
¡Prepárese para conocer todo sobre el futuro de la próxima generación de bases de datos, es decir, bases de datos sin servidor!
Cualquier base de datos que se adhiera a los principios básicos de la computación sin servidor es una base de datos sin servidor. La base de datos sin servidor se creó para cargas de trabajo que son impredecibles y pueden cambiar rápidamente.
Sin servidor no significa que no se necesiten servidores. Significa que no es necesario que usted administre, aprovisione o pague los servidores subyacentes.
Usted paga por los recursos que usa en función de sus capacidades de CPU y RAM y qué tan activos están.
Tabla de contenido
Cómo funciona la base de datos sin servidor
El modelo de base de datos sin servidor se basa en la separación del procesamiento y el almacenamiento. Debe crear un punto final y establecer las capacidades mínimas y máximas.
Crédito de la imagen: Simform
Luego, puede emitir consultas al punto final. Este proxy actúa como un enlace a una gran cantidad de recursos de la base de datos. Esto permite que sus conexiones permanezcan intactas, incluso si las operaciones de escalado ocurren detrás de escena.
Separar el almacenamiento del procesamiento tiene otra ventaja. Es posible reducir el procesamiento a cero y solo tiene que pagar por el almacenamiento. El escalado se puede realizar en solo 5 segundos, según la aplicación. También tiene acceso a un grupo de recursos «tibios» listos para ayudarlo con sus necesidades.
Base de datos sin servidor: ventajas

Eficiencia de costo
Una cantidad fija de servidores es más costosa que una base de datos sin servidor y lleva más tiempo comprarla. Puede ser más económico que configurar un grupo de ajuste de escala automático y también es más rentable porque el empaquetado en contenedores de los recursos de la máquina lo hace más eficiente.
Esto incluye licencias, instalación, mantenimiento, soporte y parches. Solo se le cobra por el tiempo y la memoria que utiliza para ejecutar su código.
Escalabilidad automatizada
Los desarrolladores no necesitan configurar ninguna política o sistema de escalado automático para lograr un escalado sin servidor basado en la carga de trabajo. Todo esto recae sobre los hombros del proveedor de la nube, que debe satisfacer las demandas reales con los poderes de rendimiento adecuados.
Implementaciones y actualizaciones rápidas
La infraestructura sin servidor elimina la necesidad de cargar código en los servidores y configurar los ajustes de back-end para crear una aplicación que funcione. Es fácil para los desarrolladores cargar pequeños fragmentos de código y luego lanzar un nuevo producto. Los desarrolladores pueden cargar ambos códigos a la vez y una función en un momento dado.
Esto facilita la actualización, el parche, la corrección o la adición rápida de nuevas funciones a una aplicación. Los desarrolladores pueden realizar pequeños cambios en una aplicación en lugar de actualizar toda la aplicación.
Mayor productividad
Obtendrás más de tu sistema serverless si le dedicas menos tiempo, te esfuerzas menos en las áreas donde se requiere interacción y contratas un equipo de profesionales con el tamaño óptimo para lograr mejores resultados.
Base de datos sin servidor: desventajas
Problemas de arranque en frio
El manejo de arranques en frío es uno de los aspectos más importantes y desafiantes en este campo. Una base de datos sin servidor que no se utiliza simplemente quedará inactiva para conservar los recursos y evitar un rendimiento innecesario.
El sistema “se despierta” y necesita tiempo para reiniciar todos sus procesos. Es posible que experimente demoras y tiempos de respuesta lentos si es la primera persona en tocar el sistema en su arranque en frío.
Pruebas de dificultad y depuración de aplicaciones.
El modelo sin servidor presenta otro desafío. Es difícil replicar un entorno sin servidor para probar y monitorear el rendimiento del código antes de que se active. Esto se debe en parte al hecho de que los desarrolladores no tienen acceso a los servicios de back-end del proveedor de la nube.
Para depurar sistemas complejos de manera profunda y eficiente, no puede usar un generador de perfiles o un depurador. Tienes la opción de probar herramientas de terceros cada vez más disponibles en el mercado.
Más monitoreo
Las soluciones sin servidor requieren que ponga un mayor énfasis en monitorear y señalar los problemas de rendimiento o el uso excesivo de recursos. Esto se debe en gran parte al hecho de que las soluciones en la nube rara vez son de código abierto.
