
El web scraping le permite recopilar eficientemente grandes cantidades de datos de Internet de una manera muy rápida y es particularmente útil en los casos en que los sitios web no exponen sus datos de manera estructurada mediante el uso de interfaces de programación de aplicaciones (API).
Por ejemplo, imagine que está creando una aplicación que compara los precios de artículos en sitios de comercio electrónico. ¿Cómo haría usted para esto? Una forma es verificar manualmente el precio de los artículos en todos los sitios y registrar sus hallazgos. Sin embargo, esta no es una forma inteligente, ya que hay miles de productos en las plataformas de comercio electrónico y tomaría una eternidad extraer datos relevantes.
Una mejor manera de hacerlo es mediante el desguace web. El web scraping es el proceso de extracción automática de datos de páginas web y sitios web mediante el uso de software.
Los scripts de software, conocidos como raspadores web, se utilizan para acceder a sitios web y recuperar datos de ellos. Los datos recuperados, generalmente en forma no estructurada, pueden luego analizarse y almacenarse de una manera estructurada que sea significativa para los usuarios.
El web scraping es muy valioso en la extracción de datos, ya que proporciona acceso a una gran cantidad de datos y permite la automatización, de modo que puede programar su script de web scraping para que se ejecute en ciertos momentos o en respuesta a ciertos desencadenantes. El web scraping también le permite obtener actualizaciones en tiempo real y facilita la realización de investigaciones de mercado.

Muchas empresas y empresas dependen del web scraping para extraer datos para su análisis. Las empresas especializadas en recursos humanos, comercio electrónico, finanzas, bienes raíces, viajes, redes sociales e investigación utilizan el web scraping para extraer datos relevantes de los sitios web.
El propio Google utiliza el web scraping para indexar sitios web en Internet de modo que pueda proporcionar resultados de búsqueda relevantes a los usuarios.
Sin embargo, es importante tener cuidado al realizar el desguace web. Aunque eliminar datos de acceso público no es ilegal, algunos sitios web no lo permiten. Esto podría deberse a que tienen información confidencial del usuario, sus términos de servicio prohíben explícitamente el desguace web o están protegiendo la propiedad intelectual.
Además, algunos sitios web no permiten el web scraping, ya que puede sobrecargar el servidor del sitio web y generar mayores costos de ancho de banda, especialmente cuando el web scraping se realiza a escala.
Para comprobar si un sitio web se puede descartar, agregue robots.txt a la URL del sitio web. robots.txt se utiliza para indicar a los bots qué partes del sitio web se pueden eliminar. Por ejemplo, para comprobar si puedes extraer Google, ve a google.com/robots.txt
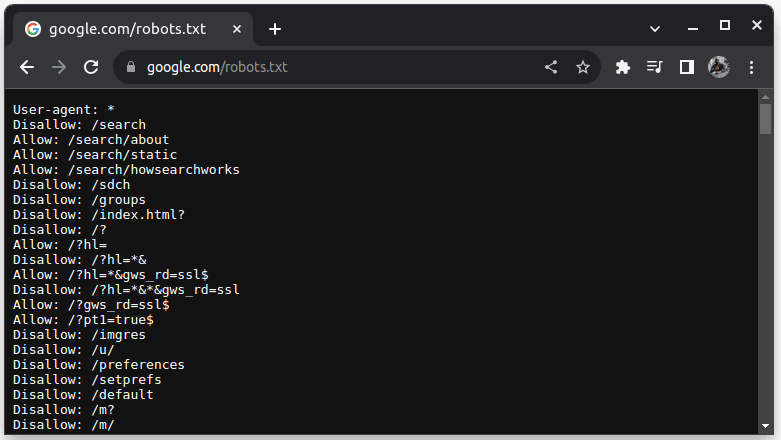
Agente de usuario: * se refiere a todos los bots o scripts y rastreadores de software. Disallow se usa para decirle a los bots que no pueden acceder a ninguna URL en un directorio, por ejemplo /search. Permitir indica directorios desde donde pueden acceder a las URL.
