
La extracción de datos es el proceso de recopilación de datos específicos de páginas web. Los usuarios pueden extraer texto, imágenes, videos, reseñas, productos, etc. Puede extraer datos para realizar estudios de mercado, análisis de sentimientos, análisis de la competencia y datos agregados.
Si está tratando con una pequeña cantidad de datos, puede extraerlos manualmente copiando y pegando la información específica de las páginas web en una hoja de cálculo o formato de documento de su agrado. Por ejemplo, si, como cliente, está buscando reseñas en línea para ayudarlo a tomar una decisión de compra, puede desechar los datos manualmente.
Por otro lado, si se trata de grandes conjuntos de datos, necesita una técnica de extracción de datos automatizada. Puede crear una solución de extracción de datos interna o usar la API de proxy o la API de raspado para tales tareas.
Sin embargo, estas técnicas pueden ser menos efectivas ya que algunos de los sitios a los que apunta pueden estar protegidos por captchas. Es posible que también deba administrar bots y proxies. Tales tareas pueden tomar mucho de su tiempo y limitar la naturaleza del contenido que puede extraer.
Tabla de contenido
Scraping Browser: la solución
Puede superar todos estos desafíos a través del Scraping Browser de Bright Data. Este navegador todo en uno ayuda a recopilar datos de sitios web que son difíciles de raspar. Es un navegador que utiliza una interfaz gráfica de usuario (GUI) y está controlado por Puppeteer o Playwright API, lo que lo hace indetectable para los bots.
Scraping Browser tiene funciones de desbloqueo integradas que manejan automáticamente todos los bloques en su nombre. El navegador se abre en los servidores de Bright Data, lo que significa que no necesita una costosa infraestructura interna para desechar datos para sus proyectos a gran escala.
Características del navegador Bright Data Scraping
- Desbloqueo automático de sitios web: no tiene que seguir actualizando su navegador, ya que este navegador se ajusta automáticamente para manejar la resolución de CAPTCHA, nuevos bloques, huellas dactilares y reintentos. Scraping Browser imita a un usuario real.
- Una gran red de proxies: puede dirigirse a cualquier país que desee, ya que Scraping Browser tiene más de 72 millones de direcciones IP. Puede dirigirse a ciudades o incluso a operadores y beneficiarse de la mejor tecnología de su clase.
- Escalable: puede abrir miles de sesiones simultáneamente ya que este navegador utiliza la infraestructura de Bright Data para manejar todas las solicitudes.
- Compatible con Puppeteer y Playwright: este navegador le permite realizar llamadas a la API y obtener cualquier número de sesiones del navegador, ya sea usando Puppeteer (Python) o Playwright (Node.js).
- Ahorra tiempo y recursos: en lugar de configurar proxies, Scraping Browser se encarga de todo en segundo plano. Tampoco tiene que configurar una infraestructura interna, ya que esta herramienta se encarga de todo en segundo plano.
Cómo configurar el navegador de raspado
- Diríjase al sitio web de Bright Data y haga clic en Scraping Browser en la pestaña «Scraping Solutions».
- Crea una cuenta. Verás dos opciones; «Iniciar prueba gratuita» y «Comenzar gratis con Google». Elijamos «Iniciar prueba gratuita» por ahora y pasemos al siguiente paso. Puede crear la cuenta manualmente o usar su cuenta de Google.
