Bueno, las estadísticas de Forbes indican que hasta el 90% de las organizaciones mundiales utilizan análisis de Big Data para crear sus informes de inversión.
Con la creciente popularidad de Big Data, en consecuencia, hay un aumento en las oportunidades laborales de Hadoop más que antes.
Por lo tanto, para ayudarlo a obtener ese rol de experto en Hadoop, puede usar estas preguntas y respuestas de la entrevista que hemos reunido para usted en este artículo para ayudarlo a superar su entrevista.
Tal vez conocer los hechos como el rango salarial que hace que los roles de Hadoop y Big Data sean lucrativos lo motive a aprobar esa entrevista, ¿verdad? 🤔
- Según Indeed.com, un desarrollador de Big Data Hadoop con sede en EE. UU. gana un salario promedio de $ 144,000.
- Según itjobswatch.co.uk, el salario medio de un desarrollador de Big Data Hadoop es de 66.750 libras esterlinas.
- En India, la fuente de Indeed.com afirma que ganarían un salario promedio de ₹ 16,00,000.
Lucrativo, ¿no crees? Ahora, entremos para aprender sobre Hadoop.
Tabla de contenido
¿Qué es Hadoop?
Hadoop es un marco popular escrito en Java que utiliza modelos de programación para procesar, almacenar y analizar grandes conjuntos de datos.
De forma predeterminada, su diseño permite escalar desde servidores únicos a varias máquinas que ofrecen computación y almacenamiento locales. Además, su capacidad para detectar y manejar fallas en la capa de aplicación que dan como resultado servicios altamente disponibles hace que Hadoop sea bastante confiable.
Pasemos directamente a las preguntas más frecuentes de la entrevista de Hadoop y sus respuestas correctas.
Preguntas y respuestas de la entrevista de Hadoop
¿Qué es la Unidad de Almacenamiento en Hadoop?
Respuesta: La unidad de almacenamiento de Hadoop se denomina Sistema de archivos distribuidos de Hadoop (HDFS).
¿En qué se diferencia el almacenamiento conectado a la red del sistema de archivos distribuido de Hadoop?
Respuesta: HDFS, que es el almacenamiento principal de Hadoop, es un sistema de archivos distribuido que almacena archivos masivos utilizando hardware básico. Por otro lado, NAS es un servidor de almacenamiento de datos informáticos a nivel de archivo que proporciona acceso a los datos a grupos heterogéneos de clientes.
Mientras que el almacenamiento de datos en NAS está en un hardware dedicado, HDFS distribuye los bloques de datos en todas las máquinas dentro del clúster de Hadoop.
NAS utiliza dispositivos de almacenamiento de gama alta, que son bastante costosos, mientras que el hardware básico utilizado en HDFS es rentable.
NAS almacena por separado los datos de los cálculos, por lo que no es adecuado para MapReduce. Por el contrario, el diseño de HDFS le permite trabajar con el marco MapReduce. Los cálculos se trasladan a los datos en el marco MapReduce en lugar de los datos a los cálculos.
Explicar MapReduce en Hadoop y Shuffle
Respuesta: MapReduce se refiere a dos tareas distintas que realizan los programas de Hadoop para permitir una gran escalabilidad en cientos o miles de servidores dentro de un clúster de Hadoop. La reproducción aleatoria, por otro lado, transfiere la salida del mapa de Mappers al Reducer necesario en MapReduce.
