La fragmentación de bases de datos es una técnica para lograr escalabilidad horizontal en sistemas a gran escala.
Casi todos los sistemas del mundo real consisten en un servidor de base de datos que recibe muchas solicitudes de lectura y una cantidad no despreciable de solicitudes de escritura. Esto podría sobrecargar el servidor y dificultar el rendimiento del sistema.
Para mitigar tales impactos y mejorar el rendimiento de un sistema, existen enfoques como la replicación de bases de datos y la fragmentación de bases de datos. En esta guía, primero exploraremos técnicas para mejorar el rendimiento del sistema, que incluyen:
- Ampliación del servidor de la base de datos
- Replicación de base de datos
- Particiones horizontales
Después de discutir estas técnicas, procederemos a aprender cómo funciona la fragmentación de la base de datos y también veremos las ventajas y limitaciones de este enfoque.
¡Vamos a empezar!
Tabla de contenido
Técnicas para mejorar el rendimiento del sistema
Comencemos discutiendo técnicas para mejorar el rendimiento del sistema cuando hay cuellos de botella debido al servidor de la base de datos:
#1. Ampliación del servidor de la base de datos
Ampliar la instancia del servidor de la base de datos puede parecer un enfoque sencillo para mejorar el rendimiento del sistema. Esto incluye mejorar la potencia de procesamiento, agregar más RAM y cosas por el estilo.
