relacionales y las unidades de datos se organizan desde la unidad más significativa hasta la más granular. Las bases de datos son matrices compuestas por particiones, que nuevamente se pueden dividir en «cubos».
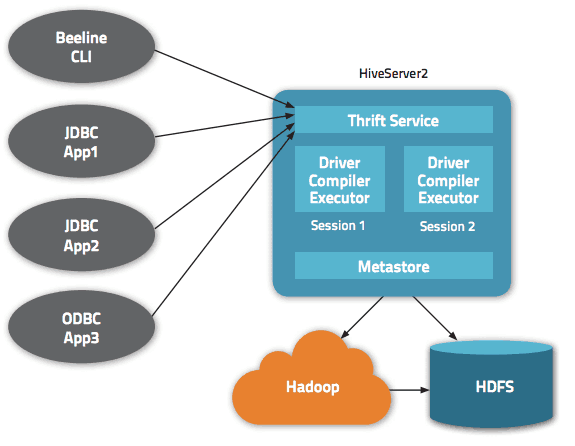
Se puede acceder a los datos a través de HiveQL. Dentro de cada base de datos, los datos están numerados y cada tabla corresponde a un directorio HDFS.
Hay varias interfaces disponibles dentro de la arquitectura de Apache Hive, como la interfaz web, CLI o clientes externos.
De hecho, el servidor «Apache Hive Thrift» permite a los clientes remotos enviar comandos y solicitudes a Apache Hive utilizando varios lenguajes de programación. El directorio central de Apache Hive es un «metastore» que contiene toda la información.
El motor que hace que Hive funcione se llama «el controlador». Incluye un compilador y un optimizador para determinar el plan de ejecución óptimo.
Finalmente, la seguridad la proporciona Hadoop. Por lo tanto, se basa en Kerberos para la autenticación mutua entre el cliente y el servidor. HDFS dicta el permiso para los archivos recién creados en Apache Hive, lo que permite la autorización de usuario, grupo o de otro tipo.
Características de la colmena
- Admite el motor informático de Hadoop y Spark
- Utiliza HDFS y funciona como almacén de datos.
- Utiliza MapReduce y es compatible con ETL
- Debido a HDFS, tiene una tolerancia a fallas similar a Hadoop
Colmena Apache: Beneficios
Apache Hive es una solución ideal para consultas y análisis de datos. Permite obtener insights cualitativos, proporcionando una ventaja competitiva y facilitando la capacidad de respuesta a la demanda del mercado.
Entre las principales ventajas de Apache Hive, podemos mencionar la facilidad de uso ligada a su lenguaje “SQL-friendly”. Además, acelera la inserción inicial de datos ya que no es necesario leer o numerar los datos desde un disco en el formato de la base de datos interna.
Sabiendo que los datos se almacenan en HDFS, es posible almacenar grandes conjuntos de datos de hasta cientos de petabytes de datos en Apache Hive. Esta solución es mucho más escalable que una base de datos tradicional. Sabiendo que es un servicio en la nube, Apache Hive permite a los usuarios lanzar rápidamente servidores virtuales en función de las fluctuaciones en las cargas de trabajo (es decir, las tareas).
La seguridad también es un aspecto en el que Hive funciona mejor, con su capacidad para replicar cargas de trabajo críticas para la recuperación en caso de que surja un problema. Por último, la capacidad de trabajo es inigualable ya que puede realizar hasta 100.000 solicitudes por hora.
apache impala
Apache Impala es un motor de consulta SQL masivamente paralelo para la ejecución interactiva de consultas SQL sobre datos almacenados en Apache Hadoop, escrito en C++ y distribuido bajo la licencia Apache 2.0.
Impala también se conoce como motor MPP (Massively Parallel Processing), un DBMS distribuido e incluso una base de datos de pila SQL-on-Hadoop.

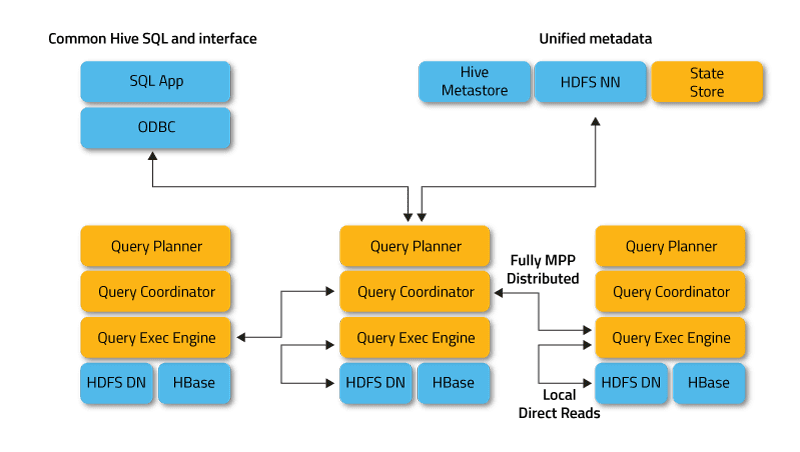
Impala opera en modo distribuido, donde las instancias de proceso se ejecutan en diferentes nodos de clúster, recibiendo, programando y coordinando las solicitudes de los clientes. En este caso, es posible la ejecución paralela de fragmentos de la consulta SQL.
