
Web scraping es la idea de extraer información de un sitio web y usarla para un caso de uso particular.
Supongamos que intenta extraer una tabla de una página web, convertirla en un archivo JSON y utilizar el archivo JSON para crear algunas herramientas internas. Con la ayuda del raspado web, puede extraer los datos que desea al enfocarse en elementos específicos en una página web. El web scraping con Python es una opción muy popular, ya que Python proporciona múltiples bibliotecas como BeautifulSoup o Scrapy para extraer datos de manera efectiva.
Tener la habilidad de extraer datos de manera eficiente también es muy importante como desarrollador o científico de datos. Este artículo lo ayudará a comprender cómo raspar un sitio web de manera efectiva y obtener el contenido necesario para manipularlo según sus necesidades. Para este tutorial, usaremos el paquete BeautifulSoup. Es un paquete moderno para raspar datos en Python.
Tabla de contenido
¿Por qué usar Python para Web Scraping?
Python es la primera opción para muchos desarrolladores cuando crean web scrapers. Hay muchas razones por las que Python es la primera opción, pero para este artículo, analicemos tres razones principales por las que Python se usa para el raspado de datos.
Soporte de biblioteca y comunidad: hay varias bibliotecas excelentes, como BeautifulSoup, Scrapy, Selenium, etc., que brindan excelentes funciones para raspar páginas web de manera efectiva. Ha construido un ecosistema excelente para el web scraping, y también debido a que muchos desarrolladores en todo el mundo ya usan Python, puede obtener ayuda rápidamente cuando está atascado.
Automatización: Python es famoso por sus capacidades de automatización. Se requiere más que web scraping si está tratando de crear una herramienta compleja que se base en scraping. Por ejemplo, si desea crear una herramienta que rastree el precio de los artículos en una tienda en línea, deberá agregar alguna capacidad de automatización para que pueda rastrear las tarifas diariamente y agregarlas a su base de datos. Python le brinda la capacidad de automatizar dichos procesos con facilidad.
Visualización de datos: los científicos de datos utilizan mucho el web scraping. Los científicos de datos a menudo necesitan extraer datos de páginas web. Con bibliotecas como Pandas, Python simplifica la visualización de datos a partir de datos sin procesar.
Bibliotecas para Web Scraping en Python
Hay varias bibliotecas disponibles en Python para simplificar el web scraping. Analicemos las tres bibliotecas más populares aquí.
#1. HermosaSopa
Una de las bibliotecas más populares para web scraping. BeautifulSoup ha estado ayudando a los desarrolladores a raspar páginas web desde 2004. Proporciona métodos simples para navegar, buscar y modificar el árbol de análisis. Beautifulsoup también codifica los datos entrantes y salientes. Está bien mantenido y tiene una gran comunidad.
#2. raspado
Otro marco popular para la extracción de datos. Scrapy tiene más de 43000 estrellas en GitHub. También se puede utilizar para extraer datos de las API. También tiene algunos soportes integrados interesantes, como el envío de correos electrónicos.
#3. Selenio
Selenium no es principalmente una biblioteca de web scraping. En cambio, es un paquete de automatización del navegador. Pero podemos extender fácilmente sus funcionalidades para raspar páginas web. Utiliza el protocolo WebDriver para controlar diferentes navegadores. Selenium ha estado en el mercado durante casi 20 años. Pero con Selenium, puede automatizar y extraer fácilmente datos de páginas web.
Desafíos con Python Web Scraping
Uno puede enfrentar muchos desafíos cuando intenta extraer datos de sitios web. Hay problemas como redes lentas, herramientas anti-raspado, bloqueo basado en IP, bloqueo de captcha, etc. Estos problemas pueden causar problemas masivos al intentar raspar un sitio web.
Pero puede evitar los desafíos de manera efectiva siguiendo algunas formas. Por ejemplo, en la mayoría de los casos, un sitio web bloquea una dirección IP cuando hay más de una cierta cantidad de solicitudes enviadas en un intervalo de tiempo específico. Para evitar el bloqueo de IP, deberá codificar su raspador para que se enfríe después de enviar solicitudes.

Los desarrolladores también tienden a colocar trampas de trampas para raspadores. Estas trampas suelen ser invisibles a simple vista, pero se pueden rastrear con un raspador. Si está raspando un sitio web que coloca una trampa trampa, deberá codificar su raspador en consecuencia.
