
Un plan de recuperación ante desastres es una medida principal que una organización debe tener antes de que les ocurra un evento inusual.
En la industria de TI, comienza con la creación de un documento formal que contiene planes, acciones y procedimientos para enfrentar el desastre y sus secuelas.
Desastre es un evento que llega repentinamente sin previo aviso y puede ser de diferentes tipos. Y cuando aterriza, las personas y las organizaciones enfrentan dificultades de muchos tipos, incluidos problemas financieros y la experiencia del usuario.
Si ocurre un ataque, debe estar preparado para minimizar sus efectos y restaurar sus operaciones más rápido. Aquí es donde preparar un plan práctico de recuperación ante desastres lo ayudará a retener o prevenir el desastre. También puede reducir sus efectos secundarios en términos de experiencia del usuario, costo y tiempo de inactividad.
Además, debe mantener listos sus planes, personas, estrategias, equipos y sistemas para que todo vuelva a la acción. Pero para esto, debe comprender en profundidad la recuperación ante desastres.
En este artículo, discutiré esto en detalle junto con terminologías clave de recuperación ante desastres para que pueda defenderse con valentía y salir fortalecido en condiciones tan adversas.
¡Vamos a empezar!
Tabla de contenido
¿Qué es un desastre?
Un desastre es un evento imprevisto que puede ocurrir en cualquier lugar, incluida la industria de TI. Ocurre de forma natural o por personas y puede interferir con las operaciones de una empresa y perturbar la estructura de la infraestructura.
Como resultado, una organización y sus clientes, proveedores, empleados y socios se ven afectados. Ejerce presión sobre la organización en términos de finanzas, reputación en la industria, confianza del cliente y perímetro de seguridad.
Por lo tanto, debe estar preparado de antemano para superar tal escenario. Para esto, necesita recuperar cada operación y datos al instante. En palabras simples, debe preparar su organización para recuperar todo en el menor intervalo posible para sus clientes.
Los desastres son de muchos tipos, como ataques cibernéticos, sabotaje, ataques terroristas, ransomware o amenazas físicas, huracanes, terremotos, incendios, inundaciones, accidentes industriales, cortes de energía y muchos más.
¿Qué quiere decir con recuperación ante desastres?

La recuperación ante desastres es el proceso de recuperar las operaciones normales después de sufrir un desastre. Implica reanudar el acceso a hardware, software, equipos, conectividad, redes, energía y datos. Debe establecer reglas y procedimientos en un proceso documentado para preparar a su organización antes de un desastre.
Sin embargo, si se destruyen las instalaciones de su organización, debe extender algunas de las actividades trabajando en comunicación, transporte, abastecimiento, lugares de trabajo y más.
¿Por qué es importante el plan de recuperación ante desastres?
Elaborar un plan perfecto para recuperarse de un desastre, ya sea natural o provocado por el hombre, es esencial para todas las industrias de TI. Asegúrese de tener el empleado y las herramientas adecuadas en el lugar correcto para llevar a cabo el plan sin problemas.
Profundicemos en por qué la recuperación ante desastres es crucial.
Límite de daños
Un desastre es impredecible. Nadie sabe cuándo viene y cuándo se va. Pero, te preparas con anticipación para controlar los daños causados a tu infraestructura.
Por ejemplo, en áreas propensas a inundaciones, puede colocar sus documentos esenciales y tipos de equipos en el último piso para evitar daños.
Del mismo modo, haga una copia de seguridad de sus datos esenciales antes de que los ataques cibernéticos puedan violar los datos o robarlos.
Servicios de restauración
Si prepara un plan sólido para recuperarse del desastre, restaurar todos los servicios a su forma normal es rápido y fácil. Significa que en un corto intervalo de tiempo, puede recuperar casi todos los principales activos y servicios.
Minimizar la interrupción
No se puede saber qué pasará mañana o en el próximo paso de una operación. Pero, con un plan de recuperación perfecto, no tiene que preocuparse mucho por las consecuencias. Su infraestructura puede continuar las operaciones con una interrupción mínima.
