La regresión y la clasificación son dos de las áreas más fundamentales y significativas del aprendizaje automático.
Puede ser complicado distinguir entre los algoritmos de regresión y clasificación cuando recién se está iniciando en el aprendizaje automático. Comprender cómo funcionan estos algoritmos y cuándo usarlos puede ser crucial para hacer predicciones precisas y decisiones efectivas.
Primero, veamos sobre el aprendizaje automático.
Tabla de contenido
¿Qué es el aprendizaje automático?
El aprendizaje automático es un método para enseñar a las computadoras a aprender y tomar decisiones sin ser programadas explícitamente. Implica entrenar un modelo de computadora en un conjunto de datos, lo que permite que el modelo haga predicciones o decisiones basadas en patrones y relaciones en los datos.
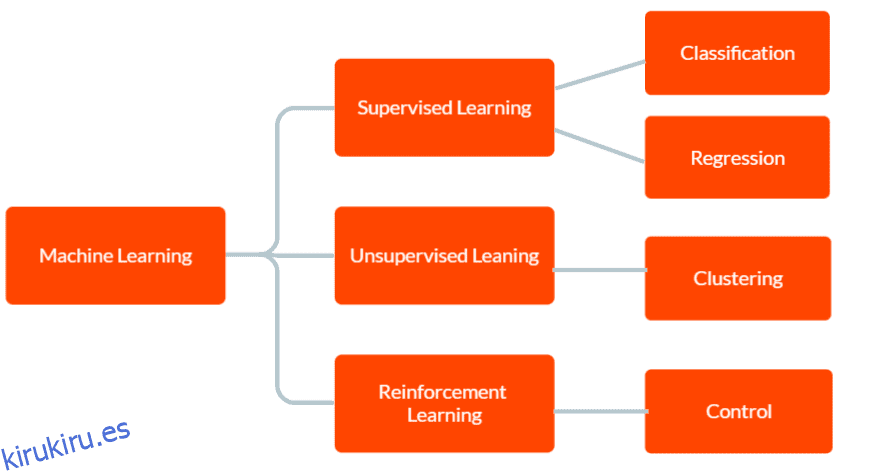
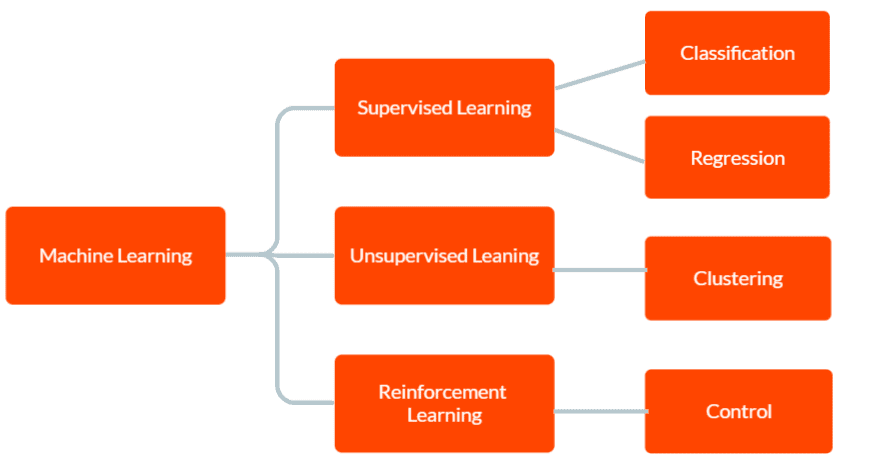
Hay tres tipos principales de aprendizaje automático: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo.
En el aprendizaje supervisado, el modelo cuenta con datos de entrenamiento etiquetados, incluidos los datos de entrada y la salida correcta correspondiente. El objetivo es que el modelo haga predicciones sobre la salida de datos nuevos e invisibles en función de los patrones que aprendió de los datos de entrenamiento.
En el aprendizaje no supervisado, el modelo no recibe ningún dato de entrenamiento etiquetado. En cambio, se deja descubrir patrones y relaciones en los datos de forma independiente. Esto se puede usar para identificar grupos o conglomerados en los datos o para encontrar anomalías o patrones inusuales.
Y en el aprendizaje por refuerzo, un agente aprende a interactuar con su entorno para maximizar una recompensa. Implica entrenar a un modelo para que tome decisiones basadas en la retroalimentación que recibe del entorno.
El aprendizaje automático se utiliza en varias aplicaciones, incluido el reconocimiento de imagen y voz, el procesamiento del lenguaje natural, la detección de fraudes y los automóviles autónomos. Tiene el potencial de automatizar muchas tareas y mejorar la toma de decisiones en varias industrias.
