En el campo de la inteligencia artificial (IA) moderna, el aprendizaje por refuerzo (RL) es uno de los temas de investigación más interesantes. Los desarrolladores de IA y aprendizaje automático (ML) también se están enfocando en prácticas de RL para improvisar aplicaciones o herramientas inteligentes que desarrollan.
El aprendizaje automático es el principio detrás de todos los productos de IA. Los desarrolladores humanos usan varias metodologías de ML para entrenar sus aplicaciones inteligentes, juegos, etc. ML es un campo muy diversificado y diferentes equipos de desarrollo vienen con métodos novedosos para entrenar una máquina.
Uno de esos métodos lucrativos de ML es el aprendizaje de refuerzo profundo. Aquí, castiga los comportamientos no deseados de la máquina y recompensa las acciones deseadas de la máquina inteligente. Los expertos consideran que este método de ML seguramente empujará a la IA a aprender de sus propias experiencias.
Continúe leyendo esta guía definitiva sobre métodos de aprendizaje por refuerzo para aplicaciones y máquinas inteligentes si está considerando una carrera en inteligencia artificial y aprendizaje automático.
Tabla de contenido
¿Qué es el aprendizaje por refuerzo en el aprendizaje automático?
RL es la enseñanza de modelos de aprendizaje automático a programas informáticos. Luego, la aplicación puede tomar una secuencia de decisiones basadas en los modelos de aprendizaje. El software aprende a alcanzar una meta en un entorno potencialmente complejo e incierto. En este tipo de modelo de aprendizaje automático, una IA se enfrenta a un escenario similar al de un juego.
La aplicación de IA utiliza prueba y error para inventar una solución creativa al problema en cuestión. Una vez que la aplicación de IA aprende los modelos ML adecuados, le indica a la máquina que controla que realice algunas tareas que el programador desea.
Según la decisión correcta y la finalización de la tarea, la IA obtiene una recompensa. Sin embargo, si la IA toma decisiones equivocadas, enfrenta sanciones, como perder puntos de recompensa. El objetivo final de la aplicación de IA es acumular la máxima cantidad de puntos de recompensa para ganar el juego.
El programador de la aplicación de IA establece las reglas del juego o la política de recompensas. El programador también proporciona el problema que la IA debe resolver. A diferencia de otros modelos de ML, el programa AI no recibe ninguna pista del programador de software.
La IA necesita descubrir cómo resolver los desafíos del juego para obtener las máximas recompensas. La aplicación puede usar prueba y error, pruebas aleatorias, habilidades de supercomputadoras y tácticas sofisticadas de procesos de pensamiento para llegar a una solución.
Debes equipar el programa de IA con una poderosa infraestructura informática y conectar su sistema de pensamiento con varios juegos paralelos e históricos. Entonces, la IA puede demostrar una creatividad crítica y de alto nivel que los humanos no pueden imaginar.
Ejemplos populares de aprendizaje por refuerzo
#1. Derrotar al mejor jugador humano de Go
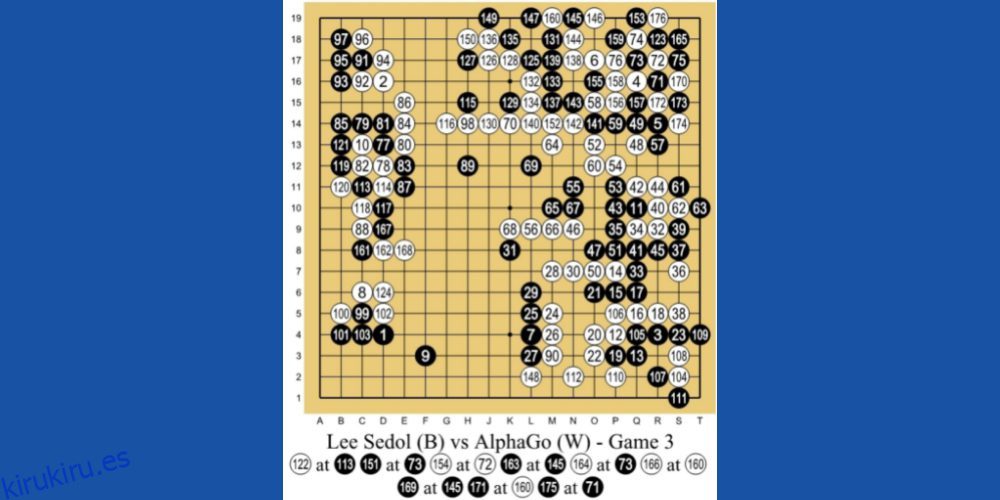
AlphaGo AI de DeepMind Technologies, una subsidiaria de Google, es uno de los principales ejemplos de aprendizaje automático basado en RL. La IA juega un juego de mesa chino llamado Go. Es un juego de 3000 años de antigüedad que se enfoca en tácticas y estrategias.
