
Si ha aprendido algunos lenguajes de programación de computadoras, es posible que haya escuchado el término analizar texto. Esto se utiliza para simplificar los valores de datos complejos del archivo. El artículo lo ayuda a saber cómo analizar el texto usando el idioma. Además de esto, si se ha enfrentado a un error en el texto de análisis x, sabrá cómo corregir el error de análisis en el artículo.

Tabla de contenido
Cómo analizar texto
En este artículo, hemos mostrado una guía completa para analizar texto de varias maneras y también brindamos una breve introducción al análisis de texto.
¿Qué es el análisis de texto?
Antes de profundizar en aprender los conceptos de análisis de texto usando cualquier código. Es importante conocer los conceptos básicos del lenguaje y la codificación.
PNL o Procesamiento del Lenguaje Natural
Para analizar texto, se utiliza Procesamiento de lenguaje natural o NLP, que es un subcampo del dominio de Inteligencia artificial. El lenguaje Python, que es uno de los lenguajes que pertenecen a la categoría, se usa para analizar texto.
Los códigos NLP permiten que las computadoras comprendan y procesen los lenguajes humanos para hacerlos adecuados para diversas aplicaciones. Para aplicar técnicas de ML o Machine Learning al lenguaje, los datos de texto no estructurados deben convertirse en datos tabulares estructurados. Para completar la actividad de análisis, se utiliza el lenguaje Python para modificar los códigos del programa.
¿Qué es el análisis de texto?
Analizar texto simplemente significa convertir los datos de un formato a otro formato. El formato en el que se guarda el archivo debe analizarse o convertirse a un archivo en un formato diferente para permitir que el usuario lo use en varias aplicaciones.
- En otras palabras, el proceso consiste en analizar la cadena o un texto y convertirlo en componentes lógicos alterando el formato del archivo.
- Algunas reglas del lenguaje Python se utilizan para completar esta tarea de programación común. Al analizar el texto, la serie de texto dada se divide en componentes más pequeños.
¿Cuáles son las razones para analizar el texto?
Las razones por las que el texto tiene que ser analizado se dan en esta sección y es un requisito previo de conocimiento antes de saber cómo analizar el texto.
- Todos los datos computarizados no estarán en el mismo formato y pueden diferir según las distintas aplicaciones.
- Los formatos de datos varían para varias aplicaciones y un código incompatible provocaría este error.
- No existe un programa informático universal individual para seleccionar los datos de todos los formatos de datos.
Método 1: a través de la clase DataFrame
La clase DataFrame del lenguaje Python tiene todas las funciones necesarias para analizar texto. Esta biblioteca incorporada alberga los códigos necesarios para analizar datos de cualquier formato a otro formato.
Breve introducción de la clase DataFrame
DataFrame Class es una estructura de datos rica en características, que se utiliza como herramienta de análisis de datos. Esta es una poderosa herramienta de análisis de datos que se puede utilizar para analizar datos con un mínimo esfuerzo.
- El código se lee en el DataFrame de pandas para realizar el análisis en el lenguaje Python.
- La clase viene con numerosos paquetes proporcionados por los pandas que utilizan los analistas de datos de Python.
- La característica de esta clase es una abstracción, un código en el que la funcionalidad interna de la función se oculta a los usuarios de la biblioteca NumPy. La biblioteca NumPy es una biblioteca de Python que abarca los comandos y funciones para trabajar con matrices.
- La clase DataFrame se puede usar para representar una matriz bidimensional con múltiples índices de fila y columna. Estos índices ayudan a almacenar datos multidimensionales y, por lo tanto, se denominan MultiIndex. Estos deben modificarse para saber cómo corregir el error de análisis.
Los pandas del lenguaje Python ayudan a realizar operaciones SQL o de estilo de base de datos con la máxima perfección para evitar errores en el texto de análisis x. También contiene algunas herramientas de IO que ayudan a analizar los archivos de CSV, MS Excel, JSON, HDF5 y otros formatos de datos.
Proceso de análisis de texto utilizando la clase DataFrame
Para saber cómo analizar el texto, puede usar el proceso estándar utilizando la clase DataFrame que se proporciona en esta sección.
- Descifrar el formato de datos de los datos de entrada.
- Decida los datos de salida de los datos, como CSV o valor separado por comas.
- Escriba en el código un tipo de datos primitivo como list o dict.
Nota: Escribir el código en un DataFrame vacío puede ser tedioso y complejo. Los pandas permiten crear datos en la clase DataFrame a partir de estos tipos de datos. Por lo tanto, los datos en el tipo de datos primitivo se pueden analizar fácilmente al formato de datos requerido.
- Analice los datos utilizando la herramienta de análisis de datos, pandas DataFrame, e imprima el resultado.