Este artículo se centra principalmente en los conceptos de clasificación y regresión, que se incluyen en el aprendizaje automático supervisado. ¡Empecemos!
Clasificación en Machine Learning

La clasificación es una técnica de aprendizaje automático que implica entrenar un modelo para asignar una etiqueta de clase a una entrada dada. Es una tarea de aprendizaje supervisado, lo que significa que el modelo se entrena en un conjunto de datos etiquetados que incluye ejemplos de los datos de entrada y las etiquetas de clase correspondientes.
El modelo tiene como objetivo aprender la relación entre los datos de entrada y las etiquetas de clase para predecir la etiqueta de clase para entradas nuevas e invisibles.
Hay muchos algoritmos diferentes que se pueden usar para la clasificación, incluida la regresión logística, los árboles de decisión y las máquinas de vectores de soporte. La elección del algoritmo dependerá de las características de los datos y del rendimiento deseado del modelo.
Algunas aplicaciones de clasificación comunes incluyen detección de spam, análisis de sentimientos y detección de fraude. En cada uno de estos casos, los datos de entrada pueden incluir texto, valores numéricos o una combinación de ambos. Las etiquetas de clase pueden ser binarias (p. ej., spam o no spam) o multiclase (p. ej., sentimiento positivo, neutral o negativo).
Por ejemplo, considere un conjunto de datos de opiniones de clientes sobre un producto. Los datos de entrada pueden ser el texto de la revisión y la etiqueta de clase puede ser una calificación (p. ej., positiva, neutral, negativa). El modelo se entrenaría en un conjunto de datos de reseñas etiquetadas y luego podría predecir la calificación de una nueva reseña que no había visto antes.
Tipos de algoritmos de clasificación de ML
Hay varios tipos de algoritmos de clasificación en el aprendizaje automático:
Regresión logística
Este es un modelo lineal utilizado para la clasificación binaria. Se utiliza para predecir la probabilidad de que ocurra un determinado evento. El objetivo de la regresión logística es encontrar los mejores coeficientes (pesos) que minimicen el error entre la probabilidad pronosticada y el resultado observado.
Esto se hace mediante el uso de un algoritmo de optimización, como el descenso de gradiente, para ajustar los coeficientes hasta que el modelo se ajuste lo mejor posible a los datos de entrenamiento.
Árboles de decisión
Estos son modelos en forma de árbol que toman decisiones basadas en valores de características. Se pueden utilizar tanto para la clasificación binaria como para la clasificación multiclase. Los árboles de decisión tienen varias ventajas, incluida su simplicidad e interoperabilidad.
También son rápidos para entrenar y hacer predicciones, y pueden manejar datos numéricos y categóricos. Sin embargo, pueden ser propensos al sobreajuste, especialmente si el árbol es profundo y tiene muchas ramas.
Clasificación aleatoria de bosques
Random Forest Classification es un método de conjunto que combina las predicciones de múltiples árboles de decisión para hacer una predicción más precisa y estable. Es menos propenso al sobreajuste que un solo árbol de decisión porque se promedian las predicciones de los árboles individuales, lo que reduce la varianza en el modelo.
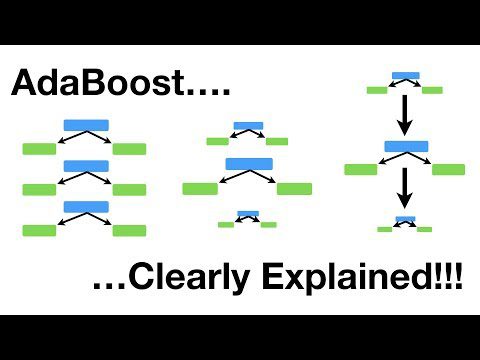
AdaBoost
Este es un algoritmo de refuerzo que cambia de forma adaptativa el peso de los ejemplos mal clasificados en el conjunto de entrenamiento. A menudo se utiliza para la clasificación binaria.
bayesiana ingenua
Naïve Bayes se basa en el teorema de Bayes, que es una forma de actualizar la probabilidad de un evento en función de nueva evidencia. Es un clasificador probabilístico que se usa a menudo para la clasificación de texto y el filtrado de spam.
K-vecino más cercano
K-Nearest Neighbors (KNN) se utiliza para tareas de clasificación y regresión. Es un método no paramétrico que clasifica un punto de datos según la clase de sus vecinos más cercanos. KNN tiene varias ventajas, incluida su simplicidad y el hecho de que es fácil de implementar. También puede manejar datos numéricos y categóricos, y no hace suposiciones sobre la distribución de datos subyacente.
Aumento de gradiente
Estos son conjuntos de aprendices débiles que se entrenan secuencialmente, y cada modelo intenta corregir los errores del modelo anterior. Se pueden utilizar tanto para la clasificación como para la regresión.