Dependencia de un proveedor
Al migrar a otro proveedor, elegir un modelo sin servidor puede presentar problemas. Esto se debe a que cada proveedor tiene diferentes flujos de trabajo y características.
Características de la base de datos sin servidor
Las bases de datos sin servidor ofrecen algunas de las características más interesantes, como:
#1. Arquitectura multiusuario
Las bases de datos sin servidor ofrecen la ventaja de poder usar un solo recurso de grupo que se puede usar para múltiples proyectos en su organización. Esta es una gran ventaja para los desarrolladores, ya que no tienen que crear fuentes de datos en silos específicos de la aplicación.
La arquitectura multiinquilino lo hace posible. Los desarrolladores pueden instalar, configurar e implementar múltiples aplicaciones dentro de un único clúster de base de datos.
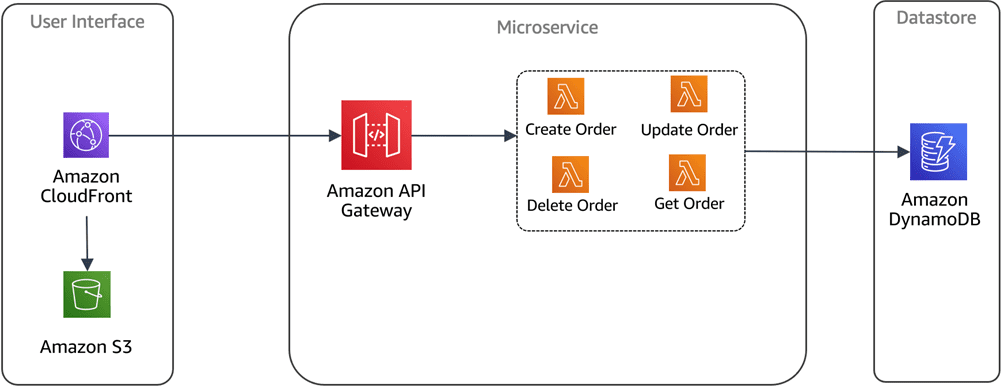 Crédito de la imagen: AWS
Crédito de la imagen: AWS
#2. Distribución geográfica
Debido a que la mayoría de las empresas operan a nivel mundial, es esencial que los datos estén disponibles en todo el mundo. La experiencia en tiempo real se puede mejorar con la proximidad a los centros de datos. También se elimina un punto de falla, por lo que la posibilidad de una interrupción es muy poco probable.
Las bases de datos sin servidor le permiten replicar múltiples conjuntos de datos en todo el mundo sin herramientas adicionales ni desarrollo personalizado.
#3. Poca o ninguna administración manual del servidor
Serverless es un nombre inapropiado. Es una colección de servidores que se han abstraído y están automatizados para que le resulte más fácil administrarlos. Todas las tareas manuales, como el aprovisionamiento, la planificación de la capacidad, el escalado, el mantenimiento, las actualizaciones, etc., se siguen realizando en segundo plano. Son muy fáciles de usar y requieren poca o ninguna intervención manual.
#4. Facturación basada en el consumo
La base de datos sin servidor, ya que sus cargos se basan en el uso, es la más rentable. No se requiere almacenamiento. solo paga por lo que usas. Si desea evitar los excesos de presupuesto, puede establecer un límite de gasto.
Bases de datos sin servidor relacionales y no relacionales

Los datos de la era digital se pueden clasificar en datos operativos y analíticos. Veamos algunas opciones de base de datos diferentes que buscan los desarrolladores y veamos cómo se comparan.
La mayoría de las empresas requieren sistemas OLTP (operativos) y OLAP (analíticos) para almacenar sus datos. Pueden usar una base de datos relacional o no relacional para respaldar sus necesidades comerciales.
Base de datos sin servidor relacional
Una base de datos relacional es un tipo de base de datos que organiza y recopila datos de acuerdo con relaciones predefinidas entre puntos de datos clave. Organiza los datos para que varios usuarios puedan encontrarlos y ordenarlos sin cambiar la categorización lógica de los datos.
Elimina la duplicidad de datos en los procesos de almacenamiento. El lenguaje de consulta estructurado es la interfaz del programa de aplicación (API) para un banco de datos relacional.