Opción I: Formato Estándar
Aquí se explica el método estándar para formatear cualquier archivo con un determinado formato de datos, como CSV.
- Guarde el archivo con los valores de datos localmente en su PC. Por ejemplo, puede nombrar el archivo data.txt.
- Importe el archivo en pandas con un nombre específico e importe los datos a otra variable. Por ejemplo, los pandas del idioma se importan al nombre pd en el código dado.
- La importación debe tener un código completo con el detalle del nombre del archivo de entrada, la función y el formato del archivo de entrada.
Nota: Aquí, la variable llamada res se usa para realizar la función de lectura de los datos en el archivo data.txt usando los pandas importados en pd. El formato de datos del texto de entrada se especifica en el formato CSV.
- Llame al tipo de archivo nombrado y analice el texto analizado en el resultado impreso. Por ejemplo, el comando res después de la ejecución de la línea de comando ayudará a imprimir el texto analizado.
A continuación se proporciona un código de ejemplo para el proceso explicado anteriormente y ayudará a comprender cómo analizar el texto.
import pandas as pd res = pd.read_csv(‘data.txt’) res
En este caso, si ingresa los valores de datos en el archivo data.txt como [1,2,3]se analizaría y mostraría como 1 2 3.
Opción II: método de cadena
Si el texto proporcionado al código contiene solo cadenas o caracteres alfabéticos, los caracteres especiales de la cadena, como comas, espacios, etc., se pueden usar para separar y analizar el texto. El proceso es similar a las operaciones comunes de cadenas internas. Para saber cómo corregir el error de análisis, debe seguir el proceso de análisis del texto con esta opción que se explica a continuación.
- Los datos se extraen de la cadena y se anotan todos los caracteres especiales que separan el texto.
Por ejemplo, en el código proporcionado a continuación, se identifican los caracteres especiales en la cadena my_string, que son ‘,’ y ‘:’. Este proceso debe realizarse con cuidado para evitar errores al analizar el texto x.
- El texto de la cadena se divide individualmente según los valores y la posición de los caracteres especiales.
Por ejemplo, la cadena se divide en valores de datos de texto en función de los caracteres especiales identificados con el comando dividir.
- Los valores de datos de la cadena se imprimen solos como texto analizado. Aquí, la declaración de impresión se usa para imprimir el valor de datos analizados del texto.
El código de muestra para el proceso explicado anteriormente se proporciona a continuación.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
En este caso, el resultado de la cadena analizada se mostraría como se muestra a continuación.
Names: [‘Tech’, ‘computer’]
Para obtener una mayor claridad y saber cómo analizar el texto mientras usa la cadena de texto, se utiliza un bucle for y el código se modifica de la siguiente manera.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
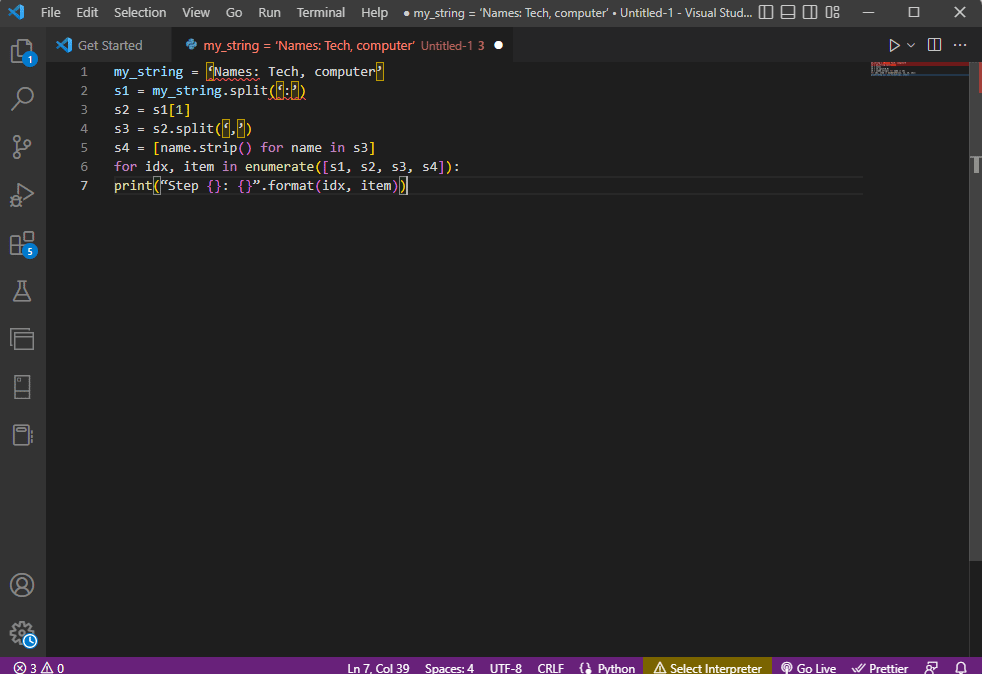
El resultado del texto analizado para cada uno de estos pasos se muestra a continuación. Puede observar que, en el Paso 0, la cadena se separa según el carácter especial: y los valores de datos de texto se separan según el carácter en pasos posteriores.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Opción III: análisis de archivo complejo
En la mayoría de los casos, los datos del archivo que deben analizarse contienen diferentes tipos de datos y valores de datos. En este caso, puede resultar difícil analizar el archivo utilizando los métodos explicados anteriormente.
