
Tabla de contenido
Conclusiones clave
- La concurrencia y el paralelismo son principios fundamentales de la ejecución de tareas en informática, y cada uno tiene sus características distintas.
- La concurrencia permite una utilización eficiente de los recursos y una mejor capacidad de respuesta de las aplicaciones, mientras que el paralelismo es crucial para un rendimiento y una escalabilidad óptimos.
- Python proporciona opciones para manejar la concurrencia, como subprocesos y programación asincrónica con asyncio, así como paralelismo utilizando el módulo de multiprocesamiento.
La concurrencia y el paralelismo son dos técnicas que le permiten ejecutar varios programas simultáneamente. Python tiene múltiples opciones para manejar tareas de forma simultánea y en paralelo, lo que puede resultar confuso.
Explore las herramientas y bibliotecas disponibles para implementar correctamente la concurrencia y el paralelismo en Python, y en qué se diferencian.
Comprender la concurrencia y el paralelismo
La concurrencia y el paralelismo se refieren a dos principios fundamentales de ejecución de tareas en informática. Cada uno tiene sus características distintivas.

La importancia de la concurrencia y el paralelismo
No se puede subestimar la necesidad de simultaneidad y paralelismo en la informática. He aquí por qué estas técnicas son importantes:
Concurrencia en Python
Puede lograr simultaneidad en Python utilizando subprocesos y programación asincrónica con la biblioteca asyncio.
Enhebrado en Python
Threading es un mecanismo de concurrencia de Python que le permite crear y administrar tareas dentro de un solo proceso. Los subprocesos son adecuados para ciertos tipos de tareas, particularmente aquellas que están vinculadas a E/S y pueden beneficiarse de la ejecución simultánea.
Módulo de subprocesamiento de Python proporciona una interfaz de alto nivel para crear y gestionar subprocesos. Si bien GIL (Global Interpreter Lock) limita los subprocesos en términos de verdadero paralelismo, aún pueden lograr concurrencia entrelazando tareas de manera eficiente.
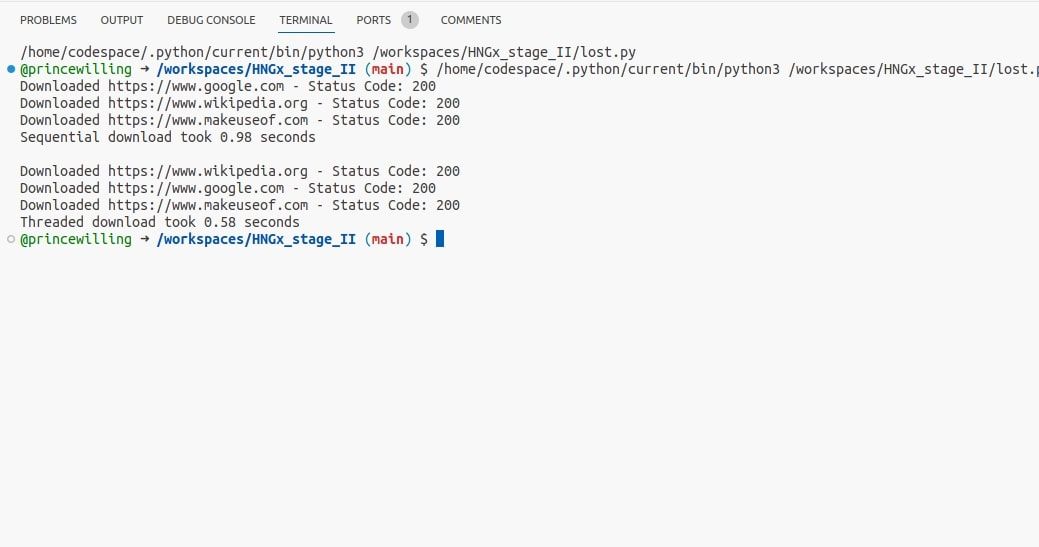
El siguiente código muestra un ejemplo de implementación de concurrencia utilizando subprocesos. Utiliza la biblioteca de solicitudes de Python para enviar una solicitud HTTP, una tarea común de bloqueo de E/S. También utiliza el módulo de tiempo para calcular el tiempo de ejecución.
import requests
import time
import threadingurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
start_time = time.time()for url in urls:
download_url(url)end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
start_time = time.time()
threads = []for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
Al ejecutar este programa, debería ver cuánto más rápidas son las solicitudes enhebradas que las solicitudes secuenciales. Aunque la diferencia es sólo una fracción de segundo, se obtiene una idea clara de la mejora del rendimiento cuando se utilizan subprocesos para tareas vinculadas a E/S.
Programación asincrónica con Asyncio
asincio proporciona un bucle de eventos que gestiona tareas asincrónicas llamadas corrutinas. Las corrutinas son funciones que puedes pausar y reanudar, lo que las hace ideales para tareas vinculadas a E/S. La biblioteca es particularmente útil para escenarios donde las tareas implican esperar recursos externos, como solicitudes de red.