Dé un vistazo a la arquitectura Apache Pig
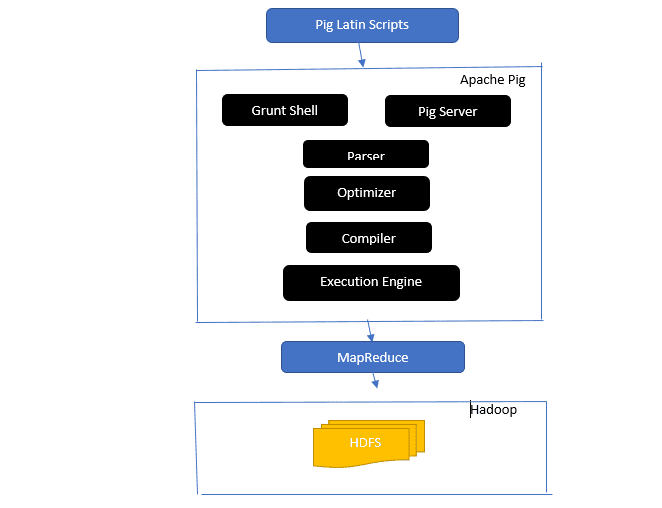 La arquitectura Apache Pig
La arquitectura Apache Pig
Respuesta: la arquitectura Apache Pig tiene un intérprete de Pig Latin que procesa y analiza grandes conjuntos de datos mediante scripts de Pig Latin.
Apache pig también consta de conjuntos de conjuntos de datos en los que se realizan operaciones de datos como unir, cargar, filtrar, ordenar y agrupar.
El lenguaje Pig Latin utiliza mecanismos de ejecución como Grant shells, UDF e incrustados para escribir scripts de Pig que realizan las tareas requeridas.
Pig facilita el trabajo de los programadores al convertir estos scripts escritos en series de trabajos Map-Reduce.
Los componentes de la arquitectura Apache Pig incluyen:
- Parser: maneja los Pig Scripts al verificar la sintaxis del script y realizar la verificación de tipos. La salida del analizador representa las declaraciones y los operadores lógicos de Pig Latin y se llama DAG (gráfico acíclico dirigido).
- Optimizador: el optimizador implementa optimizaciones lógicas como proyección y empuje hacia abajo en el DAG.
- Compilador: compila el plan lógico optimizado del optimizador en una serie de trabajos de MapReduce.
- Motor de ejecución: aquí es donde se produce la ejecución final de los trabajos de MapReduce en el resultado deseado.
- Modo de ejecución: los modos de ejecución en Apache pig incluyen principalmente local y Map Reduce.
Respuesta: El servicio Metastore en Local Metastore se ejecuta en la misma JVM que Hive pero se conecta a una base de datos que se ejecuta en un proceso separado en la misma máquina o en una remota. Por otro lado, Metastore en Remote Metastore se ejecuta en su JVM separada del servicio JVM de Hive.
¿Cuáles son las Cinco V de Big Data?
Respuesta: Estas cinco V representan las características principales de Big Data. Incluyen:
- Valor: Big data busca brindar beneficios significativos de alto retorno de la inversión (ROI) a una organización que utiliza big data en sus operaciones de datos. Big data aporta este valor a partir de su descubrimiento de información y reconocimiento de patrones, lo que da como resultado relaciones más sólidas con los clientes y operaciones más efectivas, entre otros beneficios.
- Variedad: Esto representa la heterogeneidad del tipo de tipos de datos recopilados. Los diversos formatos incluyen CSV, videos, audio, etc.
- Volumen: Esto define la cantidad y el tamaño significativos de los datos administrados y analizados por una organización. Estos datos representan un crecimiento exponencial.
- Velocidad: esta es la tasa de velocidad exponencial para el crecimiento de datos.
- Veracidad: La veracidad se refiere a cuán ‘inciertos’ o ‘inexactos’ están disponibles los datos debido a que los datos son incompletos o inconsistentes.
Explicar los diferentes tipos de datos de Pig Latin.
Respuesta: Los tipos de datos en Pig Latin incluyen tipos de datos atómicos y tipos de datos complejos.