Las características de analizar los datos complejos en el archivo son hacer que los valores de los datos se muestren en un formato tabular.
- El Título o Metadatos de los valores se imprime en la parte superior del archivo,
- Las variables y los campos se imprimen en la salida en forma tabular, y
- Los valores de datos forman una clave compuesta.
Antes de profundizar en el aprendizaje de cómo analizar texto en este método, es necesario aprender algunos conceptos básicos. El análisis de los valores de los datos se realiza en función de expresiones regulares o Regex.
Patrones de expresiones regulares
Para saber cómo corregir el error de análisis, debe asegurarse de que los patrones de expresiones regulares en las expresiones sean correctos. El código para analizar los valores de datos de las cadenas implicaría los patrones Regex comunes que se enumeran a continuación en esta sección.
-
‘d’ : coincide con el dígito decimal en la cadena,
-
‘s’ : coincide con el carácter de espacio en blanco,
-
‘w’: coincide con el carácter alfanumérico,
-
‘+’ o ‘*’: realiza una coincidencia codiciosa al hacer coincidir uno o más caracteres en las cadenas,
-
‘a-z’: coincide con los grupos en minúsculas en los valores de datos de texto,
-
‘A-Z’ o ‘a-z’ : coincide con los grupos de mayúsculas y minúsculas de la cadena, y
-
‘0-9’: coincide con los valores numéricos.
Expresiones regulares
Los módulos de expresiones regulares son una parte importante del paquete pandas en el lenguaje Python y un re incorrecto puede provocar un error en el texto de análisis x. Es un lenguaje diminuto incrustado dentro de Python para encontrar el patrón de cadena en la expresión. Las expresiones regulares o Regex son cadenas con una sintaxis especial. Permite al usuario hacer coincidir patrones en otras cadenas en función de los valores de las cadenas.
Regex se crea según el tipo de datos y el requisito de la expresión en la cadena, como ‘String = (.*)n. La expresión regular se usa antes del patrón en cada expresión. Los símbolos utilizados en las expresiones regulares se enumeran a continuación y ayudarán a saber cómo analizar el texto.
-
. : para recuperar cualquier carácter de los datos,
-
* : utiliza cero o más datos de la expresión anterior,
-
(.*) : para agrupar una parte de la expresión regular entre paréntesis,
-
n: crea un nuevo carácter de línea al final de la línea en el código,
-
d : crea un valor integral corto en el rango de 0 a 9,
-
+ : usa uno o más datos de la expresión anterior, y
-
| : crea una declaración lógica; utilizado para o expresiones.
RegexObjects
RegexObject es un valor de retorno para la función de compilación y se usa para devolver un MatchObject si la expresión coincide con el valor de coincidencia.
1. Objeto de coincidencia
Como el valor booleano de MatchObject siempre es verdadero, puede usar una declaración if para identificar las coincidencias positivas en el objeto. En el caso de utilizar la instrucción if, el grupo al que hace referencia el índice se utiliza para averiguar la coincidencia del objeto en la expresión.
-
group() devuelve uno o más subgrupos de coincidencia,
-
group(0) devuelve el partido completo,
-
group(1) devuelve el primer subgrupo entre paréntesis, y
- Al referirnos a múltiples grupos, debemos usar una extensión específica de python. Esta extensión se utiliza para especificar el nombre del grupo en el que se debe encontrar la coincidencia. La extensión específica se proporciona dentro del grupo entre paréntesis. Por ejemplo, la expresión (?P
regex1) se referiría al grupo específico con el nombre group1 y verificaría la coincidencia en la expresión regular, regex1. Para aprender a corregir el error de análisis, debe verificar si el grupo está apuntado correctamente.
2. Métodos de MatchObject
Al encontrar cómo analizar texto, es importante saber que MatchObject tiene dos métodos básicos, como se indica a continuación. Si MatchObject se encuentra en la expresión especificada, devolverá su instancia; de lo contrario, devolverá Ninguno.