Sin embargo, esta técnica viene con la siguiente limitación. No podemos tener un servidor con capacidad infinita de almacenamiento y procesamiento. Y más allá de cierto límite, obtenemos rendimientos decrecientes.
#2. Replicación de base de datos
Cuando se produce una sobrecarga de la instancia del servidor de la base de datos debido a las solicitudes entrantes, podemos considerar la replicación de la base de datos.
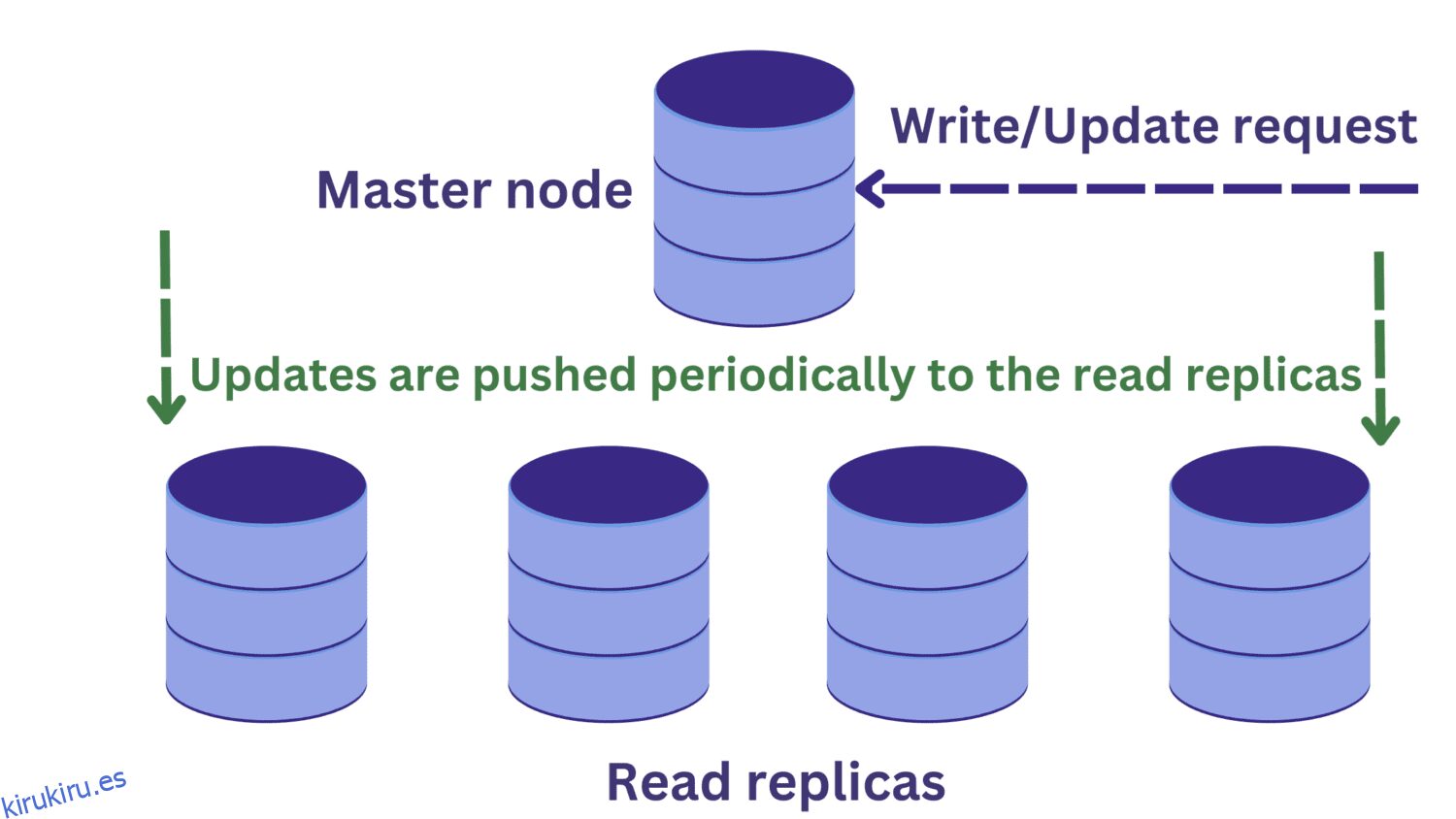
Bajo la replicación de la base de datos, tenemos un nodo maestro que normalmente recibe solicitudes de escritura. Hay varias réplicas de lectura.
Esto mejora la disponibilidad y mitiga la sobrecarga del sistema. Ahora podemos procesar varias consultas en paralelo, ya que las solicitudes de lectura se pueden enrutar a una de las réplicas de lectura.
Pero esto introduce otro problema. Las solicitudes de escritura al nodo principal pueden cambiar los datos y estas actualizaciones se propagan periódicamente a las réplicas de lectura.
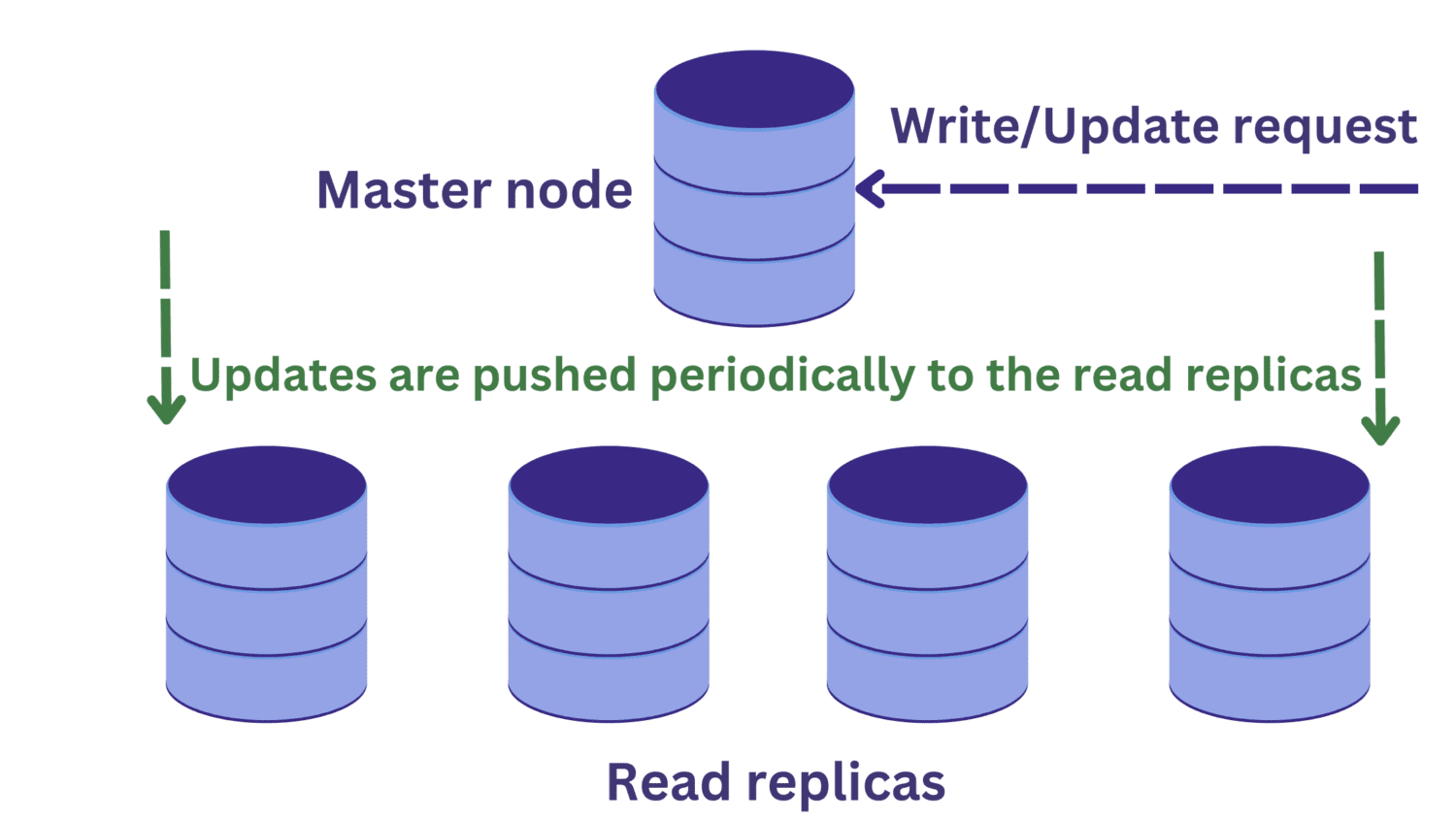
Supongamos que hay una solicitud de lectura para una de las réplicas de lectura al mismo tiempo que una operación de escritura está en curso en el nodo principal.
Los cambios en el nodo maestro aún no se habrán propagado a las réplicas de lectura. En este caso, es posible que estemos leyendo datos desactualizados, lo cual no es deseable.
#3. Particiones horizontales