Los tipos de datos atómicos son los tipos de datos básicos utilizados en todos los demás idiomas. Incluyen lo siguiente:
- Int: este tipo de datos define un entero de 32 bits con signo. Ejemplo: 13
- Long: Long define un entero de 64 bits. Ejemplo: 10L
- Flotante: define un punto flotante de 32 bits con signo. Ejemplo: 2.5F
- Doble: define un punto flotante de 64 bits con signo. Ejemplo: 23.4
- Booleano: define un valor booleano. Incluye: Verdadero/Falso
- Datetime: define un valor de fecha y hora. Ejemplo: 1980-01-01T00:00.00.000+00:00
Los tipos de datos complejos incluyen:
- Map- Map se refiere a un conjunto de pares clave-valor. Ejemplo: [‘color’#’yellow’, ‘number’#3]
- Bolsa: es una colección de un conjunto de tuplas y utiliza el símbolo ‘{}’. Ejemplo: {(Henry, 32), (Kiti, 47)}
- Tupla: una tupla define un conjunto ordenado de campos. Ejemplo: (Edad, 33)
¿Qué son Apache Oozie y Apache ZooKeeper?
Respuesta: Apache Oozie es un programador de Hadoop a cargo de programar y unir trabajos de Hadoop como un solo trabajo lógico.
Apache Zookeeper, por otro lado, se coordina con varios servicios en un entorno distribuido. Les ahorra tiempo a los desarrolladores simplemente exponiendo servicios simples como sincronización, agrupación, mantenimiento de configuración y nombres. Apache Zookeeper también proporciona soporte listo para usar para la cola y la elección de líderes.
¿Cuál es el papel del combinador, el lector de registros y el particionador en una operación MapReduce?
Respuesta: El combinador actúa como un mini reductor. Recibe y trabaja con los datos de las tareas del mapa y luego pasa la salida de los datos a la fase de reducción.
RecordHeader se comunica con InputSplit y convierte los datos en pares clave-valor para que el mapeador los lea adecuadamente.
El particionador es responsable de decidir la cantidad de tareas reducidas requeridas para resumir los datos y confirmar cómo se envían las salidas del combinador al reductor. El particionador también controla la partición de claves de las salidas del mapa intermedio.
Mencione diferentes distribuciones específicas de proveedores de Hadoop.
Respuesta: Los diversos proveedores que amplían las capacidades de Hadoop incluyen:
- Plataforma abierta de IBM.
- Distribución Cloudera CDH Hadoop
- Distribución MapR Hadoop
- Amazon Elastic Map Reduce
- Plataforma de datos de Hortonworks (HDP)
- Suite de Big Data fundamental
- Análisis empresarial de Datastax
- HDInsight de Microsoft Azure: distribución de Hadoop basada en la nube.
¿Por qué HDFS es tolerante a fallas?
Respuesta: HDFS replica datos en diferentes DataNodes, lo que lo hace tolerante a fallas. El almacenamiento de los datos en diferentes nodos permite la recuperación desde otros nodos cuando un modo falla.
Diferenciar entre una federación y alta disponibilidad.
Respuesta: HDFS Federation ofrece tolerancia a fallas que permite el flujo continuo de datos en un nodo cuando otro falla. Por otro lado, la alta disponibilidad requerirá dos máquinas separadas que configuren el NameNode activo y el NameNode secundario en la primera y la segunda máquina por separado.
La federación puede tener un número ilimitado de NameNodes no relacionados, mientras que en Alta disponibilidad, solo están disponibles dos NameNodes relacionados, activo y en espera, que funcionan continuamente.
Los NameNodes de la federación comparten un grupo de metadatos, y cada NameNode tiene su propio grupo dedicado. Sin embargo, en alta disponibilidad, los NameNodes activos se ejecutan uno por uno, mientras que los NameNodes en espera permanecen inactivos y solo actualizan sus metadatos ocasionalmente.
¿Cómo encontrar el estado de los bloques y la salud del sistema de archivos?
Respuesta: Utiliza el comando hdfs fsck / tanto en el nivel de usuario raíz como en un directorio individual para verificar el estado de salud del sistema de archivos HDFS.
Comando HDFS fsck en uso:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
La descripción del comando:
- -files: Imprime los archivos que estás revisando.
- –ubicaciones: Imprime las ubicaciones de todos los bloques durante la verificación.
Comando para comprobar el estado de los bloques:
hdfs fsck <path> -files -blocks
: Comienza las comprobaciones desde la ruta pasada aquí. - – bloques: Imprime los bloques del archivo durante la comprobación
¿Cuándo se utilizan los comandos rmadmin-refreshNodes y dfsadmin-refreshNodes?