- El método match(string) se usa para encontrar las coincidencias de la cadena al comienzo de la expresión regular, y
- El método de búsqueda (cadena) se usa para escanear la cadena para encontrar la ubicación de una coincidencia en la expresión regular.
Funciones de expresiones regulares
Las funciones Regex son líneas de código que se utilizan para realizar una determinada función según lo especificado por el usuario a partir del conjunto de valores de datos adquiridos.
Nota: Para escribir las funciones, se utilizan cadenas sin formato para las expresiones regulares para evitar errores en el texto de análisis x. Esto se hace agregando el subíndice r antes de cada patrón en la expresión.
Las funciones comunes utilizadas en las expresiones se explican a continuación.
1. re.encontrar()
Esta función devuelve todos los patrones de la cadena si se encuentra una coincidencia y devuelve una lista vacía si no se encuentra ninguna. Por ejemplo, la función string = re.findall(‘[aeiou]’, regex_filename) se usa para encontrar la ocurrencia de la vocal en el nombre del archivo.
2. re.dividir()
Esta función se utiliza para dividir la cadena en caso de que se encuentre una coincidencia con un carácter especificado, como un espacio. En caso de que no se encuentre ninguna coincidencia, devuelve una cadena vacía.
3. re.sub()
La función sustituye el texto coincidente con el contenido de la variable de reemplazo dada. A diferencia de otras funciones, si no se encuentra ningún patrón, se devuelve la cadena original.
4. investigar()
Una de las funciones básicas para ayudar a aprender a analizar texto es la función de búsqueda. Ayuda a buscar el patrón en la cadena y devolver el objeto de coincidencia. Si la búsqueda falla al identificar la coincidencia, no se devuelve ningún valor.
5. recompilar (patrón)
Esta función se usa para compilar patrones de expresiones regulares en un RegexObject, que se discutió anteriormente.
Otros requerimientos
Los requisitos enumerados son una característica adicional que utilizan los programadores avanzados en el análisis de datos.
- Para visualizar la expresión regular, se usa regexper, y
- Para probar la expresión regular, se usa regex101.
Proceso de análisis de texto
El método para analizar el texto en esta opción compleja se describe a continuación.
- El paso más importante es comprender el formato de entrada leyendo el contenido del archivo. Por ejemplo, las funciones with open y read() se utilizan para abrir y leer el contenido del archivo llamado muestra. El archivo de muestra tiene el contenido del archivo file.txt; para aprender a corregir el error de análisis, el archivo debe leerse por completo.
- El contenido del archivo se imprime para analizar los datos manualmente para averiguar los metadatos de los valores. Aquí, la función print() se usa para imprimir el contenido del archivo de muestra.
- Los paquetes de datos requeridos para analizar el texto se importan al código y se le da un nombre a la clase para su posterior codificación. Aquí se importan las expresiones regulares y los pandas.
- Las expresiones regulares requeridas para el código se definen en el archivo al incluir el patrón de expresión regular y la función de expresión regular. Esto permite que el objeto de texto o corpus tome el código para el análisis de datos.
- Para saber cómo analizar el texto, puede consultar el código de ejemplo que se proporciona aquí. La función compile() se usa para compilar la cadena del grupo stringname1 del archivo filename. La función para buscar coincidencias en la expresión regular es utilizada por el comando ief_parse_line(line),
- El analizador de líneas para el código se escribe utilizando def_parse_file(filepath), en el que la función definida comprueba todas las coincidencias de expresiones regulares en la función especificada. Aquí, el método regex search() busca la clave rx en el nombre del archivo y devuelve la clave y la coincidencia de la primera expresión regular coincidente. Cualquier problema con el paso puede provocar un error en el texto de análisis x.
- El siguiente paso es escribir un analizador de archivos usando la función de analizador de archivos, que es def_parse_file(filepath). Se crea una lista vacía para recopilar los datos del código, como datos = []la coincidencia se comprueba en cada línea mediante match = _parse_line(line), y se devuelven los datos del valor exacto según el tipo de datos.
- Para extraer el número y el valor de la tabla, se usa el comando line.strip().split(‘,’). El comando fila{} se usa para crear un diccionario con la fila de datos. El comando data.append(row) se usa para comprender los datos y analizarlos en un formato tabular.
El comando data = pd.DataFrame(data) se usa para crear un marco de datos de pandas a partir de los valores dictados. Alternativamente, puede usar los siguientes comandos para el propósito respectivo como se indica a continuación.
-
datos.set_index([‘string’, ‘integer’]inplace=True) para establecer el índice de la tabla.
-
data = data.groupby(level=data.index.names).first() para consolidar y eliminar nans.
-
data = data.apply(pd.to_numeric, errors=’ignore’) para actualizar la puntuación de flotante a valor entero.