La partición horizontal es otra técnica para optimizar el rendimiento del sistema. Es posible que tengamos una sola tabla grande con miles de millones de filas (como una tabla de clientes y datos de transacciones).
Las operaciones de lectura de una tabla de base de datos de este tipo son más lentas. Pero al usar la partición horizontal, la única tabla grande ahora se divide en varias particiones (o tablas más pequeñas) de las que podemos leer. Las bases de datos relacionales, como PostgreSQL, admiten de forma nativa la partición.
Sin embargo, todas las particiones todavía están dentro de una sola instancia de servidor de base de datos. La única diferencia es que ahora podemos leer de las particiones en lugar de la única tabla grande.
Por lo tanto, cuando hay un aumento en la cantidad de solicitudes entrantes, es posible que el servidor no pueda admitir el aumento de la demanda.
¿Cómo funciona la fragmentación de la base de datos?
Ahora que hemos discutido los enfoques para mejorar el rendimiento del sistema y sus limitaciones, comprendamos cómo funciona la fragmentación de la base de datos.
En fragmentación, dividimos la única base de datos grande en varias bases de datos más pequeñas, cada una de las cuales se ejecuta en una instancia de servidor de base de datos. Cada base de datos más pequeña se denomina fragmento. Y cada fragmento contiene un subconjunto único de los datos.