Entrenamiento y Preparación

Una infraestructura de TI consta de muchos empleados que trabajan bajo un mismo techo. Todos deben saber acerca de la recuperación para actuar de inmediato como se requiere y se espera en caso de una emergencia.
La preparación adecuada también reducirá los niveles de estrés de todos los asociados con su organización. Además, puede capacitar a sus empleados para que tomen las medidas necesarias si ocurre un evento inesperado.
Terminologías de recuperación ante desastres
Comencemos con las terminologías para comprender la recuperación ante desastres desde una perspectiva más cercana.
RTO
El objetivo de tiempo de recuperación (RTO) es la cantidad de tiempo que una organización establece de acuerdo con la naturaleza del negocio para tolerar un desastre sin afectar el crecimiento financiero.
Al configurar el RTO, una empresa debe verificar los tiempos de inactividad que pueden afectar a su organización de muchas maneras. Se utiliza para estudiar estrategias viables para continuar con las operaciones comerciales incluso después de un desastre. Cuando los clientes se enfrentan a problemas en la aplicación, preguntan cuánto tiempo tardará una aplicación en volver a la acción. La respuesta es RTO para cada organización.
Ejemplo: suponga que es una empresa de transacciones en línea como PayPal o Pioneer que enfrenta eventos impredecibles. En este caso, su RTO será lo suficientemente rápido para recuperar la operación.
En otras palabras, una empresa establece su RTO en una hora o dos para evitar consecuencias en forma de finanzas o datos.
RPO
Los objetivos de punto de recuperación (RPO) son la pérdida de datos que una infraestructura de TI puede manejar en términos de tiempo y cantidad de información.
¿Confuso?
Tome un ejemplo de una base de datos que registra transacciones de un banco, incluidas transferencias, programación, pagos y más. Cuando ocurre un desastre, la base de datos se recupera en tiempo real. La diferencia entre la base de datos en el momento del desastre y la recuperación de la base de datos después de un desastre es cero en este caso.
Para algunas empresas, es aceptable tomar alrededor de 24 horas para recuperar toda la información de la copia de seguridad, pero a veces puede ser catastrófico. Es esencial configurar su infraestructura de acuerdo con los requisitos de RPO. Esto incluye mejorar la frecuencia de las copias de seguridad, agregar una base de datos en espera a su arquitectura y más.
conmutación por error
Piensa en una situación en la que estás viajando una larga distancia. De repente, tienes un neumático pinchado debido a alguna razón inesperada. Agradece la llanta de refacción disponible en su vehículo y las herramientas para cambiar la llanta defectuosa.
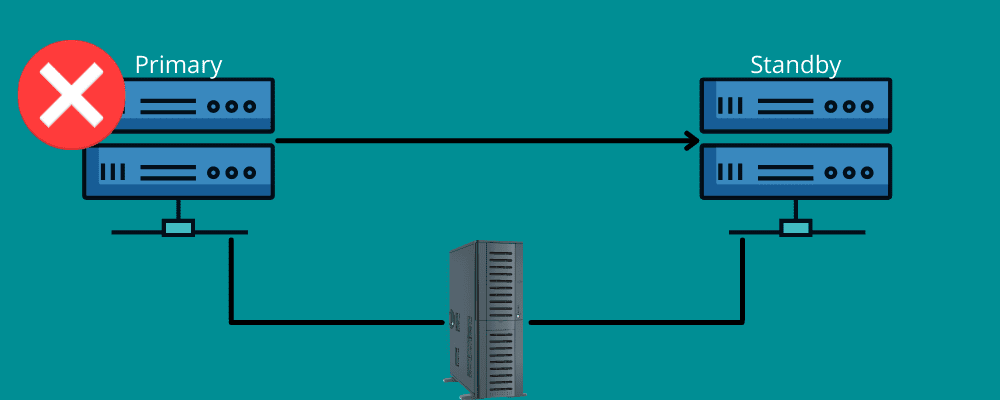
La conmutación por error funciona de la misma manera.