El paso final para saber cómo analizar texto es probar el analizador usando la instrucción if asignando los valores a una variable data e imprimiéndola usando el comando print(data).
El código de ejemplo para la explicación anterior se proporciona aquí.
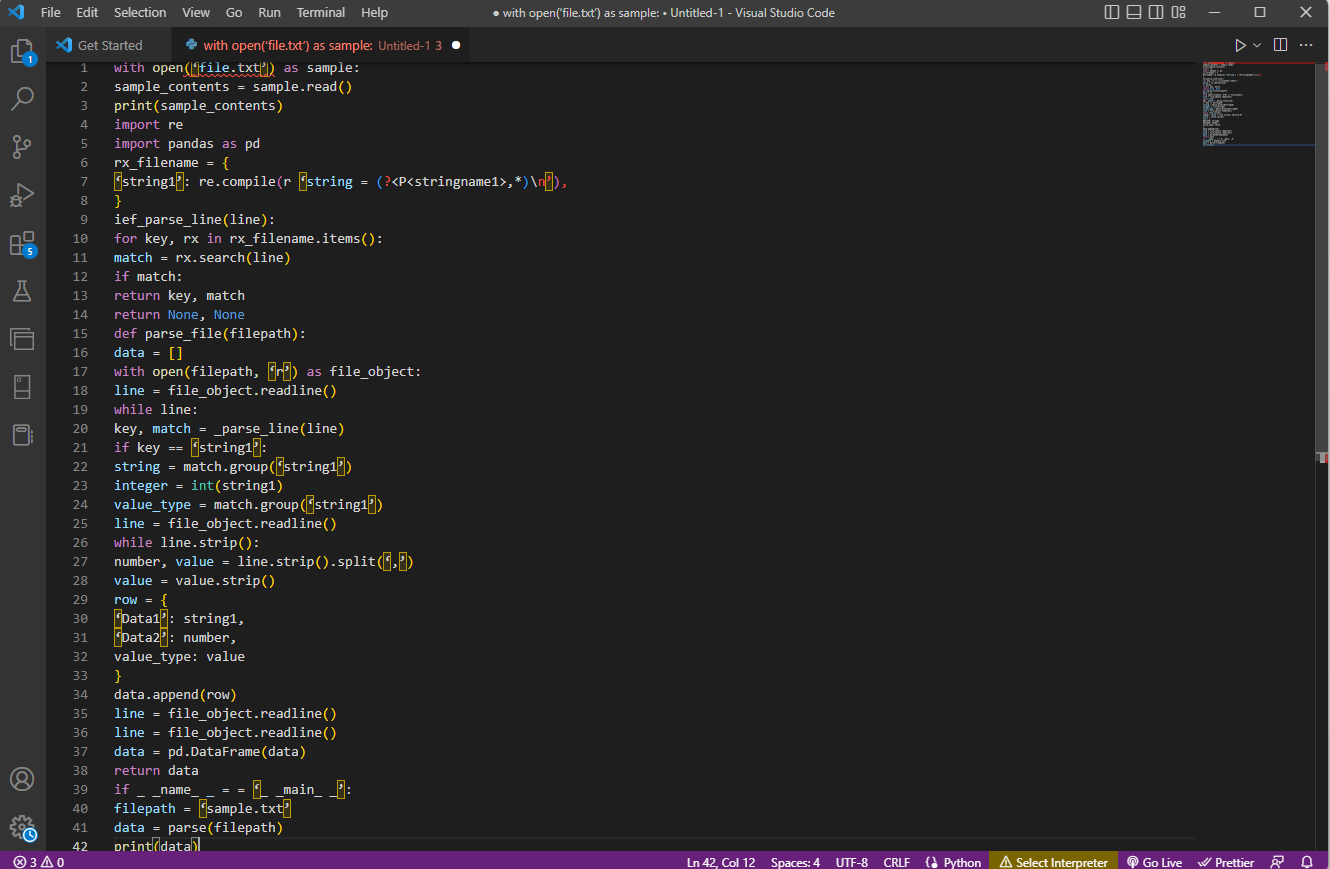
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Método 2: A través de la tokenización de palabras
El proceso de convertir un texto o corpus en tokens o piezas más pequeñas en función de ciertas reglas se denomina tokenización. Para aprender a corregir el error de análisis, es importante analizar los comandos de tokenización de palabras en el código. Similar a la expresión regular, se pueden crear reglas propias en este método y ayuda en las tareas de preprocesamiento de texto, como el mapeo de partes del discurso. Además, en este método se realizan actividades como encontrar y unir palabras comunes, limpiar texto y preparar los datos para técnicas avanzadas de análisis de texto, como el análisis de sentimientos. Si la tokenización es incorrecta, puede ocurrir un error en el texto de análisis x.