Este sistema presenta datos en formato tabular. Esta tabla representa una entidad, como un producto o una aplicación móvil. Cada fila es el valor real y cada fila tiene un identificador único que es una instancia de este tipo de entidad. Por eso se llaman registros.
Las columnas, por otro lado, contienen los atributos de los datos. Son el valor real de la entidad. Es posible acceder a los datos sin tener que reorganizar la tabla de la base de datos.
Base de datos sin servidor NoSQL (no relacional)
Las bases de datos no relacionales (NoSQL) tienen más probabilidades de distribuirse que las bases de datos SQL. Se puede utilizar con un gran número de bases de datos. Las empresas necesitan usar capacidades modernas, como las bases de datos NoSQL, para crear aplicaciones nativas de la nube.
Las bases de datos sin servidor NoSQL se utilizan en aplicaciones web en tiempo real. Tienen un diseño simple y pueden manejar rápidamente grandes cantidades de datos con escalado horizontal. Esto es ideal para situaciones en las que el esquema no está claro y pueden requerirse altas tasas de ingesta.
Las bases de datos sin servidor NoSQL son muy populares ya que almacenan grandes cantidades de datos en muchas formas, incluidos gráficos, documentos, pares clave/valor y estructuras de datos orientadas a columnas. Esto facilita a los desarrolladores la modificación de la estructura de datos.
¿Por qué debería uno usar bases de datos sin servidor?
Las bases de datos sin servidor son una excelente opción para equipos pequeños que no cuentan con suficiente personal para administrar y escalar bases de datos tradicionales. Las bases de datos sin servidor requieren poca infraestructura y mantenimiento. Esto significa que su equipo necesitará dedicar menos tiempo al mantenimiento del sistema. También es fácil crear nuevas tablas y probar nuevas funciones utilizando una base de datos sin servidor.
Finalmente, los costos. Las bases de datos sin servidor le permiten pagar solo por lo que usa sin tener que configurar y ajustar los costos como las bases de datos tradicionales. Las bases de datos sin servidor son ideales para desarrolladores y equipos que necesitan implementar nuevas funciones rápidamente.
Casos de uso de base de datos sin servidor

#1. Nuevas aplicaciones
Unos minutos de uso en el transcurso de una semana o un día. Si tienes un blog con poco tráfico y quieres pagar solo por el tiempo que cualquier usuario accede a tu sitio, esta es una opción. Paga por segundo por los recursos de la base de datos que utiliza.
#2. Cambio de tamaño elástico para transmisión de video en vivo
La transmisión de video en vivo es posible gracias a la arquitectura sin servidor. Múltiples miembros de la audiencia pueden interactuar en escenarios de transmisión de video en vivo. El anfitrión puede estar conectado a múltiples micrófonos simultáneamente. Un anfitrión puede conectar a varios miembros de la audiencia o amigos a la pantalla y luego sintetizar la imagen en un escenario que se presenta a los espectadores de transmisión en vivo.
#3. Aplicaciones de uso poco frecuente
Si tiene una aplicación de la que está orgulloso y no sabe cómo será recibida, y porque no quiere que la aplicación falle, este método es para usted. Simplemente cree un punto final y la base de datos sin servidor escalará automáticamente para satisfacer las necesidades de su aplicación.
#4. Internet de las cosas (IoT)
El IoT se puede describir como un término que describe los dispositivos que se encuentran en los hogares hoy en día y que pueden conectarse a Internet para realizar diversas funciones. Estos dispositivos utilizan cada vez más FaaS para realizar sus tareas. Solo envían y reciben datos cuando un evento los activa.
Las empresas ahorran dinero al no tener que pagar más por la potencia informática que no utilizan. FaaS permite escalar rápida y automáticamente, por lo que los desarrolladores no tienen que preocuparse por patrones de uso impredecibles.
Conclusión
Estos escenarios muestran que la arquitectura sin servidor tiene muchos beneficios para los desarrolladores y las empresas. Las bases de datos sin servidor pueden mejorar la velocidad y la resiliencia de su computación al mismo tiempo que reducen el tiempo y el costo de la escalabilidad y los recursos. Hay muchos tipos de bases de datos sin servidor, tanto relacionales como no relacionales. Sin embargo, todos tienen el mismo objetivo: escalar según la demanda sin agregar cargas de administración y reducir los costos solo en