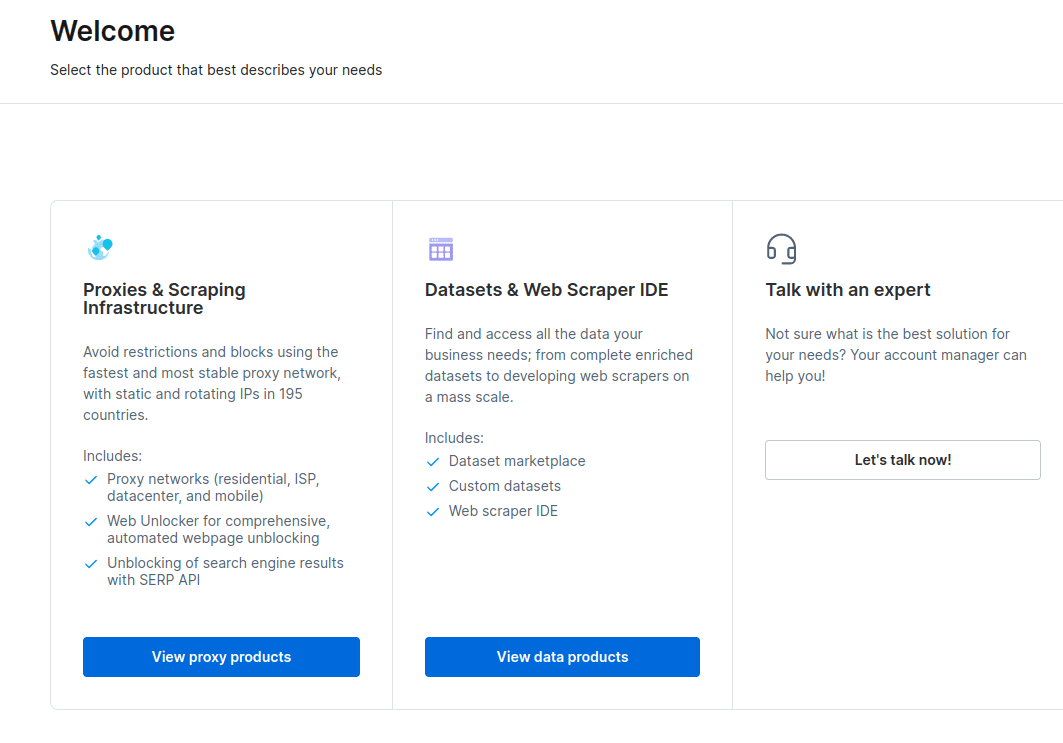
- Cuando se crea su cuenta, el tablero presentará varias opciones. Seleccione «Proxies e infraestructura de raspado».
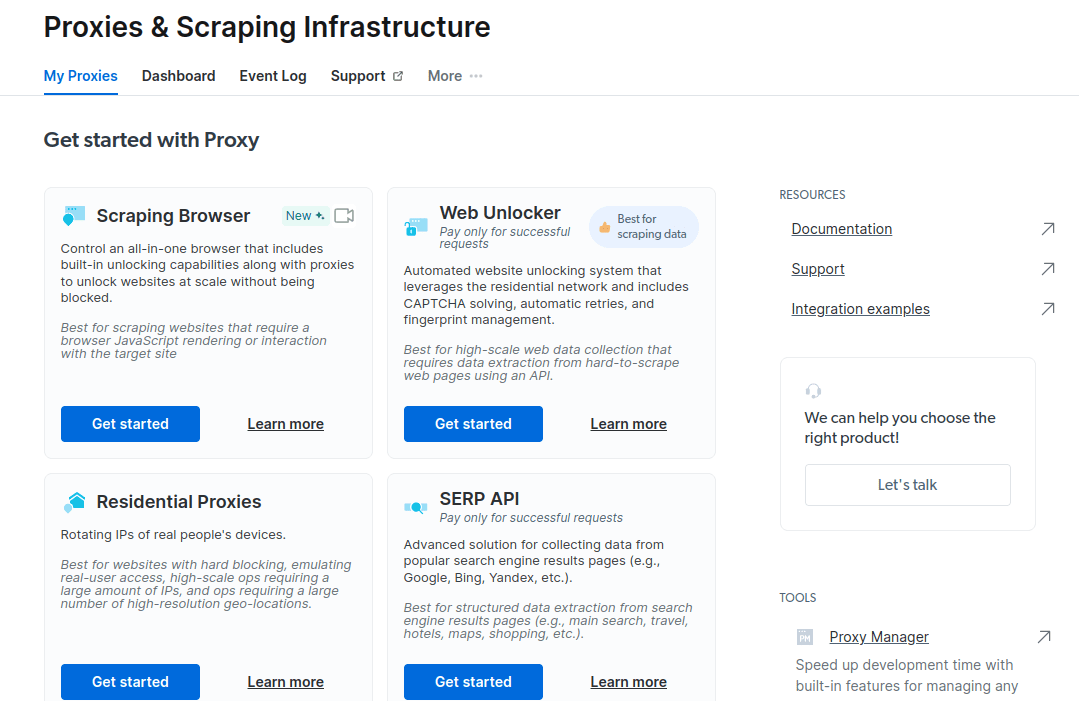
- En la nueva ventana que se abre, seleccione Scraping Browser y haga clic en «Comenzar».