Biblioteca Ntlk
El proceso requiere la ayuda de la popular biblioteca de herramientas de lenguaje llamada nltk, que tiene un amplio conjunto de funciones para realizar muchos trabajos de PNL. Estos se pueden descargar a través de Pip o Pip Installs Packages. Para saber cómo analizar texto, puede usar el paquete base de la distribución Anaconda que incluye la biblioteca por defecto.
Formas de tokenización
Las formas comunes de este método son tokenización de palabras y tokenización de oraciones. Debido al token de nivel de palabra, el primero imprime una palabra solo una vez, mientras que el segundo imprime la palabra al nivel de la oración.
Proceso de análisis de texto
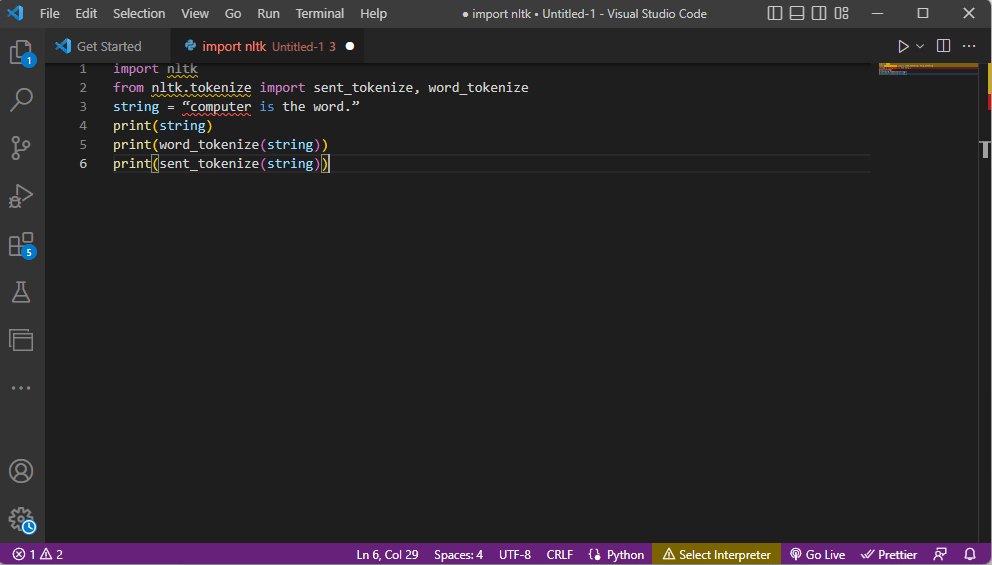
- La biblioteca del kit de herramientas ntlk se importa y los formularios de tokenización se importan de la biblioteca.
- Se da una cadena y se dan los comandos para realizar la tokenización.
- Mientras se imprime la cadena, la salida sería computadora es la palabra.
- En el caso de la tokenización de palabras o word_tokenize(), cada una de las palabras de la oración se imprime individualmente dentro de » y está separada por una coma. La salida para el comando sería la ‘computadora’, ‘es’, ‘la’, ‘palabra’, ‘.’
- En el caso de tokenización de oraciones o sent_tokenize(), las oraciones individuales se colocan dentro de » y se permite la repetición de palabras. El resultado del comando sería ‘computadora es la palabra’.
El código que explica los pasos para la tokenización anterior se proporciona aquí.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Método 3: a través de la clase DocParser
Similar a la clase DataFrame, la clase DocParser se puede usar para analizar el texto en el código. La clase le permite llamar a la función de análisis con la ruta del archivo.
Proceso de análisis de texto
Para saber cómo analizar texto usando la clase DocParser, siga las instrucciones que se dan a continuación.
- La función get_format(filename) se usa para extraer la extensión del archivo, devolverlo a una variable establecida para la función y pasarlo a la siguiente función. Por ejemplo, p1 = get_format(filename) extraería la extensión de archivo de filename, la establecería en la variable p1 y la pasaría a la siguiente función.
- Una estructura lógica con otras funciones se construye utilizando las instrucciones y funciones if-elif-else.
- Si la extensión del archivo es válida y la estructura es lógica, la función get_parser se usa para analizar los datos en la ruta del archivo y devolver el objeto de cadena al usuario.
Nota: Para saber cómo corregir el error de análisis, esta función debe implementarse correctamente.
- El análisis de los valores de datos se realiza con la extensión de archivo del archivo. La implementación concreta de la clase, que son parse_txt o parse_docx, se usa para generar objetos de cadena a partir de las partes del tipo de archivo dado.
- El análisis se puede realizar para archivos de otras extensiones legibles, como parse_pdf, parse_html y parse_pptx.
