Apache Parquet proporciona varios beneficios para el almacenamiento y la recuperación de datos en comparación con los métodos tradicionales como CSV.
El formato parquet está diseñado para un procesamiento de datos más rápido de tipos complejos. En este artículo, hablamos sobre cómo el formato Parquet es adecuado para las necesidades de datos cada vez mayores de hoy.
Antes de profundizar en los detalles del formato Parquet, comprendamos qué son los datos CSV y los desafíos que plantean para el almacenamiento de datos.
Tabla de contenido
¿Qué es el almacenamiento de CSV?
Todos hemos oído hablar mucho sobre CSV (valores separados por comas), una de las formas más comunes de organizar y formatear datos. El almacenamiento de datos CSV se basa en filas. Los archivos CSV se almacenan con la extensión .csv. Podemos almacenar y abrir datos CSV usando Excel, Google Sheets o cualquier editor de texto. Los datos se pueden ver fácilmente una vez que se abre el archivo.
Bueno, eso no es bueno, definitivamente no para un formato de base de datos.
Además, a medida que crece el volumen de datos, se vuelve difícil consultar, administrar y recuperar.
Este es un ejemplo de datos almacenados en un archivo .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Si lo vemos en Excel, podemos ver una estructura de filas y columnas como se muestra a continuación:
Desafíos con el almacenamiento de CSV
Los almacenamientos basados en filas como CSV son adecuados para las operaciones de creación, actualización y eliminación.
Entonces, ¿qué pasa con la lectura en CRUD?
Imagine un millón de filas en el archivo .csv anterior. Se necesitaría una cantidad de tiempo razonable para abrir el archivo y buscar los datos que está buscando. No tan genial. La mayoría de los proveedores de la nube, como AWS, cobran a las empresas en función de la cantidad de datos escaneados o almacenados; nuevamente, los archivos CSV consumen mucho espacio.
El almacenamiento CSV no tiene una opción exclusiva para almacenar metadatos, lo que hace que el escaneo de datos sea una tarea tediosa.
Entonces, ¿cuál es la solución rentable y óptima para realizar todas las operaciones CRUD? Exploremos.
¿Qué es el almacenamiento de datos de Parquet?
Parquet es un formato de almacenamiento de código abierto para almacenar datos. Es ampliamente utilizado en los ecosistemas Hadoop y Spark. Los archivos de parquet se almacenan como extensión .parquet.
El parquet es un formato muy estructurado. También se puede utilizar para optimizar datos sin procesar complejos presentes a granel en lagos de datos. Esto puede reducir significativamente el tiempo de consulta.
Parquet hace que el almacenamiento de datos sea eficiente y la recuperación sea más rápida debido a una combinación de formatos de almacenamiento (híbridos) basados en filas y columnas. En este formato, los datos se dividen tanto horizontal como verticalmente. El formato parquet también elimina en gran medida la sobrecarga de análisis.
El formato restringe el número total de operaciones de E/S y, en última instancia, el costo.
Parquet también almacena los metadatos, que almacenan información sobre datos como el esquema de datos, la cantidad de valores, la ubicación de las columnas, el valor mínimo, la cantidad máxima de grupos de filas, el tipo de codificación, etc. Los metadatos se almacenan en diferentes niveles en el archivo. , haciendo que el acceso a los datos sea más rápido.
En el acceso basado en filas como CSV, la recuperación de datos lleva tiempo ya que la consulta tiene que navegar por cada fila y obtener los valores de columna particulares. Con el almacenamiento Parquet, se puede acceder a todas las columnas requeridas a la vez.
En resumen,
- El parquet se basa en la estructura de columnas para el almacenamiento de datos
- Es un formato de datos optimizado para almacenar datos complejos de forma masiva en sistemas de almacenamiento.
- El formato parquet incluye varios métodos para la compresión y codificación de datos
- Reduce significativamente el tiempo de escaneo de datos y el tiempo de consulta y ocupa menos espacio en disco en comparación con otros formatos de almacenamiento como CSV
- Minimiza la cantidad de operaciones de E/S, lo que reduce el costo de almacenamiento y ejecución de consultas
- Incluye metadatos que facilitan la búsqueda de datos.