Los programadores utilizaron el método de enseñanza RL para AlphaGo. Jugó miles de sesiones de juegos de Go con humanos y consigo mismo. Luego, en 2016, derrotó al mejor jugador de Go del mundo, Lee Se-dol, en un partido uno contra uno.
#2. Robótica del mundo real
Los seres humanos han estado utilizando la robótica durante mucho tiempo en las líneas de producción donde las tareas están planificadas previamente y son repetitivas. Pero, si necesita hacer un robot de uso general para el mundo real donde las acciones no están planificadas previamente, entonces es un gran desafío.
Pero la IA habilitada para el aprendizaje por refuerzo podría descubrir una ruta fácil, navegable y corta entre dos ubicaciones.
#3. Vehículos autónomos
Los investigadores de vehículos autónomos utilizan ampliamente el método RL para enseñar a sus IA para:
- Ruta dinámica
- Optimización de trayectoria
- Planificación de movimiento como estacionamiento y cambio de carril
- Controladores de optimización, (unidad de control electrónico) ECU, (microcontroladores) MCU, etc.
- Aprendizaje basado en escenarios en autopistas
#4. Sistemas de refrigeración automatizados

Las IA basadas en RL pueden ayudar a minimizar el consumo de energía de los sistemas de refrigeración en edificios de oficinas gigantes, centros de negocios, centros comerciales y, lo que es más importante, centros de datos. La IA recopila datos de miles de sensores de calor.
También recopila datos sobre las actividades humanas y de maquinaria. A partir de estos datos, la IA puede prever el potencial futuro de generación de calor y encender y apagar adecuadamente los sistemas de refrigeración para ahorrar energía.
Cómo configurar un modelo de aprendizaje por refuerzo
Puede configurar un modelo RL basado en los siguientes métodos:
#1. Basado en políticas
Este enfoque permite al programador de IA encontrar la política ideal para obtener las máximas recompensas. Aquí, el programador no utiliza la función de valor. Una vez que establece el método basado en políticas, el agente de aprendizaje por refuerzo intenta aplicar la política para que las acciones que realiza en cada paso permitan que la IA maximice los puntos de recompensa.
Existen principalmente dos tipos de pólizas:
#1. Determinista: la política puede producir las mismas acciones en cualquier estado dado.
#2. Estocástico: Las acciones producidas están determinadas por la probabilidad de ocurrencia.
#2. basado en valores
El enfoque basado en valores, por el contrario, ayuda al programador a encontrar la función de valor óptima, que es el valor máximo bajo una política en cualquier estado dado. Una vez aplicado, el agente de RL espera el retorno a largo plazo en uno o varios estados bajo dicha política.
#3. basado en modelos
En el enfoque de RL basado en modelos, el programador de IA crea un modelo virtual para el entorno. Luego, el agente RL se mueve por el entorno y aprende de él.
Tipos de aprendizaje por refuerzo
#1. Aprendizaje por refuerzo positivo (PRL)
El aprendizaje positivo significa agregar algunos elementos para aumentar la probabilidad de que el comportamiento esperado vuelva a ocurrir. Este método de aprendizaje influye positivamente en el comportamiento del agente RL. PRL también mejora la fuerza de ciertos comportamientos de su IA.
El tipo de refuerzo de aprendizaje PRL debería preparar a la IA para adaptarse a los cambios durante mucho tiempo. Pero inyectar demasiado aprendizaje positivo puede conducir a una sobrecarga de estados que pueden reducir la eficiencia de la IA.

#2. Aprendizaje por refuerzo negativo (NRL)
Cuando el algoritmo RL ayuda a la IA a evitar o detener un comportamiento negativo, aprende de él y mejora sus acciones futuras. Se conoce como aprendizaje negativo. Solo proporciona a la IA una inteligencia limitada solo para cumplir con ciertos requisitos de comportamiento.