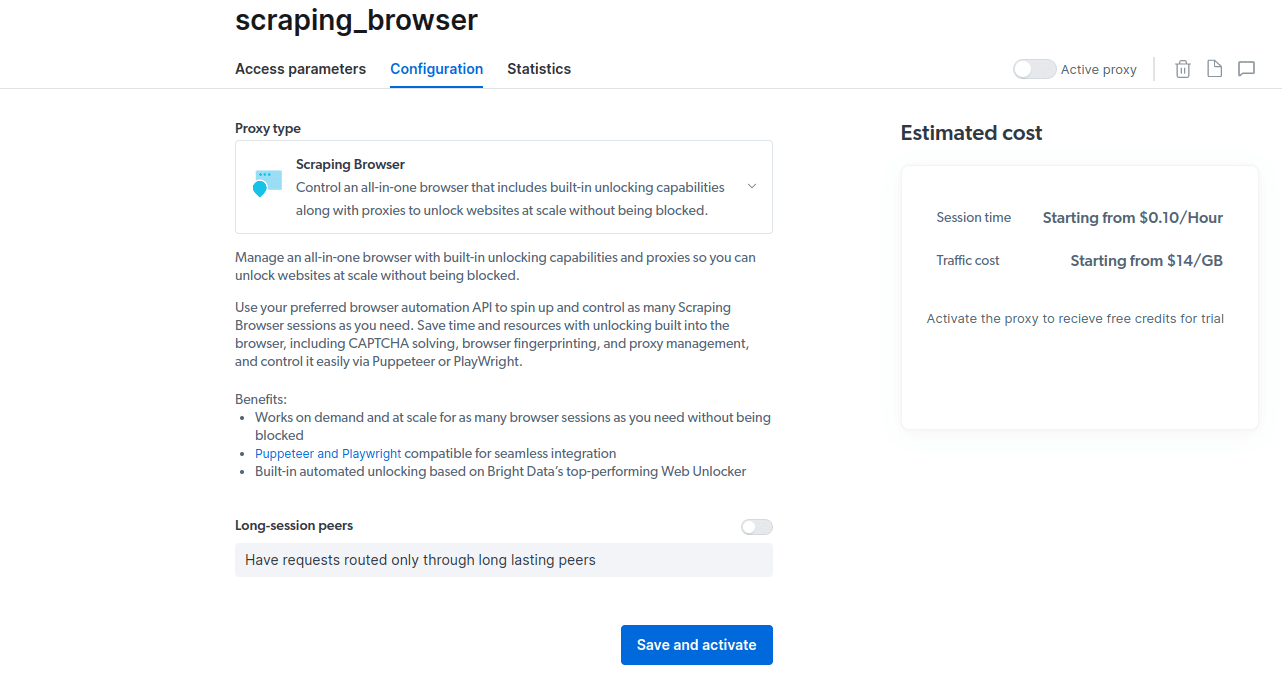
- Guarde y active sus configuraciones.
- Activa tu prueba gratuita. La primera opción le otorga un crédito de $ 5 que puede usar para su uso de proxy. Haga clic en la primera opción para probar este producto. Sin embargo, si es un gran usuario, puede hacer clic en la segunda opción que le otorga $ 50 gratis si carga su cuenta con $ 50 o más.