- Proporciona soporte de código abierto
formato de datos de parquet
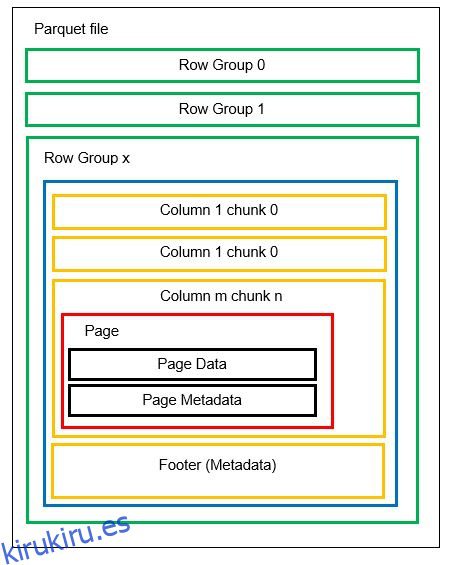
Antes de entrar en un ejemplo, comprendamos cómo se almacenan los datos en el formato Parquet con más detalle:
Podemos tener varias particiones horizontales conocidas como grupos de filas en un archivo. Dentro de cada grupo de filas, se aplica la partición vertical. Las columnas se dividen en varios fragmentos de columna. Los datos se almacenan como páginas dentro de los fragmentos de columna. Cada página contiene los valores de datos codificados y los metadatos. Como mencionamos antes, los metadatos de todo el archivo también se almacenan en el pie de página del archivo en el nivel del grupo Fila.
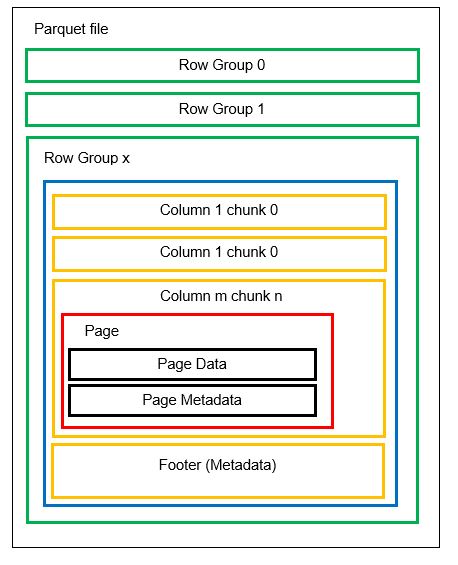
Como los datos se dividen en fragmentos de columna, también es fácil agregar nuevos datos mediante la codificación de los nuevos valores en un nuevo fragmento y archivo. Luego, los metadatos se actualizan para los archivos y grupos de filas afectados. Así, podemos decir que el Parquet es un formato flexible.
Parquet admite de forma nativa la compresión de datos utilizando técnicas de codificación de diccionario y compresión de página. Veamos un ejemplo sencillo de compresión de diccionario:
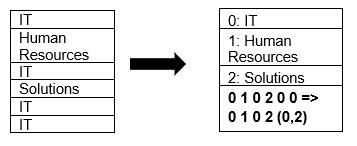
Tenga en cuenta que en el ejemplo anterior, vemos la división de TI 4 veces. Entonces, mientras se almacena en el diccionario, el formato codifica los datos con otro valor fácil de almacenar (0,1,2…) junto con la cantidad de veces que se repite continuamente: IT, IT se cambia a 0,2 para guardar más espacio. Consultar datos comprimidos lleva menos tiempo.
Comparación cara a cara
Ahora que tenemos una idea clara de cómo se ven los formatos CSV y Parquet, es hora de que algunas estadísticas comparen ambos formatos:
CSV
Parquet
Formato de almacenamiento basado en filas.
Un híbrido de formatos de almacenamiento basados en filas y columnas.
Consume mucho espacio ya que no hay ninguna opción de compresión predeterminada disponible. Por ejemplo, un archivo de 1 TB ocupará el mismo espacio cuando se almacene en Amazon S3 o en cualquier otra nube.
Comprime los datos mientras los almacena, por lo que consume menos espacio. Un archivo de 1 TB almacenado en formato Parquet ocupará solo 130 GB de espacio.
El tiempo de ejecución de la consulta es lento debido a la búsqueda basada en filas. Para cada columna, se debe recuperar cada fila de datos.
El tiempo de consulta es unas 34 veces más rápido debido al almacenamiento basado en columnas y la presencia de metadatos.
Se deben escanear más datos por consulta.
Se escanea alrededor de un 99 % menos de datos para la ejecución de la consulta, lo que optimiza el rendimiento.
La mayoría de los dispositivos de almacenamiento cobran según el espacio de almacenamiento, por lo que el formato CSV significa un alto costo de almacenamiento.
Menos costo de almacenamiento ya que los datos se almacenan en formato comprimido y codificado.
El esquema del archivo tiene que ser inferido (lo que lleva a errores) o proporcionado (tedioso).
El esquema del archivo se almacena en los metadatos.
El formato es adecuado para tipos de datos simples.
Parquet es adecuado incluso para tipos complejos como esquemas anidados, matrices, diccionarios.
Conclusión 👩💻
Hemos visto a través de ejemplos que Parquet es más eficiente que CSV en términos de costo, flexibilidad y rendimiento. Es un mecanismo efectivo para almacenar y recuperar datos, especialmente cuando todo el mundo se está moviendo hacia el almacenamiento en la nube y la optimización del espacio. Todas las plataformas principales, como Azure, AWS y BigQuery, admiten el formato Parquet.