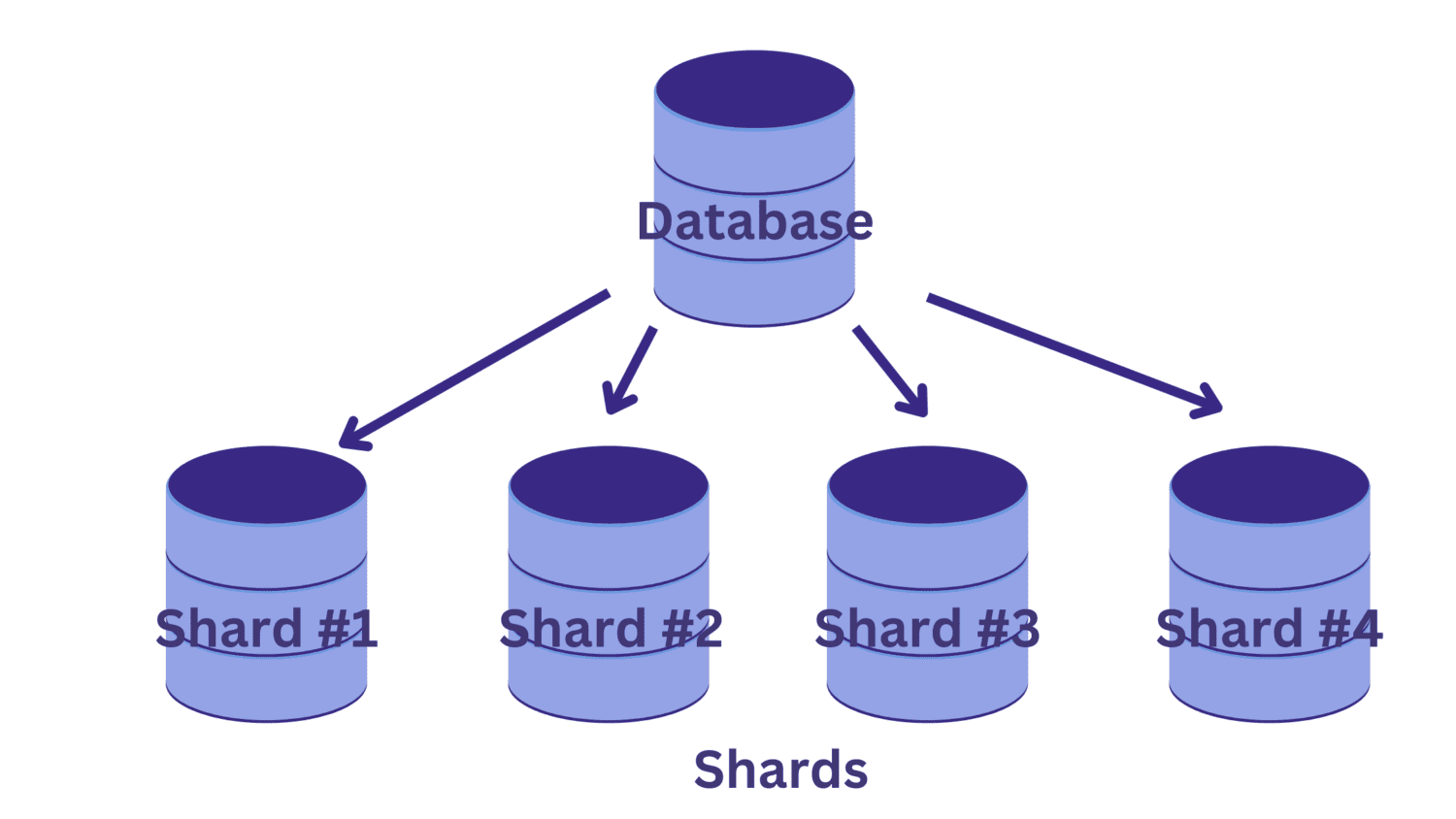
Pero, ¿cómo dividimos la base de datos en fragmentos? ¿Y cómo determinamos cuál de las filas va en cuál de los fragmentos?
🔑 Ingrese la clave de fragmentación.
Comprender la clave de fragmentación
Comprendamos el papel de la clave de fragmentación.
La clave de particionamiento, que suele ser una columna (o una combinación de columnas) en la tabla de la base de datos, debe elegirse de manera que la distribución de los datos sea uniforme entre varios fragmentos. Porque no queremos que un fragmento en particular sea mucho más grande que los otros fragmentos.