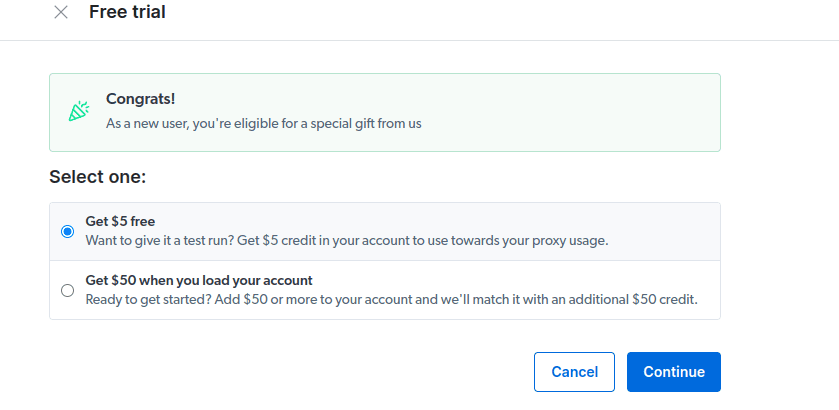
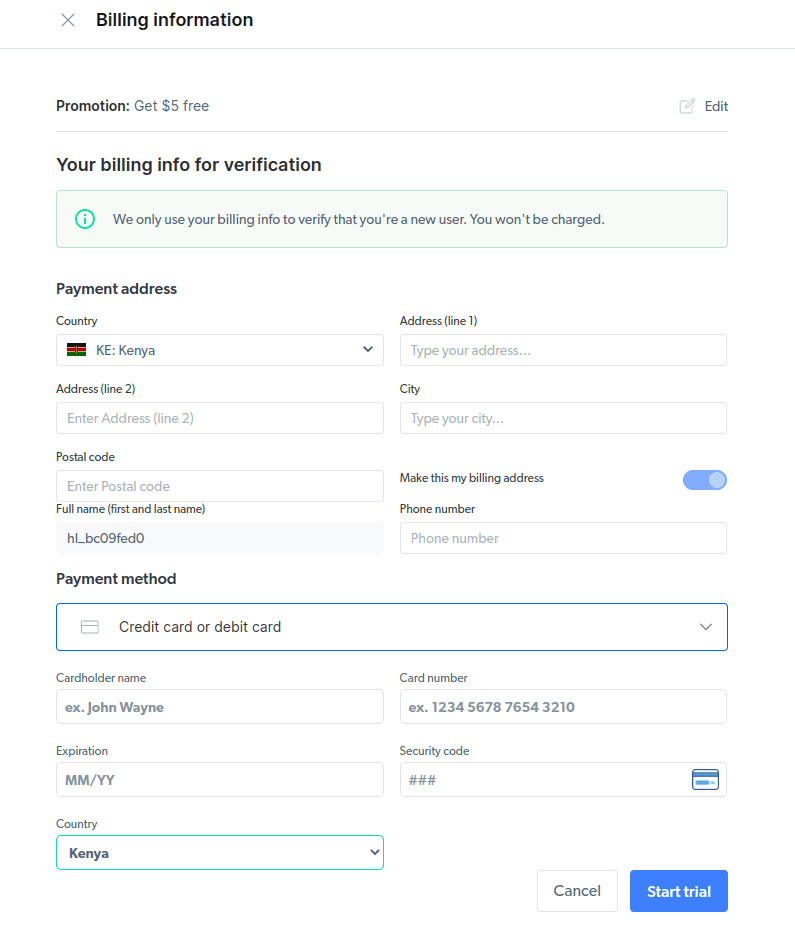
- Introduce tu información de facturación. No te preocupes, ya que la plataforma no te cobrará nada. La información de facturación solo verifica que usted es un usuario nuevo y que no busca obsequios al crear varias cuentas.