Un ejemplo de un sitio que no permite el scraping es LinkedIn. Para comprobar si puedes eliminar LinkedIn, ve a linkedin.com/robots.txt
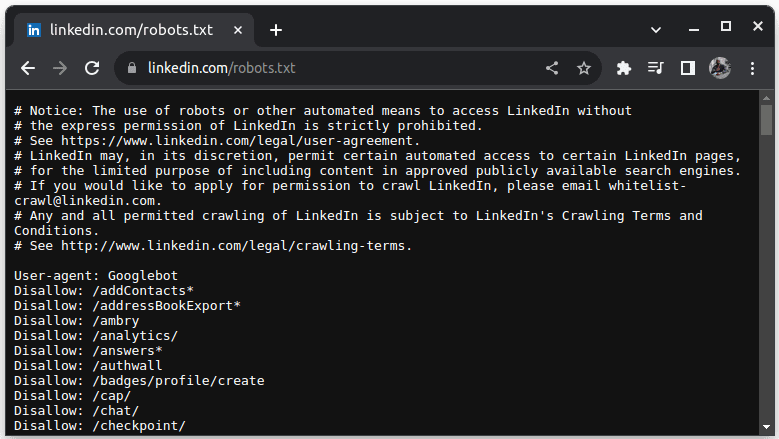
Como puede ver, no puede acceder a LinkedIn sin su permiso. Compruebe siempre si un sitio web permite el scraping para evitar problemas legales.
Tabla de contenido
Por qué Java es un lenguaje adecuado para el web scraping
Mientras que puedes crear un web scraper con una variedad de lenguajes de programación, Java es particularmente ideal para el trabajo por varias razones. En primer lugar, Java tiene un ecosistema rico y una gran comunidad y proporciona una variedad de bibliotecas de web scraping como JSoup, WebMagic y HTMLUnit, que facilitan la escritura de web scraping.

También proporciona bibliotecas de análisis HTML para simplificar el proceso de extracción de datos de documentos HTML y bibliotecas de red como HttpURLConnection para realizar solicitudes a diferentes URL de sitios web.
El sólido soporte de Java para la concurrencia y los subprocesos múltiples también es beneficioso en el web scraping, ya que permite el procesamiento paralelo y el manejo de tareas de web scraping con múltiples solicitudes, lo que le permite extraer varias páginas simultáneamente. Dado que la escalabilidad es una fortaleza clave de Java, puede raspar cómodamente sitios web a gran escala utilizando un raspador web escrito en Java.
El soporte multiplataforma de Java también resulta útil, ya que le permite escribir un raspador web y ejecutarlo en cualquier sistema que tenga una máquina virtual Java compatible. Por lo tanto, puede escribir un web scraper en un sistema operativo o dispositivo y ejecutarlo en un sistema operativo diferente sin la necesidad de modificar el web scraper.
Java también se puede utilizar con navegadores sin cabeza como Headless Chrome, HTML Unit, Headless Firefox y PhantomJs, entre otros. Un navegador sin cabeza es un navegador sin una interfaz gráfica de usuario. Los navegadores sin cabeza pueden simular las interacciones del usuario y son muy útiles para rastrear sitios web que requieren interacciones del usuario.
Para colmo, Java es un lenguaje muy popular y ampliamente utilizado que es compatible y puede integrarse fácilmente con una variedad de herramientas, como bases de datos y marcos de procesamiento de datos. Esto es beneficioso porque garantiza que a medida que extraiga datos, todas las herramientas que necesitará para extraer, procesar y almacenar los datos probablemente sean compatibles con Java.
Veamos cómo podemos usar Java para el desguace web.
Java para Web Scraping: requisitos previos
Para utilizar Java en web scraping, se deben cumplir los siguientes requisitos previos:
1. Java: debe tener Java instalado, preferiblemente la última versión con soporte a largo plazo. En caso de que no tenga Java instalado, vaya a instalar Java para aprender cómo instalar Java en su máquina.
2. Entorno de desarrollo integrado (IDE): debe tener un IDE instalado en su máquina. En este tutorial usaremos IntelliJ IDEA, pero puedes usar cualquier IDE con el que estés familiarizado.
3. Maven: se utilizará para la gestión de dependencias y para instalar una biblioteca de web scraping.
En caso de que no tengas Maven instalado, puedes instalarlo abriendo la terminal y ejecutando:
sudo apt install maven
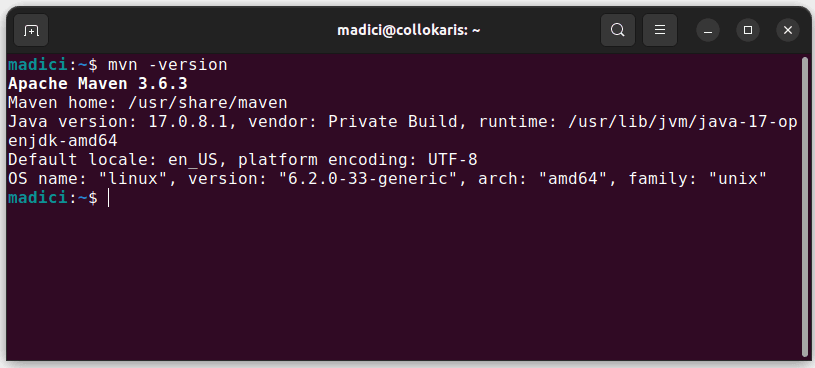
Esto instala Maven desde el repositorio oficial. Puede confirmar que Maven se instaló correctamente ejecutando:
mvn -version
En caso de que la instalación se haya realizado correctamente, debería obtener el siguiente resultado:
Configurar el entorno
Para configurar su entorno:
