
A lo largo de los años, el uso de python para la ciencia de datos ha crecido increíblemente y sigue creciendo día a día.
La ciencia de datos es un vasto campo de estudio con muchos subcampos, de los cuales el análisis de datos es indiscutiblemente uno de los más importantes de todos estos campos, e independientemente del nivel de habilidad de uno en ciencia de datos, se ha vuelto cada vez más importante comprender o tener al menos un conocimiento básico del mismo.
Tabla de contenido
¿Qué es el análisis de datos?
El análisis de datos es la limpieza y transformación de una gran cantidad de datos no estructurados o no organizados, con el objetivo de generar conocimientos e información clave sobre estos datos que ayuden a tomar decisiones informadas.
Se utilizan varias herramientas para el análisis de datos, Python, Microsoft Excel, Tableau, SaS, etc., pero en este artículo nos centraremos en cómo se realiza el análisis de datos en Python. Más específicamente, cómo se hace con una biblioteca de python llamada pandas.
¿Qué es Pandas?
Pandas es una biblioteca Python de código abierto que se utiliza para la manipulación y disputa de datos. Es rápido y altamente eficiente y tiene herramientas para cargar varios tipos de datos en la memoria. Se puede usar para remodelar, etiquetar segmentos, indexar o incluso agrupar varias formas de datos.
Estructuras de datos en Pandas
Hay 3 estructuras de datos en Pandas, a saber;
La mejor manera de diferenciar los tres es ver que uno contiene varias pilas del otro. Entonces, un DataFrame es una pila de series y un Panel es una pila de DataFrames.
Una serie es un arreglo unidimensional
Una pila de varias series hace un DataFrame bidimensional
Una pila de varios DataFrames hace un panel tridimensional
La estructura de datos con la que trabajaríamos más es el DataFrame bidimensional, que también puede ser el medio de representación predeterminado para algunos conjuntos de datos con los que nos encontremos.
Análisis de datos en Pandas
Para este artículo, no se necesita instalación. Estaríamos usando una herramienta llamada colaborativo creado por Google. Es un entorno de Python en línea para análisis de datos, aprendizaje automático e IA. Es simplemente un Jupyter Notebook basado en la nube que viene preinstalado con casi todos los paquetes de Python que necesitaría como científico de datos.
Ahora, dirígete a https://colab.research.google.com/notebooks/intro.ipynb. Deberías ver lo siguiente.
En la navegación superior izquierda, haga clic en la opción de archivo y haga clic en la opción «nuevo cuaderno». Vería una nueva página de cuaderno de Jupyter cargada en su navegador. Lo primero que debemos hacer es importar pandas a nuestro entorno de trabajo. Podemos hacerlo ejecutando el siguiente código;
import pandas as pd
Para este artículo, usaríamos un conjunto de datos de precios de viviendas para nuestro análisis de datos. El conjunto de datos que estaríamos usando se puede encontrar aquí. Lo primero que nos gustaría hacer es cargar este conjunto de datos en nuestro entorno.
Podemos hacer eso con el siguiente código en una nueva celda;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
El .read_csv se usa cuando queremos leer un archivo CSV y pasamos una propiedad sep para mostrar que el archivo CSV está delimitado por comas.
También debemos tener en cuenta que nuestro archivo CSV cargado se almacena en una variable df .
No necesitamos usar la función print() en Jupyter Notebook. Simplemente podemos escribir un nombre de variable en nuestra celda y Jupyter Notebook lo imprimirá por nosotros.
Podemos probar eso escribiendo df en una nueva celda y ejecutándolo, imprimirá todos los datos en nuestro conjunto de datos como un DataFrame para nosotros.
Pero no siempre queremos ver todos los datos, a veces solo queremos ver los primeros datos y sus nombres de columna. Podemos usar la función df.head() para imprimir las primeras cinco columnas y df.tail() para imprimir las últimas cinco. La salida de cualquiera de los dos se vería como tal;
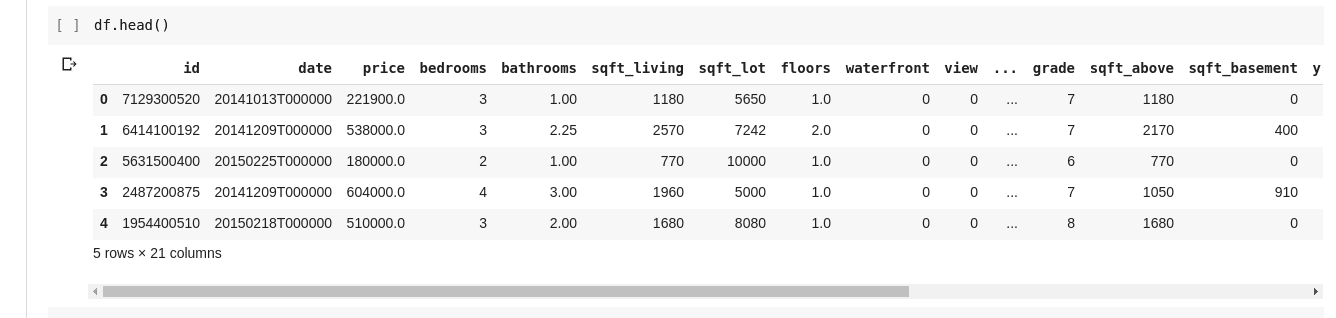
Nos gustaría comprobar las relaciones entre estas varias filas y columnas de datos. La función .describe() hace exactamente esto por nosotros.