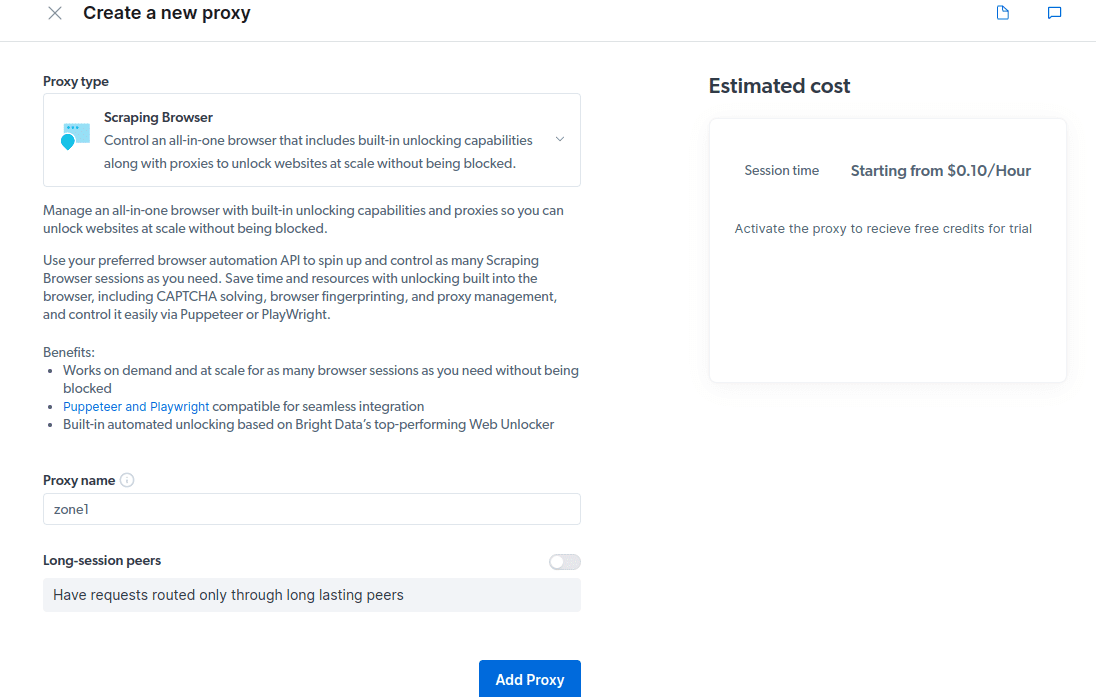
- Cree un nuevo proxy. Una vez que haya guardado sus datos de facturación, puede crear un nuevo proxy. Haga clic en el icono «agregar» y seleccione Scraping Browser como su «tipo de proxy». Haga clic en «Agregar proxy» y avance al siguiente paso.
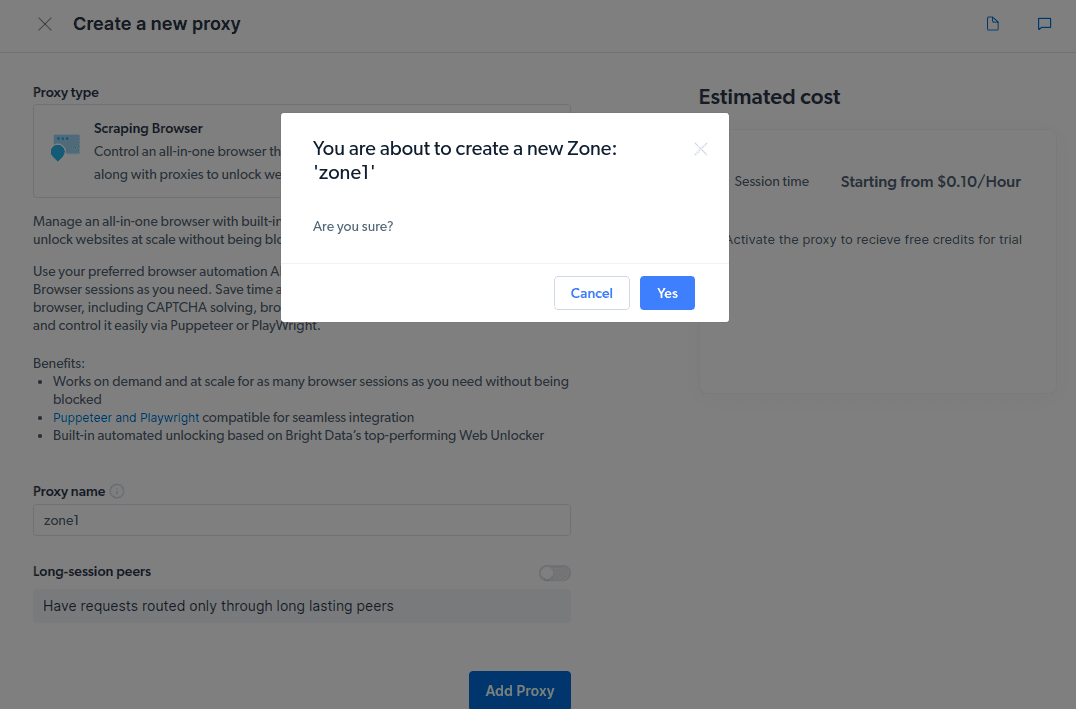
- Crear una nueva «zona». Aparecerá una ventana emergente que le preguntará si desea crear una nueva Zona; haga clic en «Sí» y continúe.