Regresión en el aprendizaje automático
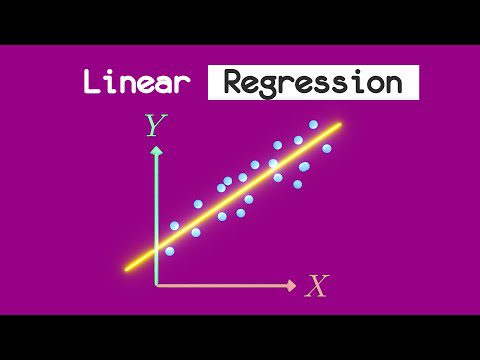
En el aprendizaje automático, la regresión es un tipo de aprendizaje supervisado donde el objetivo es predecir una variable dependiente de ac en función de una o más características de entrada (también llamadas predictores o variables independientes).
Los algoritmos de regresión se utilizan para modelar la relación entre las entradas y la salida y hacer predicciones basadas en esa relación. La regresión se puede utilizar tanto para variables dependientes continuas como categóricas.
En general, el objetivo de la regresión es construir un modelo que pueda predecir con precisión la salida en función de las características de entrada y comprender la relación subyacente entre las características de entrada y la salida.
El análisis de regresión se utiliza en varios campos, incluidos la economía, las finanzas, el marketing y la psicología, para comprender y predecir las relaciones entre diferentes variables. Es una herramienta fundamental en el análisis de datos y el aprendizaje automático y se utiliza para hacer predicciones, identificar tendencias y comprender los mecanismos subyacentes que impulsan los datos.
Por ejemplo, en un modelo de regresión lineal simple, el objetivo podría ser predecir el precio de una casa según su tamaño, ubicación y otras características. El tamaño de la casa y su ubicación serían las variables independientes, y el precio de la casa sería la variable dependiente.
El modelo se entrenaría con datos de entrada que incluyen el tamaño y la ubicación de varias casas, junto con sus precios correspondientes. Una vez que se entrena el modelo, se puede utilizar para hacer predicciones sobre el precio de una casa, dado su tamaño y ubicación.
Tipos de algoritmos de regresión de ML
Los algoritmos de regresión están disponibles en varias formas y el uso de cada algoritmo depende de la cantidad de parámetros, como el tipo de valor de atributo, el patrón de la línea de tendencia y la cantidad de variables independientes. Las técnicas de regresión que se utilizan a menudo incluyen:
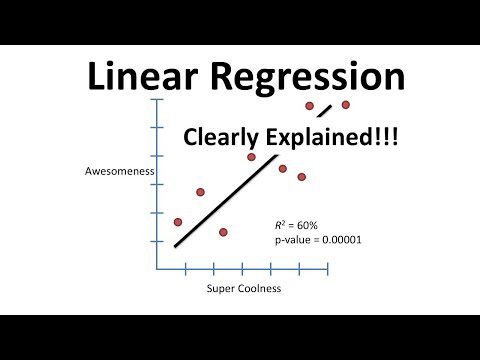
Regresión lineal
Este modelo lineal simple se usa para predecir un valor continuo basado en un conjunto de características. Se utiliza para modelar la relación entre las características y la variable de destino ajustando una línea a los datos.
Regresión polinomial
Este es un modelo no lineal que se utiliza para ajustar una curva a los datos. Se utiliza para modelar las relaciones entre las características y la variable de destino cuando la relación no es lineal. Se basa en la idea de agregar términos de orden superior al modelo lineal para capturar relaciones no lineales entre las variables dependientes e independientes.
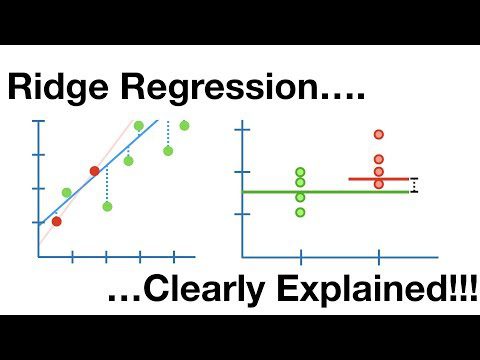
Regresión de cresta
Este es un modelo lineal que aborda el sobreajuste en la regresión lineal. Es una versión regularizada de regresión lineal que agrega un término de penalización a la función de costo para reducir la complejidad del modelo.
Regresión de vectores de soporte
Al igual que las SVM, la regresión de vectores de soporte es un modelo lineal que intenta ajustar los datos encontrando el hiperplano que maximiza el margen entre las variables dependientes e independientes.
Sin embargo, a diferencia de las SVM, que se usan para clasificación, SVR se usa para tareas de regresión, donde el objetivo es predecir un valor continuo en lugar de una etiqueta de clase.