Casos de uso de la vida real del aprendizaje por refuerzo
#1. Los desarrolladores de soluciones de comercio electrónico han creado herramientas personalizadas para sugerir productos o servicios. Puede conectar la API de la herramienta a su sitio de compras en línea. Luego, la IA aprenderá de los usuarios individuales y sugerirá bienes y servicios personalizados.
#2. Los videojuegos de mundo abierto vienen con posibilidades ilimitadas. Sin embargo, hay un programa de inteligencia artificial detrás del programa del juego que aprende de las entradas de los jugadores y modifica el código del videojuego para adaptarse a una situación desconocida.
#3. Las plataformas de inversión y negociación de acciones basadas en IA utilizan el modelo RL para aprender del movimiento de las acciones y los índices globales. En consecuencia, formulan un modelo de probabilidad para sugerir acciones para invertir o negociar.
#4. Las bibliotecas de videos en línea como YouTube, Metacafe, Dailymotion, etc., usan bots de IA entrenados en el modelo RL para sugerir videos personalizados a sus usuarios.
Aprendizaje por refuerzo vs. Aprendizaje supervisado
El aprendizaje por refuerzo tiene como objetivo entrenar al agente de IA para tomar decisiones secuencialmente. En pocas palabras, puede considerar que la salida de la IA depende del estado de la entrada actual. De manera similar, la próxima entrada al algoritmo RL dependerá de la salida de las entradas anteriores.

Una máquina robótica basada en IA que juega una partida de ajedrez contra un jugador de ajedrez humano es un ejemplo del modelo de aprendizaje automático RL.
Por el contrario, en el aprendizaje supervisado, el programador entrena al agente de IA para que tome decisiones en función de las entradas dadas al inicio o cualquier otra entrada inicial. La IA de conducción autónoma de automóviles que reconoce objetos ambientales es un excelente ejemplo de aprendizaje supervisado.
Aprendizaje por refuerzo vs. Aprendizaje sin supervisión
Hasta ahora, ha entendido que el método RL empuja al agente de IA a aprender de las políticas del modelo de aprendizaje automático. Principalmente, la IA solo realizará aquellos pasos por los que obtiene el máximo de puntos de recompensa. RL ayuda a una IA a improvisar a través de prueba y error.
Por otro lado, en el aprendizaje no supervisado, el programador de IA introduce el software de IA con datos no etiquetados. Además, el instructor de ML no le dice nada a la IA sobre la estructura de datos o qué buscar en los datos. El algoritmo aprende varias decisiones al catalogar sus propias observaciones en los conjuntos de datos desconocidos dados.
Cursos de aprendizaje por refuerzo
Ahora que ha aprendido los conceptos básicos, aquí hay algunos cursos en línea para aprender el aprendizaje de refuerzo avanzado. También obtiene un certificado que puede exhibir en LinkedIn u otras plataformas sociales:
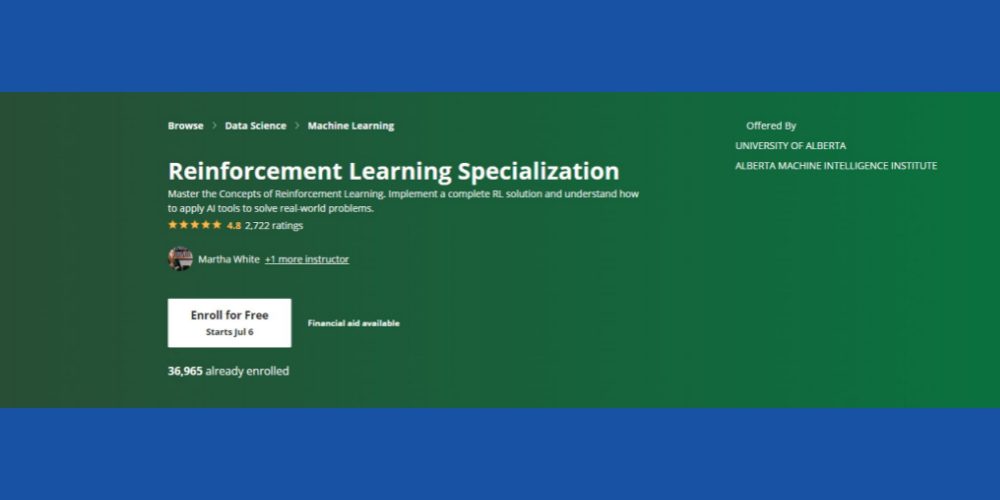
Especialización en aprendizaje por refuerzo: Coursera
¿Está buscando dominar los conceptos básicos del aprendizaje por refuerzo con contexto ML? Puedes probar esto Curso Coursera RL que está disponible en línea y viene con la opción de certificación y aprendizaje a su propio ritmo. El curso será adecuado para ti si traes lo siguiente como habilidades previas:
- Conocimientos de programación en Python
- Conceptos básicos de estadística
- Puede convertir pseudocódigos y algoritmos en códigos de Python
- Experiencia en desarrollo de software de dos a tres años.