- Haga clic en «Ver código y ejemplos de integración». Ahora obtendrá ejemplos de integración de Proxy que puede usar para desechar datos de su sitio web de destino. Puede usar Node.js o Python para extraer datos de su sitio web de destino.
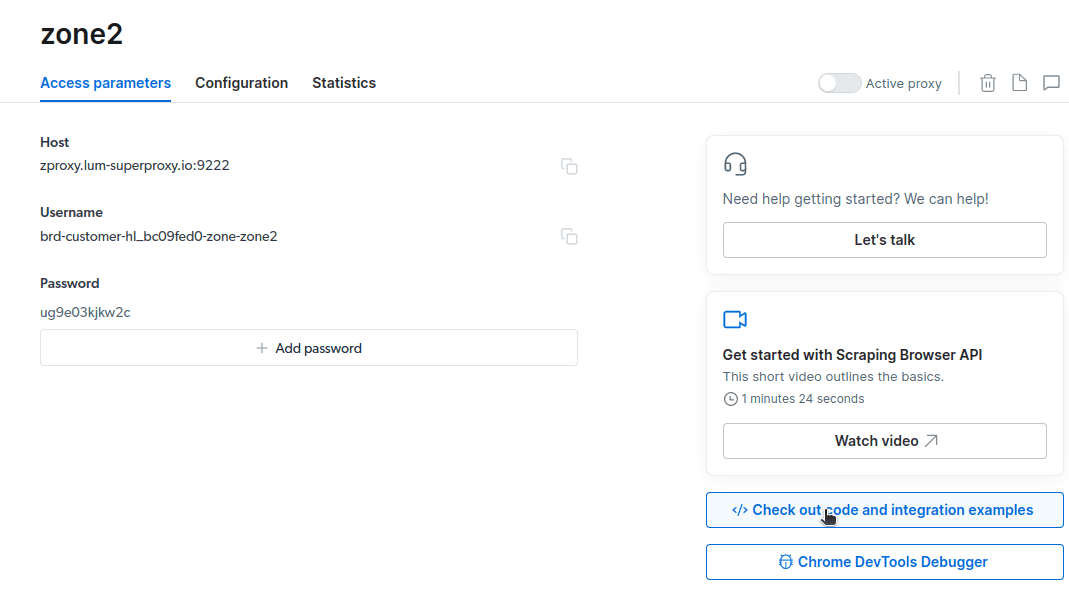
Ahora tiene todo lo que necesita para extraer datos de un sitio web. Utilizaremos nuestro sitio web, kirukiru.es.com, para demostrar cómo funciona Scraping Browser. Para esta demostración, usaremos node.js. Puede seguirlo si tiene instalado node.js.
Sigue estos pasos;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Cambiaré mi código en la línea 10 para que sea el siguiente;
await page.goto(‘https://kirukiru.es.com/authors/‘);
Mi código final ahora será;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://kirukiru.es.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Tendrás algo así en tu terminal
Cómo exportar los datos
Puede usar varios enfoques para exportar los datos, dependiendo de cómo pretenda usarlos. Hoy, podemos exportar los datos a un archivo html cambiando la secuencia de comandos para crear un nuevo archivo llamado data.html en lugar de imprimirlo en la consola.