Significa que necesita una conexión de respaldo durante el desastre. En pocas palabras, la conmutación por error significa tener redes y sistemas que puede usar en el momento de un desastre para cambiar su información al sistema de recuperación.
La conmutación por error garantiza que todos sus servicios funcionen sin problemas, incluso si hay fallas de infraestructura o hardware. De esta manera, puede evitar que su organización pierda datos e ingresos y evitar interrupciones en el servicio para sus usuarios finales.
Puede configurarlo manualmente o permitir que funcione automáticamente para mover los datos al servidor de reserva.
Conmutación por recuperación
La conmutación por recuperación de TI es una operación simple en la que la producción original vuelve a su lugar (sistema) original después de que se maneja un desastre. Durante el ataque, las empresas siguen una operación de conmutación por error debido a la cual todas las cargas de trabajo se transfieren a una réplica de VM o un sistema de respaldo.
Sin embargo, no puede simplemente omitir el siguiente paso de devolución. Cuando recupere todo y vuelva a la acción, deberá transferir todas las cargas de trabajo a sus máquinas virtuales o sistemas originales. Este proceso general de devolver las cargas de trabajo al lugar de trabajo o sistema original se conoce como conmutación por recuperación. Significa que vas a “regresar” después del ataque.
La conmutación por recuperación también se utiliza para el mantenimiento programado de una empresa. Es cierto que la conmutación por recuperación siempre se produce después de la conmutación por error. En otras palabras, la conmutación por error es el primer paso y la conmutación por recuperación es el segundo paso en la recuperación de datos esenciales. Se puede configurar de nube a nube, de local a local, de local a nube o cualquier combinación de estos.
DR
La recuperación ante desastres (DR) es el proceso en el que tiene planes prediseñados para recuperar sus activos dentro del plazo.
DR brinda la capacidad a una organización de responder rápidamente y recuperar cada servicio de un evento inesperado. También proporciona documentación formal que contiene instrucciones sobre cómo tomar medidas inmediatas en caso de incidentes imprevistos.
BCP
Business Continuity Plan (BCP) es uno de los planes de recuperación ante desastres más aceptables que permite que la infraestructura de TI elabore estrategias para manejar las interrupciones de TI en servidores, dispositivos móviles, computadoras personales y redes.
BCP es ligeramente diferente de la recuperación ante desastres, ya que ayuda a una organización a hacer planes para restablecer el software empresarial y la productividad para satisfacer las necesidades comerciales clave.
Aquí, una empresa crea un sistema de recuperación para superar amenazas potenciales, como ataques cibernéticos o desastres naturales. Está diseñado para proteger los activos y garantizar que todos los servicios vuelvan a funcionar rápidamente después de la huelga.
BCM

Business Continuity Management (BCM) es un proceso de gestión de riesgos especialmente diseñado para actuar como un escudo contra las amenazas a los procesos comerciales. BCM es el siguiente paso de BCP, donde valida los planes de recuperación para asegurarse de que todos en el negocio respondan al plan instantáneamente y recuperen todo lo esencial.
BCM actúa como un marco de gestión para identificar los riesgos de la infraestructura cuando enfrenta amenazas externas y/o internas. También garantiza que el marco funcione de manera eficiente con la ayuda de pruebas periódicas para mejorar la previsibilidad, reducir el riesgo y alinear el plan para futuros ataques.
BIA
Business Impact Analysis (BIA) es el proceso de analizar la tasa de supervivencia de una empresa mediante la identificación de sistemas, operaciones y procesos cruciales. Habla sobre el efecto de un desastre en su organización debido a la interrupción de sus operaciones.
BIA predice las consecuencias antes de que ocurra un ataque para recopilar información clave que pueda ayudar a crear estrategias de recuperación poderosas. También identifica el costo involucrado debido a las fallas, como el costo de reemplazo de equipos, pérdida de flujo de caja, ganancias, salarios y más.
Al crear un informe BIA, debe considerar los procesos cruciales involucrados en su negocio, el impacto de las interrupciones en diferentes áreas, la duración aceptable, las áreas tolerables, los costos financieros y más.