Regresión de lazo
Este es otro modelo lineal regularizado que se utiliza para evitar el sobreajuste en la regresión lineal. Agrega un término de penalización a la función de costo basado en el valor absoluto de los coeficientes.
Regresión lineal bayesiana
La regresión lineal bayesiana es un enfoque probabilístico de la regresión lineal basado en el teorema de Bayes, que es una forma de actualizar la probabilidad de un evento en función de nueva evidencia.
Este modelo de regresión tiene como objetivo estimar la distribución posterior de los parámetros del modelo dados los datos. Esto se hace definiendo una distribución previa sobre los parámetros y luego usando el teorema de Bayes para actualizar la distribución en función de los datos observados.
Regresión vs Clasificación
La regresión y la clasificación son dos tipos de aprendizaje supervisado, lo que significa que se utilizan para predecir una salida en función de un conjunto de características de entrada. Sin embargo, hay algunas diferencias clave entre los dos:
RegresiónClasificaciónDefiniciónUn tipo de aprendizaje supervisado que predice un valor continuoUn tipo de aprendizaje supervisado que predice un valor categóricoTipo de salidaContinuoDiscretoMétricas de evaluaciónError cuadrático medio (MSE), error cuadrático medio (RMSE)Exactitud, precisión, recuperación, puntuación F1AlgoritmosRegresión lineal, Lasso, Ridge, KNN, Árbol de decisiónRegresión logística, SVM, Naïve Bayes, KNN, Árbol de decisiónComplejidad del modeloModelos menos complejosModelos más complejosSupuestosRelación lineal entre las características y el destinoNo hay suposiciones específicas sobre la relación entre las características y el destinoDesequilibrio de clasesNo aplicablePuede ser un problemaExcepcionesPuede afectar el rendimiento del modeloNo suele ser un problemaImportancia de las característicasLas características se clasifican por importanciaCaracterísticas no están clasificados por importanciaAplicaciones de ejemploPredicción de precios, temperaturas, cantidadesPredicción de correo no deseado, predicción de abandono de clientes
Recursos de aprendizaje
Puede ser un desafío elegir los mejores recursos en línea para comprender los conceptos de aprendizaje automático. Hemos examinado los cursos populares proporcionados por plataformas confiables para presentarle nuestras recomendaciones para los mejores cursos de ML sobre regresión y clasificación.
#1. Bootcamp de clasificación de aprendizaje automático en Python
Este es un curso ofrecido en la plataforma Udemy. Cubre una variedad de algoritmos y técnicas de clasificación, incluidos árboles de decisión y regresión logística, y admite máquinas de vectores.

También puede obtener información sobre temas como el sobreajuste, el equilibrio entre sesgo y varianza y la evaluación de modelos. El curso utiliza bibliotecas de Python como sci-kit-learn y pandas para implementar y evaluar modelos de aprendizaje automático. Por lo tanto, se requieren conocimientos básicos de Python para comenzar con este curso.
#2. Clase magistral de regresión de aprendizaje automático en Python
En este curso de Udemy, el entrenador cubre los conceptos básicos y la teoría subyacente de varios algoritmos de regresión, incluida la regresión lineal, la regresión polinomial y las técnicas de regresión Lasso & Ridge.
Al final de este curso, podrá implementar algoritmos de regresión y evaluar el rendimiento de los modelos de aprendizaje automático entrenados utilizando varios indicadores clave de rendimiento.
Terminando
Los algoritmos de aprendizaje automático pueden ser muy útiles en muchas aplicaciones y pueden ayudar a automatizar y optimizar muchos procesos. Los algoritmos de ML usan técnicas estadísticas para aprender patrones en los datos y hacer predicciones o decisiones basadas en esos patrones.
Se pueden entrenar con grandes cantidades de datos y se pueden usar para realizar tareas que serían difíciles o requerirían mucho tiempo para que los humanos las hicieran manualmente.
Cada algoritmo de ML tiene sus puntos fuertes y débiles, y la elección del algoritmo depende de la naturaleza de los datos y los requisitos de la tarea. Es importante elegir el algoritmo apropiado o la combinación de algoritmos para el problema específico que está tratando de resolver.
Es importante elegir el tipo de algoritmo correcto para su problema, ya que usar el tipo de algoritmo incorrecto puede generar un rendimiento deficiente y predicciones inexactas. Si no está seguro de qué algoritmo usar, puede ser útil probar tanto los algoritmos de regresión como los de clasificación y comparar su rendimiento en su conjunto de datos.
Espero que este artículo le haya resultado útil para aprender Regresión frente a clasificación en el aprendizaje automático. También puede estar interesado en conocer los principales modelos de aprendizaje automático.