Respuesta: Estos dos comandos son útiles para actualizar la información del nodo durante la puesta en marcha o cuando se completa la puesta en marcha del nodo.
El comando dfsadmin-refreshNodes ejecuta el cliente HDFS y actualiza la configuración del nodo de NameNode. El comando rmadmin-refreshNodes, por otro lado, ejecuta las tareas administrativas de ResourceManager.
¿Qué es un Punto de Control?
Respuesta: Checkpoint es una operación que fusiona los últimos cambios del sistema de archivos con el FSImage más reciente para que los archivos de registro de edición sigan siendo lo suficientemente pequeños para acelerar el proceso de iniciar un NameNode. El punto de control se produce en el NameNode secundario.
¿Por qué usamos HDFS para aplicaciones que tienen grandes conjuntos de datos?
Respuesta: HDFS proporciona una arquitectura DataNode y NameNode que implementa un sistema de archivos distribuido.
Estas dos arquitecturas brindan acceso de alto rendimiento a los datos en clústeres altamente escalables de Hadoop. Su NameNode almacena los metadatos del sistema de archivos en la RAM, lo que da como resultado que la cantidad de memoria limite la cantidad de archivos del sistema de archivos HDFS.
¿Qué hace el comando ‘jps’?
Respuesta: El comando Java Virtual Machine Process Status (JPS) verifica si los demonios de Hadoop específicos, incluidos NodeManager, DataNode, NameNode y ResourceManager, se están ejecutando o no. Se requiere que este comando se ejecute desde la raíz para verificar los nodos operativos en el Host.
¿Qué es la ‘ejecución especulativa’ en Hadoop?
Respuesta: Este es un proceso en el que el nodo maestro en Hadoop, en lugar de corregir las tareas lentas detectadas, inicia una instancia diferente de la misma tarea como una tarea de copia de seguridad (tarea especulativa) en otro nodo. La ejecución especulativa ahorra mucho tiempo, especialmente en un entorno de carga de trabajo intensiva.
Nombre los tres modos en los que se puede ejecutar Hadoop.
Respuesta: Los tres nodos principales en los que se ejecuta Hadoop incluyen:
- El nodo independiente es el modo predeterminado que ejecuta los servicios de Hadoop mediante el sistema de archivos local y un único proceso de Java.
- El nodo pseudodistribuido ejecuta todos los servicios de Hadoop mediante una única implementación de Hadoop ode.
- El nodo totalmente distribuido ejecuta los servicios maestro y esclavo de Hadoop mediante nodos independientes.
¿Qué es una UDF?
Respuesta: UDF (Funciones definidas por el usuario) le permite codificar sus funciones personalizadas que puede usar para procesar valores de columna durante una consulta de Impala.
¿Qué es DistCp?
Respuesta: DistCp o Distributed Copy, en resumen, es una herramienta útil para la copia de datos de gran tamaño entre clústeres o dentro de ellos. Usando MapReduce, DistCp implementa efectivamente la copia distribuida de una gran cantidad de datos, entre otras tareas como el manejo de errores, la recuperación y la generación de informes.
Respuesta: Hive metastore es un servicio que almacena metadatos de Apache Hive para las tablas de Hive en una base de datos relacional como MySQL. Proporciona la API del servicio metastore que permite el acceso a los metadatos.
Defina RDD.
Respuesta: RDD, que significa Resilient Distributed Datasets, es la estructura de datos de Spark y una colección distribuida inmutable de sus elementos de datos que se computa en los diferentes nodos del clúster.
¿Cómo se pueden incluir las bibliotecas nativas en los trabajos de YARN?
Respuesta: Puede implementar esto usando -Djava.library. opción de ruta en el comando o configurando LD+LIBRARY_PATH en el archivo .bashrc usando el siguiente formato:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Explique ‘WAL’ en HBase.