Los clientes son usuarios y aplicaciones que envían consultas SQL contra datos almacenados en Apache Hadoop (HBase y HDFS) o Amazon S3. La interacción con Impala se produce a través de la interfaz web HUE (Experiencia de usuario de Hadoop), ODBC, JDBC y el shell de línea de comandos de Impala Shell.
Impala depende estructuralmente de otra popular herramienta SQL-on-Hadoop, Apache Hive, que utiliza su almacén de metadatos. En particular, Hive Metastore le permite a Impala conocer la disponibilidad y la estructura de las bases de datos.
Al crear, modificar y eliminar objetos de esquema o cargar datos en tablas a través de instrucciones SQL, los cambios de metadatos correspondientes se propagan automáticamente a todos los nodos de Impala utilizando un servicio de directorio especializado.
Los componentes clave de Impala son los siguientes ejecutables:
- Impalad o Impala daemon es un servicio del sistema que programa y ejecuta consultas en datos de HDFS, HBase y Amazon S3. Un proceso impalad se ejecuta en cada nodo del clúster.
- Statestore es un servicio de nombres que realiza un seguimiento de la ubicación y el estado de todas las instancias de Impalad en el clúster. Una instancia de este servicio del sistema se ejecuta en cada nodo y en el servidor principal (Nodo de nombre).
- El catálogo es un servicio de coordinación de metadatos que propaga los cambios de las instrucciones DDL y DML de Impala a todos los nodos de Impala afectados para que las tablas nuevas o los datos recién cargados sean inmediatamente visibles para cualquier nodo del clúster. Se recomienda que una instancia de Catalog se ejecute en el mismo host de clúster que el demonio Statestored.
¿Cómo funciona Apache Impala?
Impala, como Apache Hive, usa un lenguaje de consulta declarativo similar, Hive Query Language (HiveQL), que es un subconjunto de SQL92, en lugar de SQL.
La ejecución real de la solicitud en Impala es la siguiente:
La aplicación cliente envía una consulta SQL conectándose a cualquier impalad a través de interfaces de controlador ODBC o JDBC estandarizadas. El impalad conectado se convierte en el coordinador de la solicitud actual.
La consulta SQL se analiza para determinar las tareas para las instancias de impalad en el clúster; luego, se construye el plan óptimo de ejecución de consultas.
Impalad accede directamente a HDFS y HBase utilizando instancias locales de servicios del sistema para proporcionar datos. A diferencia de Apache Hive, esta interacción directa ahorra significativamente el tiempo de ejecución de las consultas, ya que los resultados intermedios no se guardan.
En respuesta, cada daemon devuelve datos al impalad coordinador y envía los resultados al cliente.
caracteristicas de impala
- Soporte para procesamiento en memoria en tiempo real
- compatible con SQL
- Admite sistemas de almacenamiento como HDFS, Apache HBase y Amazon S3
- Admite la integración con herramientas de BI como Pentaho y Tableau
- Utiliza la sintaxis de HiveQL
Apache Impala: Beneficios
Impala evita la posible sobrecarga de inicio porque todos los procesos del daemon del sistema se inician directamente en el momento del inicio. Ahorra significativamente el tiempo de ejecución de consultas. Un aumento adicional en la velocidad de Impala se debe a que esta herramienta SQL para Hadoop, a diferencia de Hive, no almacena resultados intermedios y accede directamente a HDFS o HBase.
Además, Impala genera código de programa en tiempo de ejecución y no en compilación, como lo hace Hive. Sin embargo, un efecto secundario del rendimiento de alta velocidad del Impala es una menor confiabilidad.
En particular, si el nodo de datos deja de funcionar durante la ejecución de una consulta SQL, la instancia de Impala se reiniciará y Hive continuará manteniendo una conexión con la fuente de datos, proporcionando tolerancia a fallas.
Otros beneficios de Impala incluyen soporte integrado para un protocolo de autenticación de red segura Kerberos, priorización y la capacidad de administrar la cola de solicitudes y soporte para formatos populares de Big Data como LZO, Avro, RCFile, Parquet y Sequence.