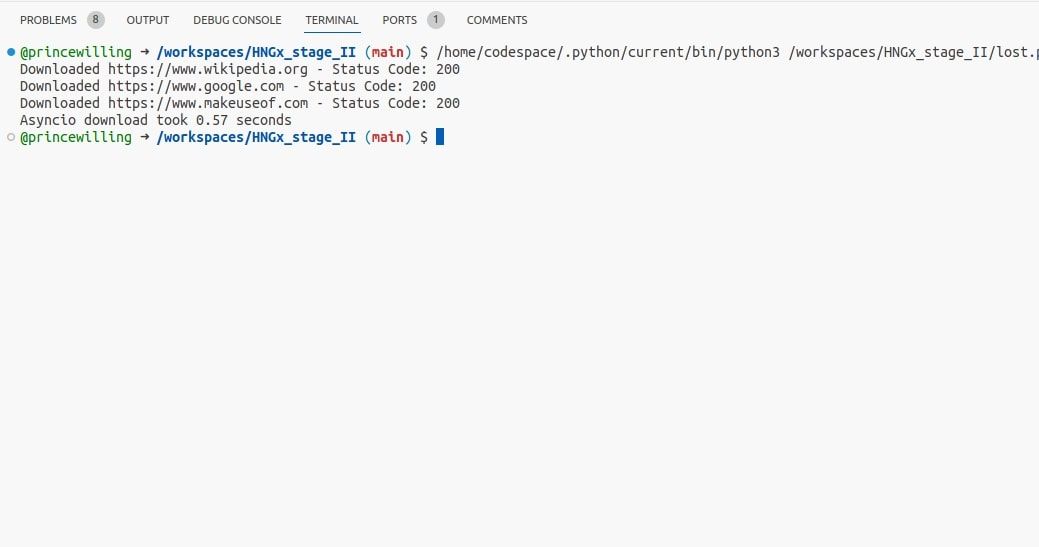
Puede modificar el ejemplo anterior de envío de solicitudes para que funcione con asyncio:
import asyncio
import aiohttp
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)start_time = time.time()
asyncio.run(main())end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
Usando el código, puede descargar páginas web simultáneamente usando asyncio y aprovechar las operaciones de E/S asincrónicas. Esto puede ser más eficiente que los subprocesos para tareas vinculadas a E/S.
Paralelismo en Python
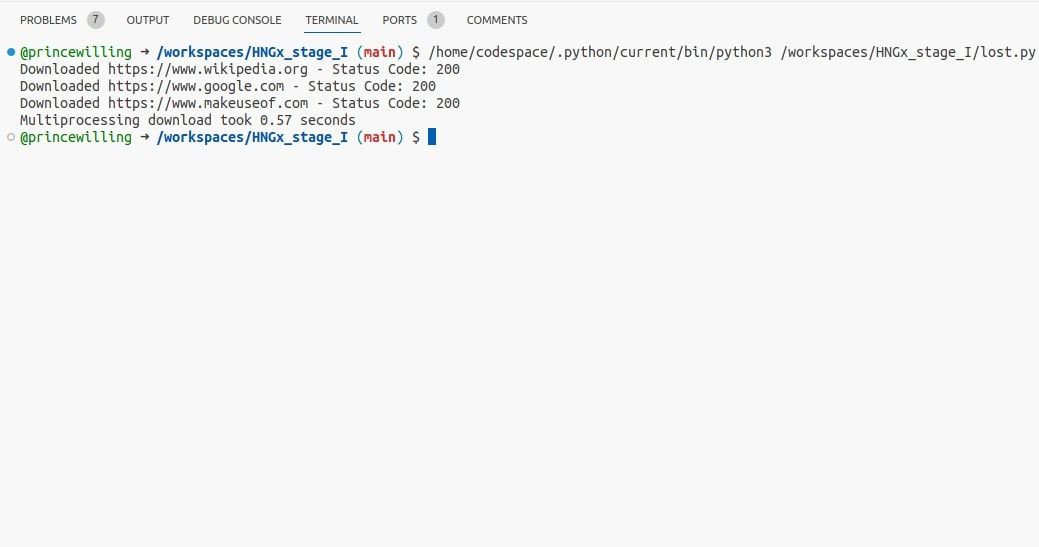
Puedes implementar el paralelismo usando Módulo de multiprocesamiento de Pythonque le permite aprovechar al máximo los procesadores multinúcleo.
Multiprocesamiento en Python
El módulo de multiprocesamiento de Python proporciona una manera de lograr el paralelismo mediante la creación de procesos separados, cada uno con su propio intérprete de Python y espacio de memoria. Esto evita efectivamente el bloqueo global de intérprete (GIL), lo que lo hace adecuado para tareas vinculadas a la CPU.
import requests
import multiprocessing
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
En este ejemplo, el multiprocesamiento genera múltiples procesos, lo que permite que la función download_url se ejecute en paralelo.
Cuándo utilizar concurrencia o paralelismo
La elección entre concurrencia y paralelismo depende de la naturaleza de sus tareas y de los recursos de hardware disponibles.
Puede utilizar la concurrencia cuando trabaje con tareas vinculadas a E/S, como leer y escribir en archivos o realizar solicitudes de red, y cuando las limitaciones de memoria sean una preocupación.
Utilice el multiprocesamiento cuando tenga tareas vinculadas a la CPU que puedan beneficiarse de un verdadero paralelismo y cuando tenga un aislamiento sólido entre tareas, donde el error de una tarea no debería afectar a otras.
Aproveche la concurrencia y el paralelismo
El paralelismo y la concurrencia son formas efectivas de mejorar la capacidad de respuesta y el rendimiento de su código Python. Es importante comprender las diferencias entre estos conceptos y seleccionar la estrategia más eficaz.
Python ofrece las herramientas y módulos que necesita para hacer que su código sea más efectivo a través de la concurrencia o el paralelismo, independientemente de si está trabajando con procesos vinculados a la CPU o a E/S.