- Los estudiantes universitarios de segundo año en la disciplina de ciencias de la computación también son elegibles
El curso tiene una calificación de 4.8 estrellas y más de 36K estudiantes ya se han inscrito en el curso en diferentes cursos de tiempo. Además, el curso viene con ayuda financiera siempre que el candidato cumpla con ciertos criterios de elegibilidad de Coursera.
Finalmente, el Alberta Machine Intelligence Institute de la Universidad de Alberta ofrece este curso (no se otorga crédito). Estimados profesores en el campo de la informática funcionarán como instructores de su curso. Obtendrás un certificado de Coursera al finalizar el curso.
Aprendizaje por refuerzo de IA en Python: Udemy
Si está en el mercado financiero o el marketing digital y desea desarrollar paquetes de software inteligentes para dichos campos, debe consultar este Curso de Udemy en RL. Además de los principios básicos de RL, el contenido de la capacitación también lo orientará sobre cómo desarrollar soluciones de RL para la publicidad en línea y el comercio de acciones.

Algunos temas notables que cubre el curso son:
- Una descripción general de alto nivel de RL
- Programación dinámica
- monet carlo
- Métodos de aproximación
- Proyecto de comercio de acciones con RL
Más de 42K estudiantes han asistido al curso hasta ahora. El recurso de aprendizaje en línea actualmente tiene una calificación de 4.6 estrellas, lo cual es bastante impresionante. Además, el curso tiene como objetivo atender a una comunidad estudiantil global, ya que el contenido de aprendizaje está disponible en francés, inglés, español, alemán, italiano y portugués.
Aprendizaje por refuerzo profundo en Python: Udemy
Si tienes curiosidad y conocimientos básicos de aprendizaje profundo e inteligencia artificial, puedes probar este avanzado Curso de RL en Python de Udemy. Con una calificación de 4,6 estrellas de los estudiantes, es otro curso popular para aprender RL en el contexto de AI/ML.

El curso tiene 12 secciones y cubre los siguientes temas vitales:
- OpenAI Gym y técnicas básicas de RL
- TD lambda
- A3C
- Conceptos básicos de Theano
- Conceptos básicos de Tensorflow
- Codificación Python para principiantes
Todo el curso requerirá una inversión comprometida de 10 horas y 40 minutos. Aparte de los textos, también viene con 79 sesiones de conferencias de expertos.
Experto en aprendizaje por refuerzo profundo: Udacity
¿Quiere aprender aprendizaje automático avanzado de los líderes mundiales en IA/ML como Nvidia Deep Learning Institute y Unity? Udacity te permite cumplir tu sueño. Mira esto Aprendizaje por refuerzo profundo curso para convertirse en un experto en ML.

Sin embargo, debe tener experiencia en Python avanzado, estadísticas intermedias, teoría de la probabilidad, TensorFlow, PyTorch y Keras.
Tomará un aprendizaje diligente de hasta 4 meses para completar el curso. A lo largo del curso, aprenderá algoritmos vitales de RL como Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN), etc.
Ultimas palabras
El aprendizaje por refuerzo es el siguiente paso en el desarrollo de la IA. Las agencias de desarrollo de IA y las empresas de TI están invirtiendo en este sector para crear metodologías de capacitación en IA fiables y fiables.
Aunque RL ha avanzado mucho, hay más ámbitos de desarrollo. Por ejemplo, los agentes de RL independientes no comparten conocimientos entre ellos. Por lo tanto, si está entrenando una aplicación para conducir un automóvil, el proceso de aprendizaje se volverá lento. Porque los agentes de RL, como la detección de objetos, las referencias viales, etc., no compartirán datos.
Hay oportunidades para invertir su creatividad y experiencia en ML en tales desafíos. Inscribirse en cursos en línea lo ayudará a ampliar su conocimiento de los métodos avanzados de RL y sus aplicaciones en proyectos del mundo real.
Otro aprendizaje relacionado para usted son las diferencias entre IA, Machine Learning y Deep Learning.