Ejecutar df.describe() da el siguiente resultado;
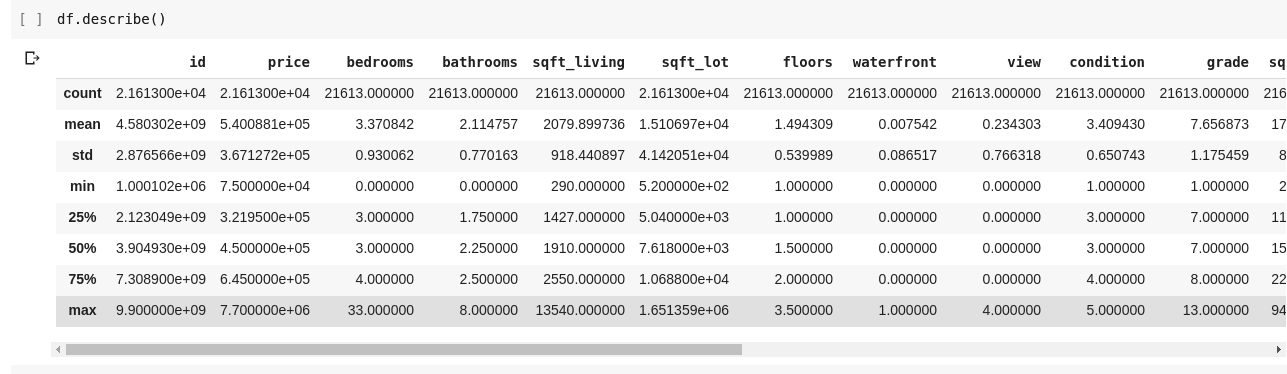
Inmediatamente podemos ver que .describe() proporciona la media, la desviación estándar, los valores mínimos y máximos y los percentiles de todas y cada una de las columnas del DataFrame. Esto es muy útil particularmente.
También podemos comprobar la forma de nuestro DataFrame 2D para saber cuántas filas y columnas tiene. Podemos hacerlo usando df.shape que devuelve una tupla en el formato (filas, columnas).
También podemos verificar los nombres de todas las columnas en nuestro DataFrame usando df.columns.
¿Qué sucede si queremos seleccionar solo una columna y devolver todos los datos que contiene? Esto se hace de una manera similar a cortar un diccionario. Escriba el siguiente código en una nueva celda y ejecútelo
df['price ']
El código anterior devuelve la columna de precio, podemos ir más allá guardándolo en una nueva variable como tal
price = df['price']
Ahora podemos realizar todas las demás acciones que se pueden realizar en un DataFrame en nuestra variable de precio, ya que es solo un subconjunto de un DataFrame real. Podemos hacer cosas como df.head(), df.shape, etc.
También podríamos seleccionar varias columnas pasando una lista de nombres de columnas a df como tal
data = df[['price ', 'bedrooms']]
Lo anterior selecciona columnas con nombres ‘precio’ y ‘dormitorios’, si escribimos data.head() en una nueva celda, tendríamos lo siguiente
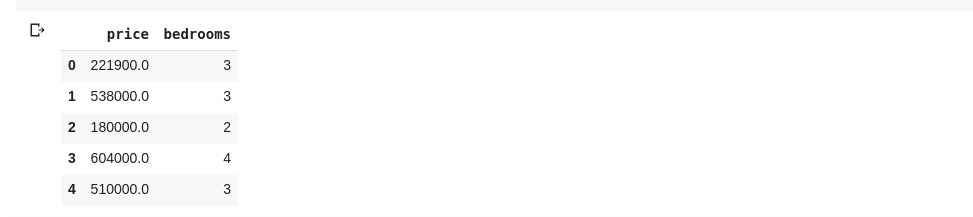
La forma anterior de dividir columnas devuelve todos los elementos de fila en esa columna, ¿qué pasa si queremos devolver un subconjunto de filas y un subconjunto de columnas de nuestro conjunto de datos? Esto se puede hacer usando .iloc y se indexa de manera similar a las listas de python. Entonces podemos hacer algo como
df.iloc[50: , 3]
Lo que devuelve la tercera columna desde la fila 50 hasta el final. Es bastante limpio y es lo mismo que cortar listas en python.
Ahora hagamos algunas cosas realmente interesantes, nuestro conjunto de datos de precios de viviendas tiene una columna que nos dice el precio de una casa y otra columna nos dice la cantidad de habitaciones que tiene esa casa en particular. El precio de la vivienda es un valor continuo, por lo que es posible que no tengamos dos casas que tengan el mismo precio. Pero el número de dormitorios es algo discreto, por lo que podemos tener varias viviendas de dos, tres, cuatro dormitorios, etc.