- Los valores de datos y la interfaz se pueden importar a aplicaciones con declaraciones de importación e instanciar un objeto DocParser. Esto se puede hacer analizando archivos en el lenguaje Python, como parse_file.py. Esta operación debe realizarse con cuidado para evitar errores al analizar el texto x.
Método 4: a través de la herramienta de análisis de texto
La herramienta Analizar texto se utiliza para extraer datos específicos de variables y asignarlos a otras variables. Esto es independiente de cualquier otra herramienta utilizada en una tarea y la herramienta de la plataforma BPA se utiliza para consumir y generar variables. Utilice el enlace proporcionado aquí para acceder a la Herramienta de análisis de texto en línea y use las respuestas dadas anteriormente sobre cómo analizar el texto.
Método 5: a través de TextFieldParser (Visual Basic)
TextFieldParser utilizó objetos para analizar y procesar archivos muy grandes que están estructurados y delimitados. El ancho y la columna de texto, como los archivos de registro o la información de la base de datos heredada, se pueden usar en este método. El método de análisis es similar a iterar el código sobre un archivo de texto y se usa principalmente para extraer campos de texto de forma similar a los métodos de manipulación de cadenas. Esto se hace para tokenizar cadenas y campos delimitados de varios anchos utilizando el delimitador definido, como una coma o un tabulador.
Funciones para analizar texto
Las siguientes funciones se pueden utilizar para analizar el texto en este método.
- Para definir un delimitador, se utiliza SetDelimiters. Por ejemplo, el comando testReader.SetDelimiters (vbTab) se usa para establecer el espacio de tabulación como delimitador.
- Para establecer un ancho de campo en un valor entero positivo en un ancho de campo fijo de archivos de texto, puede usar el comando testReader.SetFieldWidths (entero).
- Para probar el tipo de campo del texto, puede usar el siguiente comando testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Métodos para encontrar MatchObject
Hay dos métodos básicos para encontrar MatchObject en el código o en el texto analizado.
- El primer método es definir el formato y recorrer el archivo usando el método ReadFields. Este método ayudaría a procesar cada línea del código.
- El método PeekChars se usa para verificar cada campo individualmente antes de leerlo, definir múltiples formatos y reaccionar.
En cualquier caso, si un campo no coincide con el formato especificado mientras se realiza el análisis o se busca cómo analizar el texto, se devuelve una excepción MalformedLineException.
Consejo profesional: cómo analizar texto a través de MS Excel
Como método final y simple para analizar el texto, puede usar el ms excel app como analizador para crear archivos delimitados por tabulaciones y comas. Esto ayudaría en la verificación cruzada con su resultado analizado y ayudaría a encontrar cómo corregir el error de análisis.