Puede cambiar el contenido de su código de la siguiente manera;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://kirukiru.es.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Ahora puede ejecutar el código usando este comando;
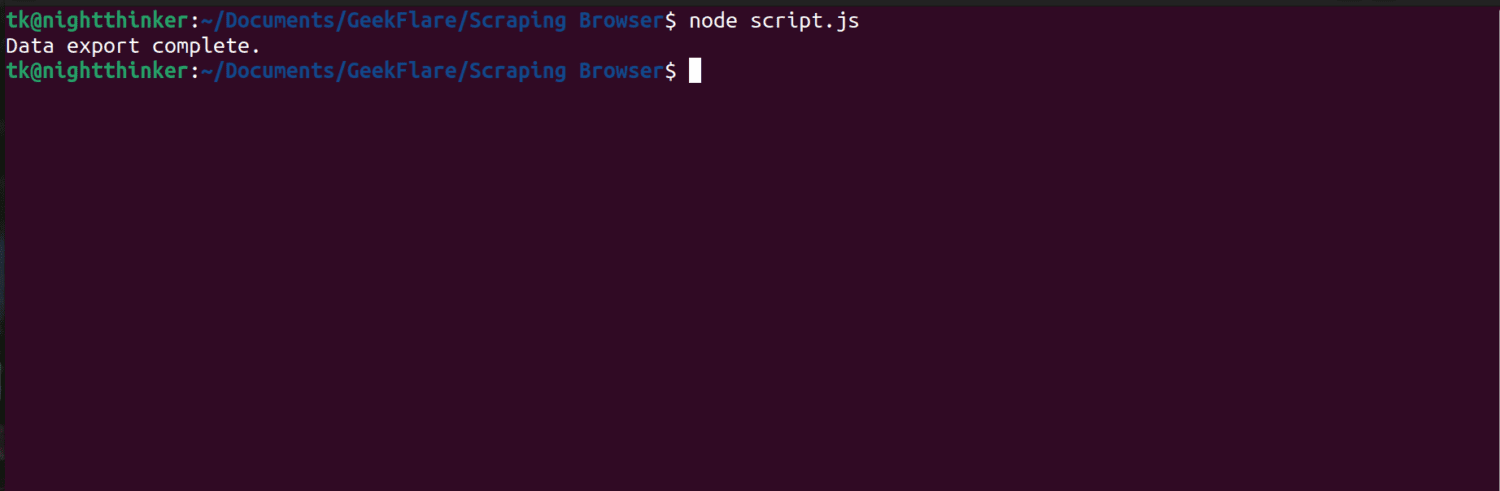
node script.js
Como puede ver en la siguiente captura de pantalla, el terminal muestra un mensaje que dice «exportación de datos completa».
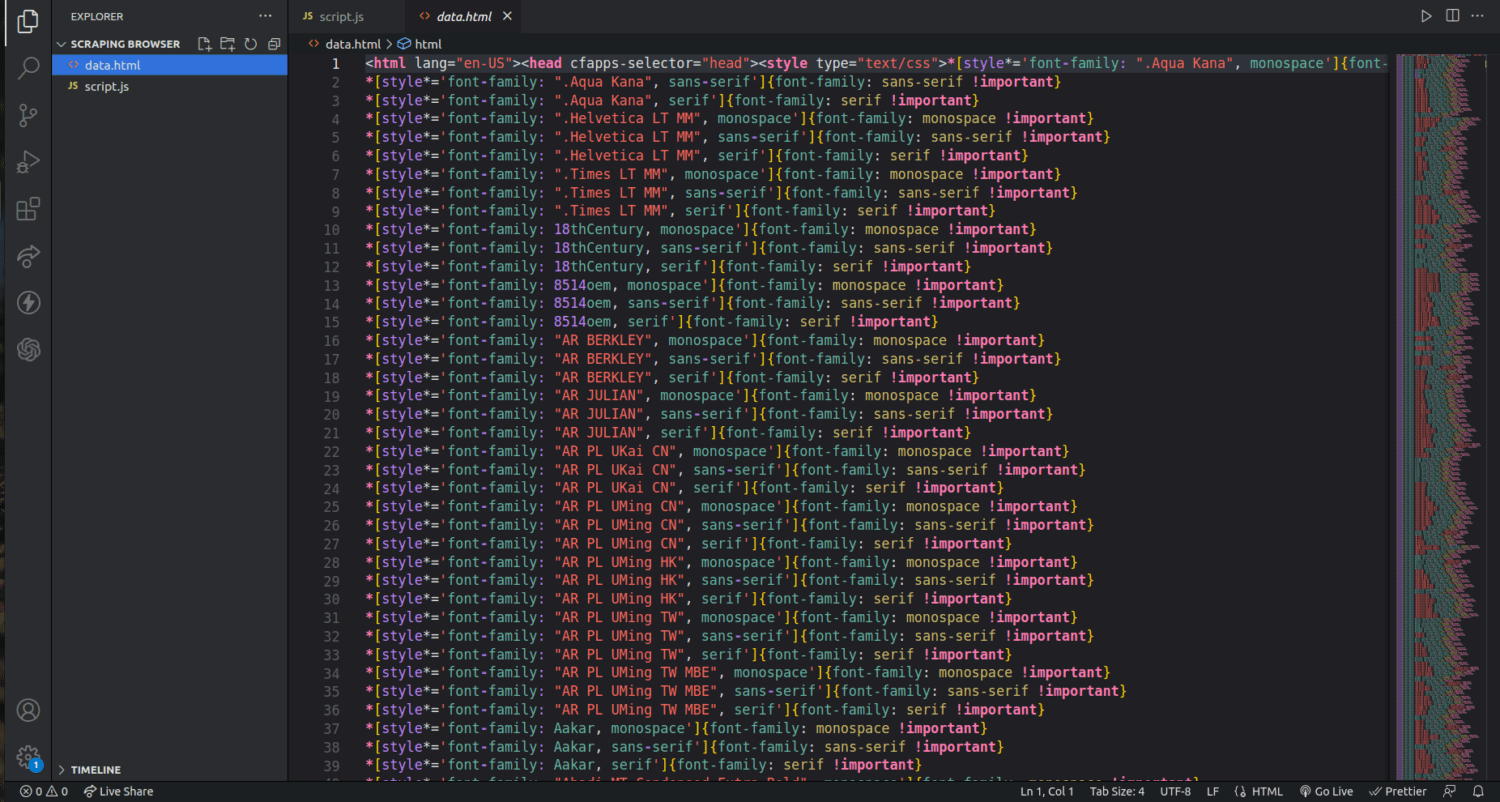
Si revisamos nuestra carpeta de proyectos, ahora podemos ver un archivo llamado data.html con miles de líneas de código.
Acabo de rascar la superficie de cómo extraer datos usando el navegador Scraping. Incluso puedo reducir y descartar solo los nombres de los autores y sus descripciones usando esta herramienta.
Si desea utilizar Scraping Browser, identifique los conjuntos de datos que desea extraer y modifique el código en consecuencia. Puede extraer texto, imágenes, videos, metadatos y enlaces, según el sitio web al que se dirija y la estructura del archivo HTML.
preguntas frecuentes
¿Es legal la extracción de datos y el web scraping?
El web scraping es un tema controvertido, con un grupo que dice que es inmoral mientras que otros sienten que está bien. La legalidad del raspado web dependerá de la naturaleza del contenido que se extrae y de la política de la página web de destino.