Captcha es otro problema grave con los raspadores. La mayoría de los sitios web hoy en día usan un captcha para proteger el acceso de los bots a sus páginas. En tal caso, es posible que deba usar un solucionador de captcha.
Scraping de un sitio web con Python
Como comentamos, usaremos BeautifulSoup para descartar un sitio web. En este tutorial, extraeremos los datos históricos de Ethereum de Coingecko y guardaremos los datos de la tabla como un archivo JSON. Pasemos a construir el raspador.
El primer paso es instalar BeautifulSoup y Requests. Para este tutorial, usaré Pipenv. Pipenv es un administrador de entornos virtuales para Python. También puedes usar Venv si quieres, pero prefiero Pipenv. Discutir Pipenv está más allá del alcance de este tutorial. Pero si desea aprender cómo se puede usar Pipenv, siga esta guía. O, si desea comprender los entornos virtuales de Python, siga esta guía.
Inicie el shell Pipenv en el directorio de su proyecto ejecutando el comando shell pipenv. Lanzará una subcapa en su entorno virtual. Ahora, para instalar BeautifulSoup, ejecute el siguiente comando:
pipenv install beautifulsoup4
Y, para las solicitudes de instalación, ejecute el comando similar al anterior:
pipenv install requests
Una vez completada la instalación, importe los paquetes necesarios al archivo principal. Cree un archivo llamado main.py e importe los paquetes como se muestra a continuación:
from bs4 import BeautifulSoup import requests import json
El siguiente paso es obtener el contenido de la página de datos históricos y analizarlos utilizando el analizador HTML disponible en BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
En el código anterior, se accede a la página utilizando el método get disponible en la biblioteca de solicitudes. El contenido analizado se almacena luego en una variable llamada sopa.
La parte de raspado original comienza ahora. Primero, deberá identificar la tabla correctamente en el DOM. Si abre esta página y la inspecciona usando las herramientas de desarrollador disponibles en el navegador, verá que la tabla tiene estas clases table-striped text-sm text-lg-normal.
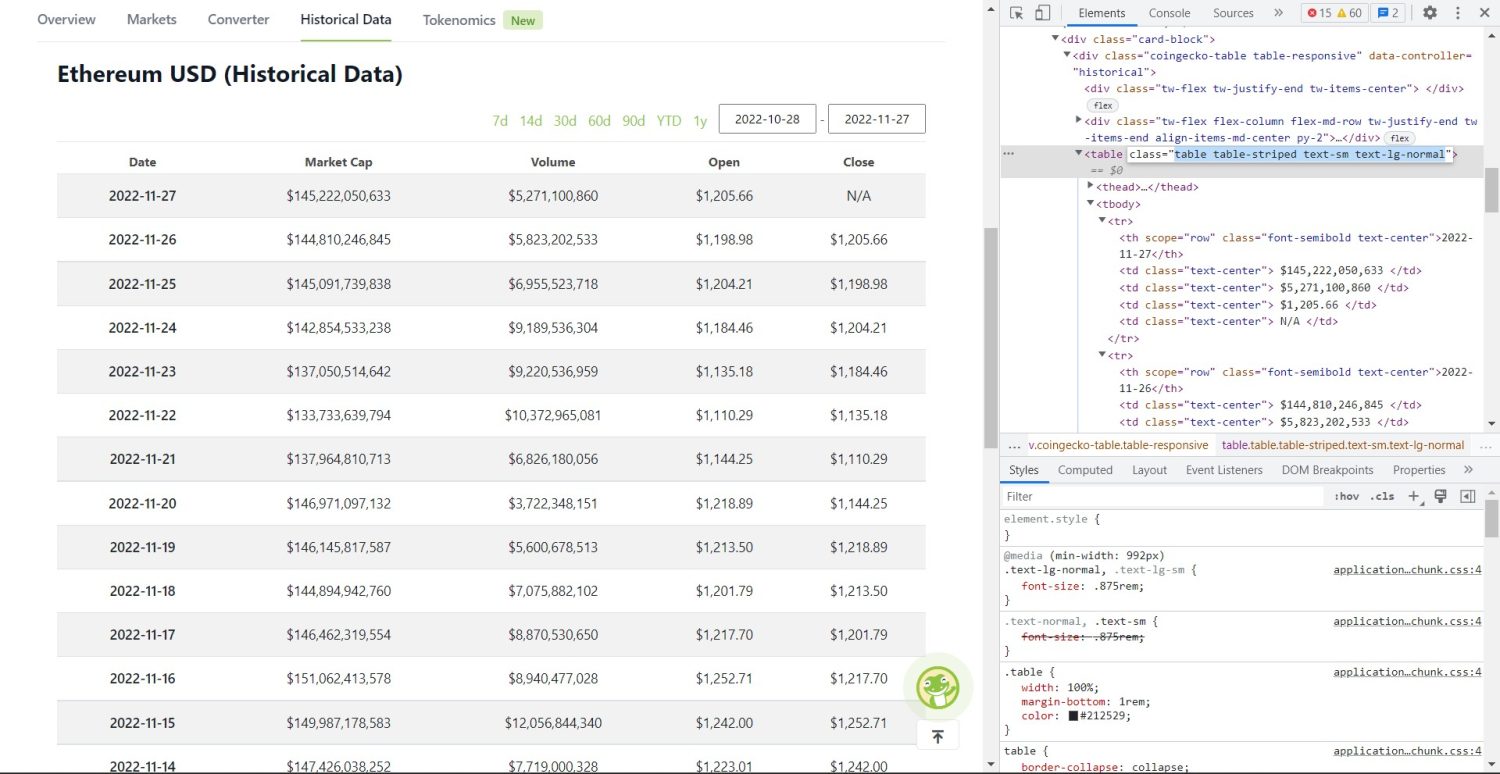 Tabla de datos históricos de Coingecko Ethereum
Tabla de datos históricos de Coingecko Ethereum
Para apuntar correctamente a esta tabla, puede usar el método de búsqueda.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
En el código anterior, primero, la tabla se encuentra usando el método soup.find, luego, usando el método find_all, se buscan todos los elementos tr dentro de la tabla. Estos elementos tr se almacenan en una variable llamada table_data. La tabla tiene algunos elementos th para el título. Se inicializa una nueva variable llamada table_headings para mantener los títulos en una lista.