¿Qué pasa si queremos obtener todas las casas con el mismo número de dormitorios y encontrar el precio medio de cada dormitorio discreto? Es relativamente fácil hacer eso en pandas, se puede hacer como tal;
df.groupby('bedrooms ')['price '].mean()
Lo anterior primero agrupa el DataFrame por los conjuntos de datos con el mismo número de dormitorio usando la función df.groupby(), luego le decimos que nos proporcione solo la columna del dormitorio y use la función .mean() para encontrar la media de cada casa en el conjunto de datos .
¿Y si queremos visualizar lo anterior? Nos gustaría poder comprobar cómo varía el precio medio de cada número de dormitorio distinto. Solo necesitamos encadenar el código anterior a una función .plot() como tal;
df.groupby('bedrooms ')['price '].mean().plot()
Tendremos una salida que se ve como tal;
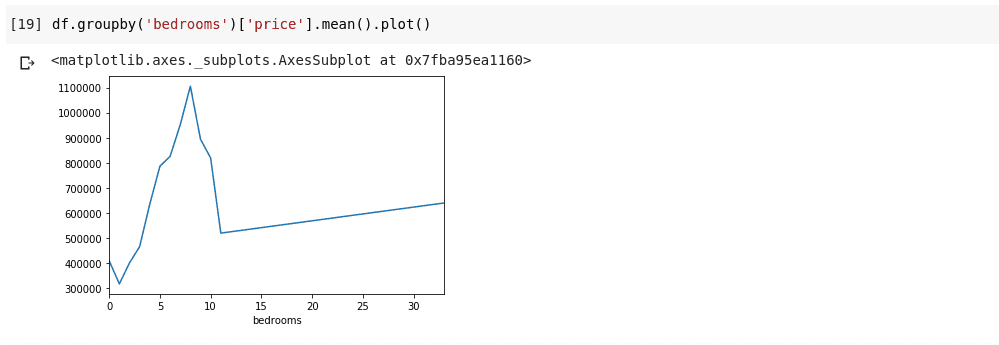
Lo anterior nos muestra algunas tendencias en los datos. En el eje horizontal, tenemos un número distinto de dormitorios (Observe que más de una casa puede tener X número de dormitorios), En el eje vertical, tenemos la media de los precios con respecto al número correspondiente de dormitorios en el horizontal eje. Ahora podemos notar de inmediato que las casas que tienen entre 5 y 10 habitaciones cuestan mucho más que las casas con 3 habitaciones. También será obvio que las casas que tienen alrededor de 7 u 8 habitaciones cuestan mucho más que las que tienen 15, 20 o incluso 30 habitaciones.
Información como la anterior es la razón por la cual el análisis de datos es muy importante, podemos extraer información útil de los datos que no es inmediatamente o es imposible notar sin análisis.
Datos perdidos
Supongamos que estoy realizando una encuesta que consta de una serie de preguntas. Comparto un enlace a la encuesta con miles de personas para que puedan dar su opinión. Mi objetivo final es ejecutar un análisis de datos en estos datos para poder obtener algunas ideas clave de los datos.
Ahora muchas cosas pueden salir mal, algunos encuestadores pueden sentirse incómodos al responder algunas de mis preguntas y dejarlas en blanco. Mucha gente podría hacer lo mismo con varias partes de las preguntas de mi encuesta. Es posible que esto no se considere un problema, pero imagínense si tuviera que recopilar datos numéricos en mi encuesta y una parte del análisis requiriera que obtuviera la suma, la media o alguna otra operación aritmética. Varios valores faltantes darían lugar a muchas inexactitudes en mi análisis, tengo que encontrar una manera de encontrar y reemplazar estos valores faltantes con algunos valores que podrían ser un sustituto cercano a ellos.
Pandas nos proporciona una función para encontrar valores faltantes en un DataFrame llamado isnull().
La función isnull() se puede usar como tal;
df.isnull()
Esto devuelve un DataFrame de valores booleanos que nos dice si los datos presentes originalmente faltaban Verdaderamente o Falsamente. La salida se vería como tal;
Necesitamos una forma de poder reemplazar todos estos valores faltantes, la mayoría de las veces la elección de los valores faltantes se puede tomar como cero. En ocasiones, podría tomarse como la media de todos los demás datos o quizás la media de los datos que lo rodean, según el científico de datos y el caso de uso de los datos que se analizan.
Para completar todos los valores faltantes en un DataFrame, usamos la función .fillna() utilizada como tal;
df.fillna(0)
En lo anterior, estamos llenando todos los datos vacíos con valor cero. También podría ser cualquier otro número que especifiquemos que sea.
No se puede exagerar la importancia de los datos, ¡nos ayudan a obtener respuestas directamente desde nuestros propios datos! El Análisis de Datos dicen que es el nuevo Petróleo para las Economías Digitales.
Todos los ejemplos de este artículo se pueden encontrar aquí.
Para obtener más información, consulte Curso online de Análisis de Datos con Python y Pandas.