1. Seleccione los valores de datos en el archivo de origen y presione las teclas Ctrl + C juntas para copiar el archivo.
2. Abra la aplicación Excel usando la barra de búsqueda de Windows.
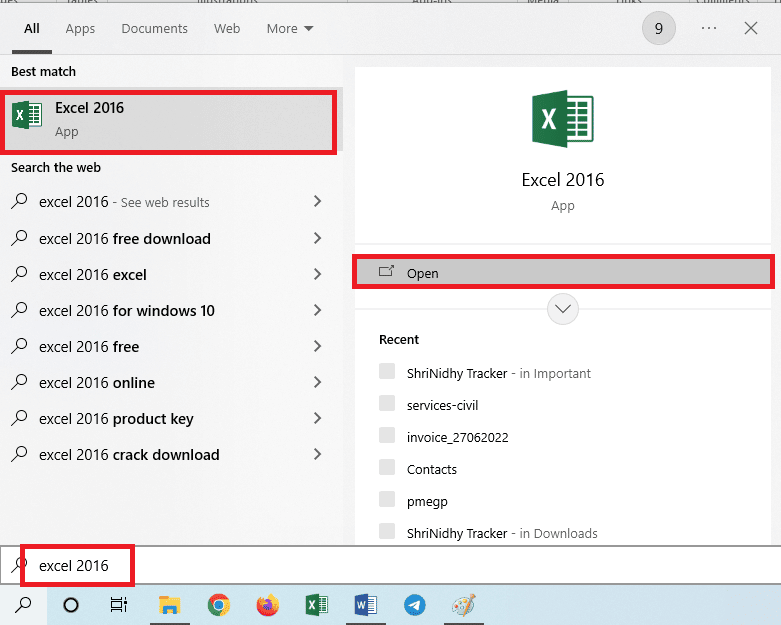
3. Haga clic en la celda A1 y presione las teclas Ctrl + V simultáneamente para pegar el texto copiado.
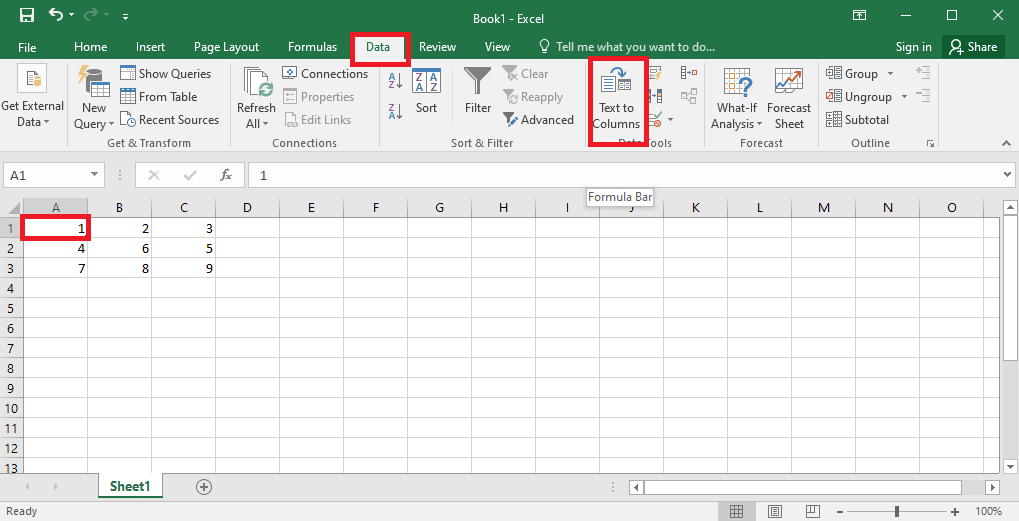
4. Seleccione la celda A1, vaya a la pestaña Datos y haga clic en la opción Texto en columnas en la sección Herramientas de datos.
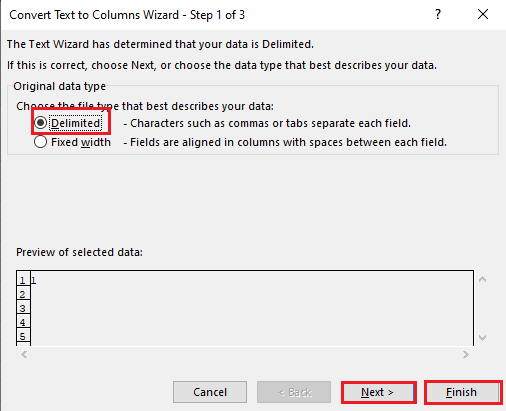
5A. Seleccione la opción Delimitado si se utiliza una coma o un espacio de tabulación como separador y haga clic en los botones Siguiente y Finalizar.
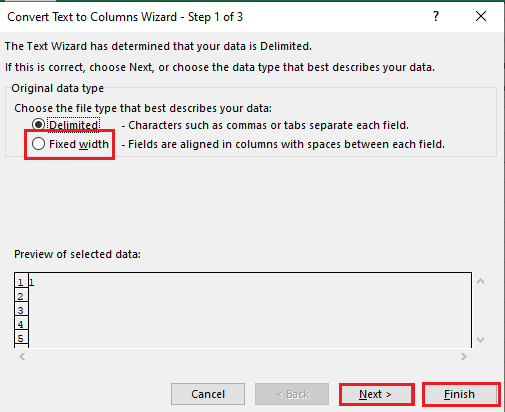
5B. Seleccione la opción Ancho fijo, asigne un valor para el separador y haga clic en los botones Siguiente y Finalizar.
Cómo corregir un error de análisis
El error en el texto de análisis x puede ocurrir en dispositivos Android como, Error de análisis: hubo un problema al analizar el paquete. Esto suele ocurrir cuando la aplicación no se instala desde Google Play Store o mientras se ejecuta una aplicación de terceros.
El texto de error x puede ocurrir si la lista de vectores de caracteres está en bucle y otras funciones forman un modelo lineal para calcular los valores de los datos. El mensaje de error es Error en el análisis (texto = x, mantener. fuente = FALSO):
Puede leer el artículo sobre cómo reparar el error de análisis en Android para conocer las causas y los métodos para corregir el error.
Además de las soluciones de la guía, puede probar las siguientes correcciones.
- Volver a descargar el archivo .apk o restaurar el nombre del archivo.
- Restaurar cambios en el archivo Androidmanifest.xml, si tiene habilidades de programación de nivel experto.
***
El artículo ayuda a enseñar cómo analizar texto y aprender a corregir el error de análisis. Háganos saber qué método ayudó a corregir el error en el texto de análisis x y qué método de análisis es el preferido. Comparta sus sugerencias y consultas en la sección de comentarios a continuación.