En general, el raspado de datos con información personal, como direcciones y detalles financieros, se considera ilegal. Antes de descartar datos, verifique si el sitio al que se dirige tiene alguna directriz. Siempre asegúrese de no desechar los datos que no están disponibles públicamente.
¿Es Scraping Browser una herramienta gratuita?
No. Scraping Browser es un servicio pago. Si se registra para una prueba gratuita, la herramienta le otorga un crédito de $ 5. Los paquetes pagos comienzan desde $15/GB + $0.1/h. También puede optar por la opción Pay As You Go que comienza desde $20/GB + $0.1/h.
¿Cuál es la diferencia entre los navegadores Scraping y los navegadores sin cabeza?
Scraping Browser es un navegador dinámico, lo que significa que tiene una interfaz gráfica de usuario (GUI). Por otro lado, los navegadores sin cabeza no tienen una interfaz gráfica. Los navegadores sin cabeza, como Selenium, se utilizan para automatizar el web scraping, pero a veces están limitados, ya que tienen que lidiar con CAPTCHA y la detección de bots.
Terminando
Como puede ver, Scraping Browser simplifica la extracción de datos de las páginas web. Scraping Browser es fácil de usar en comparación con herramientas como Selenium. Incluso los que no son desarrolladores pueden usar este navegador con una interfaz de usuario increíble y buena documentación. La herramienta tiene capacidades de desbloqueo que no están disponibles en otras herramientas de desguace, lo que la hace efectiva para todos los que desean automatizar dichos procesos.
También puede explorar cómo evitar que los complementos de ChatGPT raspen el contenido de su sitio web.