Respuesta: El registro de escritura anticipada (WAL) es un protocolo de recuperación que registra los cambios de datos de MemStore en HBase en el almacenamiento basado en archivos. WAL recupera estos datos si RegionalServer falla o antes de vaciar MemStore.
¿Es YARN un reemplazo para Hadoop MapReduce?
Respuesta: No, YARN no es un reemplazo de Hadoop MapReduce. En cambio, una poderosa tecnología llamada Hadoop 2.0 o MapReduce 2 es compatible con MapReduce.
¿Cuál es la diferencia entre ORDER BY y SORT BY en HIVE?
Respuesta: Si bien ambos comandos obtienen datos de manera ordenada en Hive, los resultados del uso de ORDENAR POR solo pueden ordenarse parcialmente.
Además, ORDENAR POR requiere un reductor para ordenar las filas. Estos reductores necesarios para la salida final también pueden ser múltiples. En este caso, la salida final puede ordenarse parcialmente.
Por otro lado, ORDER BY solo requiere un reductor para un pedido total en salida. También puede usar la palabra clave LIMIT que reduce el tiempo total de clasificación.
¿Cuál es la diferencia entre Spark y Hadoop?
Respuesta: Si bien tanto Hadoop como Spark son marcos de procesamiento distribuido, su diferencia clave es su procesamiento. Donde Hadoop es eficiente para el procesamiento por lotes, Spark es eficiente para el procesamiento de datos en tiempo real.
Además, Hadoop principalmente lee y escribe archivos en HDFS, mientras que Spark utiliza el concepto de conjunto de datos distribuido resistente para procesar datos en RAM.
Según su latencia, Hadoop es un marco informático de alta latencia sin un modo interactivo para procesar datos, mientras que Spark es un marco informático de baja latencia que procesa datos de forma interactiva.
Compara Sqoop y Flume.
Respuesta: Sqoop y Flume son herramientas de Hadoop que recopilan datos de varias fuentes y los cargan en HDFS.
- Sqoop (SQL-to-Hadoop) extrae datos estructurados de bases de datos, incluidas Teradata, MySQL, Oracle, etc., mientras que Flume es útil para extraer datos no estructurados de fuentes de bases de datos y cargarlos en HDFS.
- En términos de eventos impulsados, Flume está impulsado por eventos, mientras que Sqoop no está impulsado por eventos.
- Sqoop utiliza una arquitectura basada en conectores donde los conectores saben cómo conectarse a una fuente de datos diferente. Flume utiliza una arquitectura basada en agentes, con el código escrito siendo el agente a cargo de obtener los datos.
- Debido a la naturaleza distribuida de Flume, puede recopilar y agregar datos fácilmente. Sqoop es útil para la transferencia de datos en paralelo, lo que da como resultado que la salida esté en varios archivos.
Explique el BloomMapFile.
Respuesta: BloomMapFile es una clase que amplía la clase MapFile y utiliza filtros de floración dinámicos que proporcionan una prueba rápida de membresía para las claves.
Enumere la diferencia entre HiveQL y PigLatin.
Respuesta: Si bien HiveQL es un lenguaje declarativo similar a SQL, PigLatin es un lenguaje de flujo de datos procedimental de alto nivel.
¿Qué es la limpieza de datos?
Respuesta: La limpieza de datos es un proceso crucial para eliminar o reparar errores de datos identificados que incluyen datos incorrectos, incompletos, corruptos, duplicados y con formato incorrecto dentro de un conjunto de datos.
Este proceso tiene como objetivo mejorar la calidad de los datos y proporcionar información más precisa, consistente y confiable necesaria para la toma de decisiones eficiente dentro de una organización.
Conclusión💃
Con el aumento actual de las oportunidades laborales de Big data y Hadoop, es posible que desee mejorar sus posibilidades de ingresar. Las preguntas y respuestas de la entrevista de Hadoop de este artículo lo ayudarán a dominar la próxima entrevista.
A continuación, puede consultar buenos recursos para aprender Big Data y Hadoop.
¡La mejor de las suertes! 👍