Hive Vs Impala: similitudes
Hive e Impala se distribuyen libremente bajo la licencia de Apache Software Foundation y se refieren a herramientas SQL para trabajar con datos almacenados en un clúster de Hadoop. Además, también utilizan el sistema de archivos distribuido HDFS.
Impala y Hive implementan diferentes tareas con un enfoque común en el procesamiento SQL de grandes datos almacenados en un clúster de Apache Hadoop. Impala proporciona una interfaz similar a SQL, que le permite leer y escribir tablas de Hive, lo que facilita el intercambio de datos.
Al mismo tiempo, Impala hace que las operaciones de SQL en Hadoop sean bastante rápidas y eficientes, lo que permite usar este DBMS en proyectos de investigación de análisis de Big Data. Siempre que sea posible, Impala trabaja con una infraestructura de Apache Hive existente que ya se usa para ejecutar consultas por lotes de SQL de ejecución prolongada.
Además, Impala almacena sus definiciones de tablas en un metastore, una base de datos MySQL o PostgreSQL tradicional, es decir, en el mismo lugar donde Hive almacena datos similares. Le permite a Impala acceder a las tablas de Hive siempre que todas las columnas usen los tipos de datos, formatos de archivo y códecs de compresión admitidos por Impala.
Colmena Vs Impala: Diferencias

Lenguaje de programación
Hive está escrito en Java, mientras que Impala está escrito en C++. Sin embargo, Impala también utiliza algunas UDF de Hive basadas en Java.
casos de uso
Los ingenieros de datos usan Hive en procesos ETL (Extracción, Transformación, Carga), por ejemplo, para trabajos por lotes de larga ejecución en grandes conjuntos de datos, por ejemplo, en agregadores de viajes y sistemas de información de aeropuertos. Por su parte, Impala está destinado principalmente a analistas y científicos de datos y se utiliza principalmente en tareas como inteligencia empresarial.
Actuación
Impala ejecuta consultas SQL en tiempo real, mientras que Hive se caracteriza por una baja velocidad de procesamiento de datos. Con consultas SQL simples, Impala puede ejecutarse de 6 a 69 veces más rápido que Hive. Sin embargo, Hive maneja mejor las consultas complejas.
Latencia/rendimiento
El rendimiento de Hive es significativamente mayor que el de Impala. La función LLAP (Live Long and Process), que permite el almacenamiento en caché de consultas en la memoria, proporciona a Hive un buen rendimiento de bajo nivel.
LLAP incluye servicios de sistema a largo plazo (daemons), que le permiten interactuar directamente con los nodos de datos HDFS y reemplazar la estructura de consulta DAG estrechamente integrada (gráfico acíclico dirigido), un modelo de gráfico que se usa activamente en la computación Big Data.
Tolerancia a fallos
Hive es un sistema tolerante a fallas que conserva todos los resultados intermedios. También afecta positivamente la escalabilidad, pero conduce a una disminución en la velocidad de procesamiento de datos. A su vez, Impala no se puede llamar una plataforma tolerante a fallas porque está más limitada a la memoria.
Conversión de código
Hive genera expresiones de consulta en tiempo de compilación, mientras que Impala las genera en tiempo de ejecución. Hive se caracteriza por un problema de «arranque en frío» la primera vez que se inicia la aplicación; las consultas se convierten lentamente debido a la necesidad de establecer una conexión con la fuente de datos.
Impala no tiene este tipo de gastos generales de inicio. Los servicios del sistema necesarios (daemons) para procesar consultas SQL se inician en el momento del arranque, lo que acelera el trabajo.
soporte de almacenamiento
Impala es compatible con los formatos LZO, Avro y Parquet, mientras que Hive funciona con texto sin formato y ORC. Sin embargo, ambos admiten los formatos RCFIle y Sequence.
Apache HiveApache ImpalaLenguaje JavaC++ Casos de usoIngeniería de datosAnálisis y análisisRendimientoAlto para consultas simplesLatencia comparativamente bajaMás latencia debido al almacenamiento en cachéLess latent Fault ToleranceMás tolerante debido a MapReduceMenos tolerante debido a MPPConversiónLento debido al inicio en fríoConversión más rápidaSoporte de almacenamientoTexto sin formato y ORCLZO, Avro, Parquet
Ultimas palabras
Hive e Impala no compiten sino que se complementan de manera efectiva. Aunque existen diferencias significativas entre los dos, también hay mucho en común y elegir uno sobre el otro depende de los datos y requisitos particulares del proyecto.
También puede explorar comparaciones directas entre Hadoop y Spark.
.