En una base de datos que almacena datos sobre clientes y transacciones, el ID_cliente es un buen candidato para la clave de fragmentación.
Una vez que hayamos decidido la clave de fragmentación, podemos crear una función hash que determine cuál de las filas va en cuál de los fragmentos.
En este ejemplo, supongamos que necesitamos dividir la base de datos en cinco fragmentos (del fragmento n.° 0 al fragmento n.° 4) utilizando el ID_cliente como clave de fragmentación. En este caso, una función hash simple es customer_ID % 5.
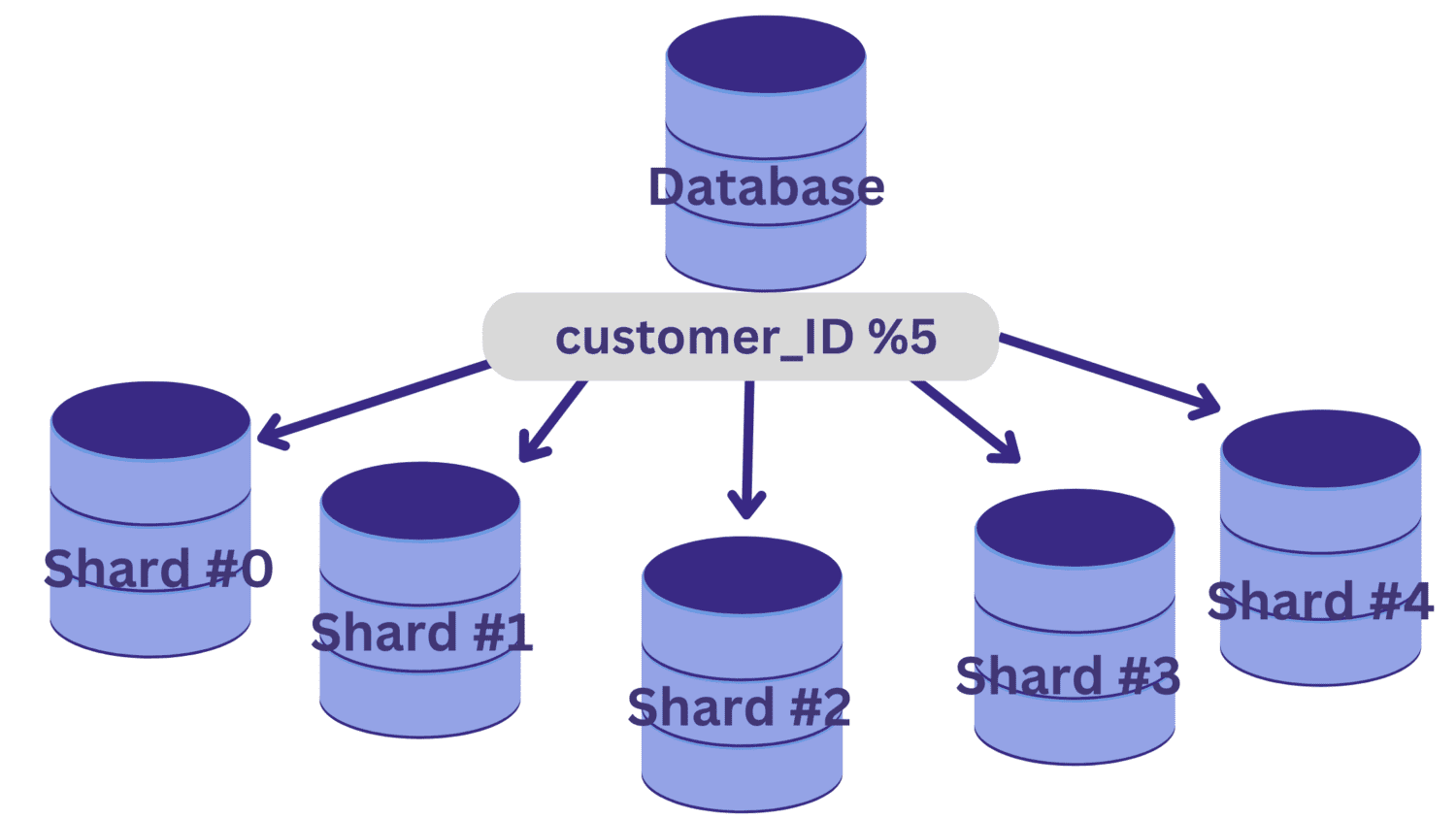
Todos los valores de ID_cliente que dejan un resto de cero cuando se dividen por 5 se asignarán al fragmento #0. Y los valores de ID_cliente que dejan restos del 1 al 4 se asignarán al fragmento n.º 1 al fragmento n.º 4, respectivamente.