A continuación, se ejecuta un bucle for para la primera fila de la tabla. En esta fila, se buscan todos los elementos con th y su valor de texto se agrega a la lista table_headings. El texto se extrae utilizando el método de texto. Si imprime la variable table_headings ahora, podrá ver el siguiente resultado:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
El siguiente paso es raspar el resto de los elementos, generar un diccionario para cada fila y luego agregar las filas a una lista.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Esta es la parte esencial del código. Para cada tr en la variable table_data, primero, se buscan los elementos th. Los elementos th son la fecha que se muestra en la tabla. Estos elementos th se almacenan dentro de una variable th. De manera similar, todos los elementos td se almacenan en la variable td.
Se inicializan los datos de un diccionario vacío. Después de la inicialización, recorremos el rango de elementos td. Para cada fila, primero, actualizamos el primer campo del diccionario con el primer elemento de th. El código table_headings[0]: th[0].text asigna un par clave-valor de fecha y el primer elemento.
Después de inicializar el primer elemento, los demás elementos se asignan mediante data.update({table_headings[i+1]: td[i].text.replace(‘n’, ”)}). Aquí, el texto de los elementos td se extrae primero usando el método de texto, y luego todo n se reemplaza usando el método de reemplazo. Luego, el valor se asigna al elemento i+1th de la lista table_headings porque el elemento ith ya está asignado.
Luego, si la longitud del diccionario de datos excede cero, agregamos el diccionario a la lista de detalles de la tabla. Puede imprimir la lista table_details para verificar. Pero escribiremos los valores en un archivo JSON. Echemos un vistazo al código para esto,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Estamos usando el método json.dump aquí para escribir los valores en un archivo JSON llamado table.json. Una vez que se completa la escritura, imprimimos los datos guardados en el archivo json… en la consola.
Ahora, ejecute el archivo usando el siguiente comando,
python run main.py
Después de un tiempo, podrá ver el texto Datos guardados en el archivo JSON… en la consola. También verá un nuevo archivo llamado table.json en el directorio de archivos de trabajo. El archivo tendrá un aspecto similar al siguiente archivo JSON:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Ha implementado con éxito un web scraper utilizando Python. Para ver el código completo, puede visitar este repositorio de GitHub.
Conclusión
Este artículo discutió cómo podría implementar un simple raspado de Python. Discutimos cómo se podría usar BeautifulSoup para extraer datos rápidamente del sitio web. También discutimos otras bibliotecas disponibles y por qué Python es la primera opción para muchos desarrolladores para raspar sitios web.
También puede consultar estos marcos de web scraping.