Árbol de llamadas
Un árbol de llamadas es un proceso de seleccionar una lista de personal para llamar durante una emergencia. Es un procedimiento que sigue una estructura en forma de árbol.
Por ejemplo, durante un desastre, una persona se comunicará con un pequeño grupo de miembros con un mensaje urgente, esos miembros del personal llamarán a cada grupo por separado. De esta manera, todo el personal estará informado durante la amenaza y comenzará su trabajo asignado para recuperar cada función y proceso a tiempo. Hacer una lista es simple, pero implementarla en tiempo real crea confusión.
Debe realizar actividades de llamadas periódicas para preparar a cada miembro del personal de emergencia para que permanezca alerta. Las pruebas periódicas también pueden ayudar a identificar números cambiados o faltantes que pueden afectar gravemente el rendimiento.
Un árbol de llamadas contiene información que se utilizará durante una emergencia para dar instrucciones. También se puede hacer manualmente, pero la gente usa la automatización para acelerar el proceso y notificar a los miembros en el mundo digital actual.
Centro de Comando/Centro de Control
Es una instalación virtual o física especialmente preparada para proporcionar comando o control sobre los planes de recuperación durante una crisis. Se comunica con el equipo para administrar los sistemas y funciones durante el desastre.
Tradicionalmente, la infraestructura depende del centro de comando que se ocupa de las crisis sin un enfoque adecuado. Hoy en día, las organizaciones han diseñado perfectamente su centro de control, lo que convierte la respuesta inmediata en una competencia central.
Una vez que detecta un desastre, el centro de mando avanza rápidamente hacia la fase de recuperación. Además, sirve como punto de información en el caso de servicios, prensa, entregas y más. También reúne a personas de múltiples disciplinas durante tales escenarios.
Respuesta al incidente

La respuesta a incidentes es un tipo de respuesta dada para hacer frente a un ataque. Se realiza con la ayuda de los procedimientos y el personal correctos para preservar la seguridad de la red y los datos de manera efectiva en el momento adecuado.
Si una organización tiene un plan de incidentes antes del evento inesperado, puede proteger sus datos de amenazas en tiempo real. Los especialistas en respuesta a incidentes siempre se mantienen alertas a los problemas y actúan con naturalidad durante un incidente. Toman ciertas medidas para evitar brechas de seguridad, asegurándose de no omitir un solo paso durante la recuperación ante desastres.
Al principio, debe determinar los datos críticos y almacenarlos en la nube o en cualquier ubicación remota para garantizar la seguridad. Aborde las necesidades de infraestructura actuales y las ciberamenazas en evolución actualizando periódicamente los planes de respuesta a incidentes.
Respaldo
Las soluciones de copia de seguridad ayudan a una infraestructura de TI a mantener copias de datos y almacenarlos de forma segura en el momento adecuado. Si enfrenta daños en la base de datos, eliminación accidental de todos los datos o cualquier otro problema, debe estar listo con la copia de seguridad para restaurar los datos al instante y continuar con los servicios.

Implica replicar los archivos y almacenarlos en una ubicación segura para acceder fácilmente a todos los datos después de un evento inusual. Le ayudará si hace una copia de seguridad de sus datos en varias ubicaciones para asegurarse de que puede restaurarlos incluso si falla un sitio.
Resiliencia
La capacidad de las comunidades, estados, organizaciones e individuos para resistir o soportar un desastre sin comprometer los servicios y sistemas se conoce como resiliencia ante desastres.
Una organización debe estar preparada para retener una gran cantidad de estrés debido a los peligros. Asegúrese de tener las capacidades para minimizar sus pérdidas con una mejor planificación en lugar de esperar a que alguien venga a rescatarlo. Esto lo ayudará a adaptarse a los desastres y recuperar de manera eficiente su infraestructura de TI.
Aquí, el objetivo principal es preservar y restaurar las funciones y estructuras esenciales en el momento adecuado siempre que sea necesario. Para convertirse en una organización resistente a los desastres, debe prepararse con anticipación y tener la capacidad de anticipar riesgos, ajustarse a los cambios, compartir y aprender, integrar varios sectores y administrar los niveles de riesgo.