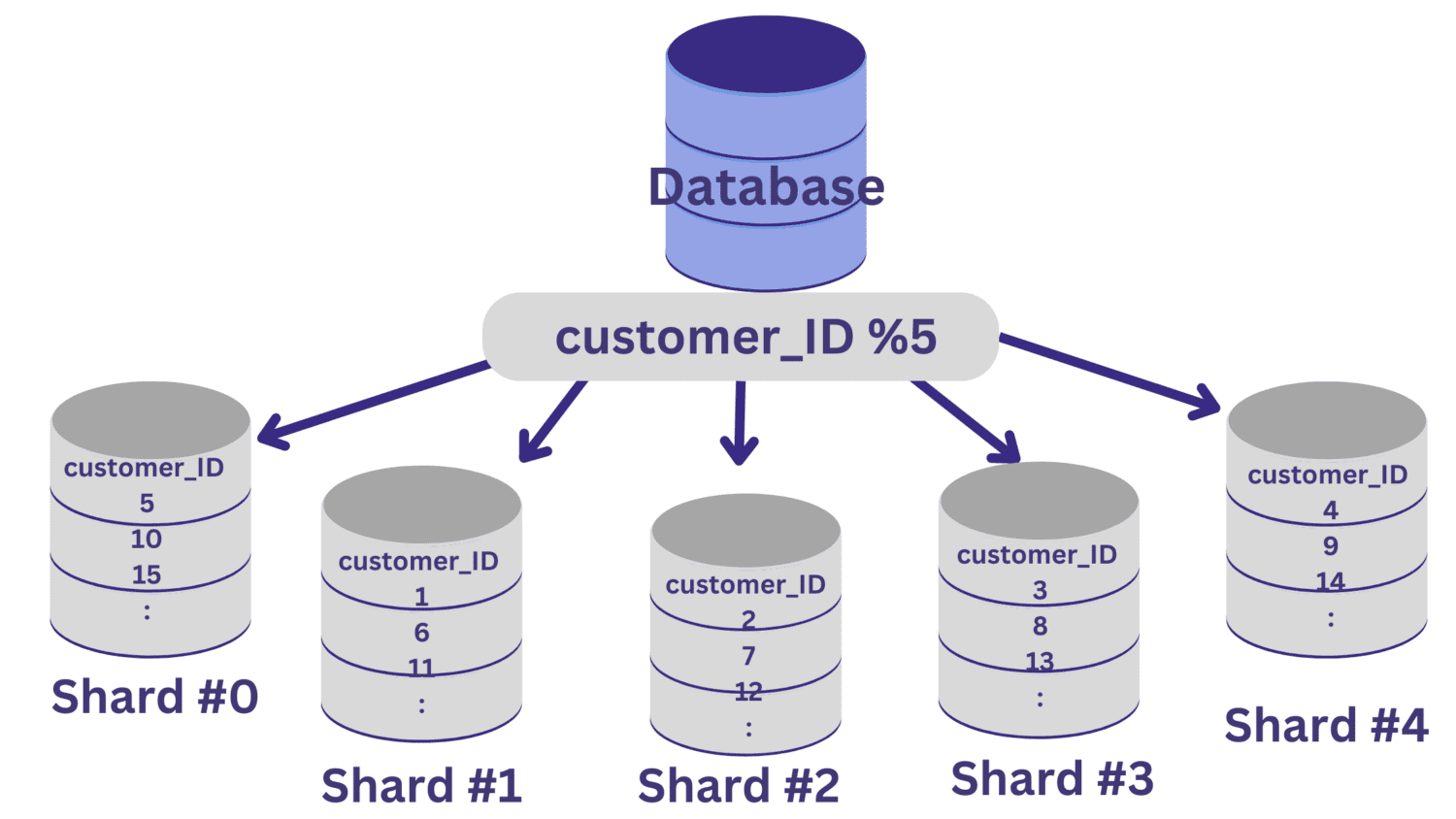
Después de implementar la fragmentación de la base de datos de esta manera, es importante tener una capa de enrutamiento que enrute las solicitudes entrantes al fragmento de base de datos correcto.
Ventajas de la fragmentación de bases de datos
Estas son algunas de las ventajas de la fragmentación de la base de datos:
#1. Alta escalabilidad
Siempre es posible dividir una base de datos más grande en varios fragmentos más pequeños. Por lo tanto, la fragmentación de la base de datos nos permite escalar horizontalmente.
#2. Alta disponibilidad
Cuando hay una sola instancia de servidor de base de datos que maneja todas las solicitudes entrantes, tenemos un único punto de falla. Si el servidor de la base de datos está inactivo, toda la aplicación está inactiva.
Con la fragmentación de la base de datos, la probabilidad de que todos los fragmentos de la base de datos estén inactivos en un instante dado es relativamente baja. Por lo tanto, si un fragmento en particular no funciona, no podremos procesar solicitudes de lectura para ese fragmento. Pero los otros fragmentos aún pueden procesar las solicitudes entrantes. Esto da como resultado una alta disponibilidad y una mayor tolerancia a fallas.
Limitaciones de la fragmentación de la base de datos
Ahora repasemos algunas de las limitaciones de la fragmentación de la base de datos:
#1. Complejidad
Aunque la fragmentación tiene ventajas en términos de escalabilidad y tolerancia a fallas, introduce complejidad en el sistema.
Desde el mapeo de registros a particiones hasta la implementación de la capa de enrutamiento para enrutar consultas a los fragmentos respectivos, existe una complejidad considerable involucrada con las bases de datos fragmentadas.
#2. volver a fragmentar
Otra limitación de la fragmentación es la necesidad de volver a fragmentar.
Aunque usamos la función hash para obtener una distribución uniforme de los registros de datos, es posible que uno de los fragmentos sea mucho más grande que los otros fragmentos y se agote antes. En este caso, tenemos que tener en cuenta el cambio de fragmentos (o reorganización), y eso conlleva una sobrecarga sustancial.
#3. Ejecución de consultas complejas
Cuando necesite ejecutar consultas para análisis que impliquen combinaciones, debe usar registros de varios fragmentos en lugar de una sola base de datos. Por lo tanto, esto puede ser un desafío cuando necesita ejecutar demasiadas consultas analíticas. Puede evitar esto desnormalizando las bases de datos, ¡pero aún requiere un poco de esfuerzo!
Conclusión
Terminemos la discusión con un resumen de lo que hemos aprendido.
Ampliar el hardware no siempre es óptimo. Por lo tanto, no se recomienda reforzar la instancia del servidor. También revisamos técnicas como la replicación de bases de datos y el particionamiento horizontal y sus limitaciones.
Luego, aprendimos cómo funciona la fragmentación de bases de datos al dividir una gran base de datos en fragmentos más pequeños y fáciles de administrar. Discutimos cómo se debe elegir cuidadosamente la clave de fragmentación para obtener particiones uniformes y la necesidad de una capa de enrutamiento para enrutar las solicitudes entrantes al fragmento de base de datos correcto.
La fragmentación de bases de datos tiene ventajas como alta disponibilidad y escalabilidad. Algunas de las desventajas incluyen la complejidad de configurar la fragmentación y la fragmentación cuando se agotan una o más fragmentaciones.
Por lo tanto, puede considerar la fragmentación cuando crea que las ventajas superan la complejidad introducida por la fragmentación. A continuación, consulte la comparación de las diversas bases de datos relacionales de AWS.