ANS

El Acuerdo de nivel de servicio (SLA) es un plan de desastres en el que les menciona a los usuarios finales el tiempo que puede tomar para restaurar los servicios durante una emergencia.
SLA garantiza a los clientes que sus datos están seguros y no están comprometidos ni se comparten con terceros. Es el único punto de contacto con los problemas del usuario final.
Cada infraestructura de TI brinda seguridad sobre SLA a sus clientes. Por lo tanto, asegúrese de comunicarse con sus usuarios finales de antemano.
SPOF
Un punto único de falla (SPOF) es una pieza de equipo, un individuo, un recurso o una aplicación a la que se conectan muchos otros sistemas o aplicaciones.
Si tal equipo o recurso se cae, todas las partes esenciales conectadas al sistema se caen con él. Por lo tanto, todo el proceso y la operación comercial se verán afectados.
Por lo tanto, debe tener una estrategia para manejar este problema y mantener su organización en funcionamiento. Lo primero que puede hacer es identificar ese único equipo o sistema que puede tener un mayor impacto. A continuación, ejecute un análisis de impacto comercial y obtenga una puntuación de evaluación de riesgos para estar al tanto de las escenas que van a suceder. Profundice y encuéntrelos antes del evento.
Una vez que enumere todos los SPOF, clasifíquelos de acuerdo con el proceso de recuperación. Ponga cada uno de los SPOF en tres categorías diferentes:
- Recupere fácil y directamente con menos tiempo y presupuesto.
- La recuperación sería difícil, pero se podría desarrollar un proceso confiable para restaurar.
- No se puede hacer nada para recuperarse una vez que se cae.
Puede actuar en consecuencia en función de la categoría.
Recuperación del sistema
Durante una falla de hardware, debe ejecutar un proceso de recuperación para recuperar el sistema o servidor en particular a su forma original. Y para recuperar todo el sistema, debe estar preparado con los requisitos de recuperación, copias de seguridad, compatibilidad de firmware y compatibilidad de hardware.
La recuperación del sistema es un proceso que restablece la máquina a su configuración anterior o al mismo estado que tenía cuando era nueva. Hacer esto eliminará todas las infecciones de virus debido al software o las aplicaciones instaladas en su sistema.
Este proceso incluye la planificación de la recuperación de una infraestructura de TI que establece y sigue ciertos procedimientos para garantizar la disponibilidad de los datos frente a interrupciones naturales o provocadas por el hombre.
Restauración del sistema
La restauración del sistema es una herramienta de recuperación que le permite restaurar ciertos archivos e información a su estado anterior en el momento adecuado.
Con la restauración del sistema, puede recuperar claves de registro, programas instalados, controladores, archivos del sistema y más a su versión anterior. Esto actúa como un salvavidas en muchos desastres.
Plan de prueba
Se refiere a un documento que almacena información sobre una estrategia de prueba, estimaciones, recursos, plazos, objetivos y cronogramas. Funciona como un modelo que ejecuta pruebas para garantizar la seguridad del hardware y el software.
Esto incluye varias pruebas de acuerdo con los procedimientos y pasos planificados para manejar las secuelas del desastre. Realice las pruebas periódicas para prepararse usted y su organización para no omitir un solo paso durante el curso de la acción. De esta forma, una infraestructura de TI puede comprender las deficiencias y estar lista para la lucha.
Conclusión
Nadie sabe cuándo ocurrirá un desastre. Por lo tanto, las medidas de seguridad y protección adecuadas son esenciales para todos los negocios.
Las terminologías de recuperación ante desastres lo ayudarán a comprender cómo responder a ataques y desastres. También lo ayudará a prepararse con anticipación para que pueda proteger su infraestructura durante un evento inesperado. Podrá crear una estrategia eficaz de recuperación ante desastres en tiempo real para ahorrar millones de dólares y mantener la confianza de los clientes.