1. Abra IntelliJ IDEA. En la barra de menú de la izquierda, haga clic en Proyectos y luego seleccione Nuevo proyecto.
2. En la ventana Nuevo proyecto que se abre, rellénela como se muestra a continuación. Asegúrese de que el idioma esté configurado en Java y el sistema de compilación en Maven. Puede darle al proyecto el nombre que prefiera y luego usar Ubicación para especificar la carpeta donde desea crear el proyecto. Una vez hecho esto, haga clic en Crear.
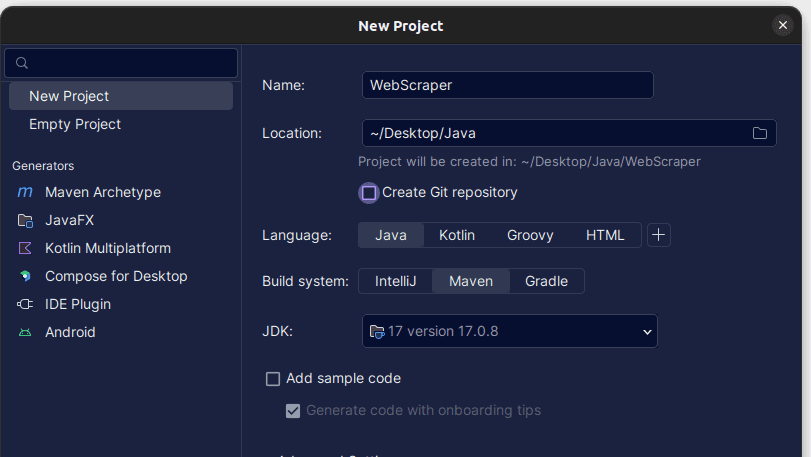
3. Una vez creado su proyecto, debería tener un pom.xml en su proyecto como se muestra a continuación.
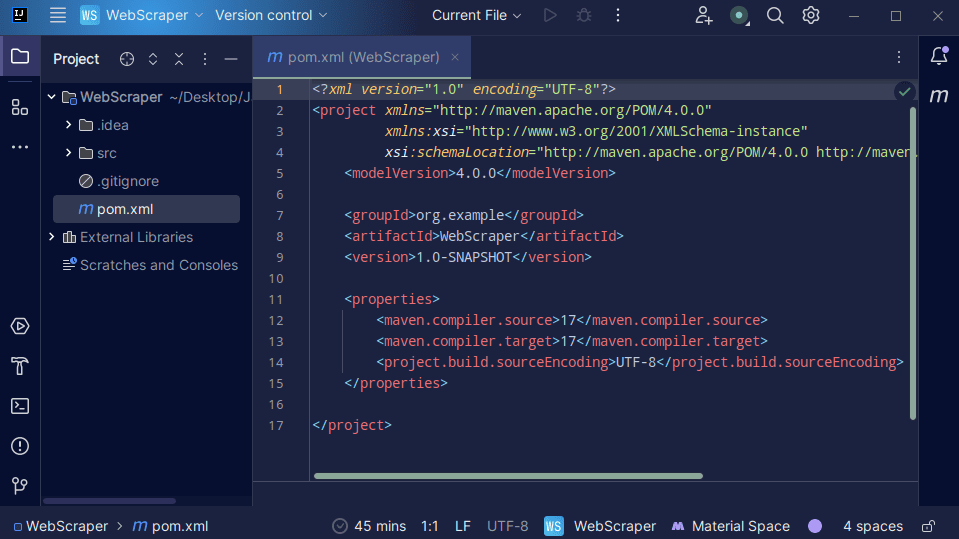
Maven crea el archivo pom.xml y contiene información sobre el proyecto y detalles de configuración utilizados por Maven para construir el proyecto. Es este archivo el que también usamos para indicar que usaremos bibliotecas externas.
Al crear un raspador web, usaremos la biblioteca jsoup. Por lo tanto, debemos agregarlo como una dependencia en el archivo pom.xml para que Maven pueda ponerlo a disposición en nuestro proyecto.
4. Agregue la dependencia jsoup en el archivo pom.xml copiando el código siguiente y agregándolo a su archivo pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
El resultado debería ser el que se muestra a continuación:
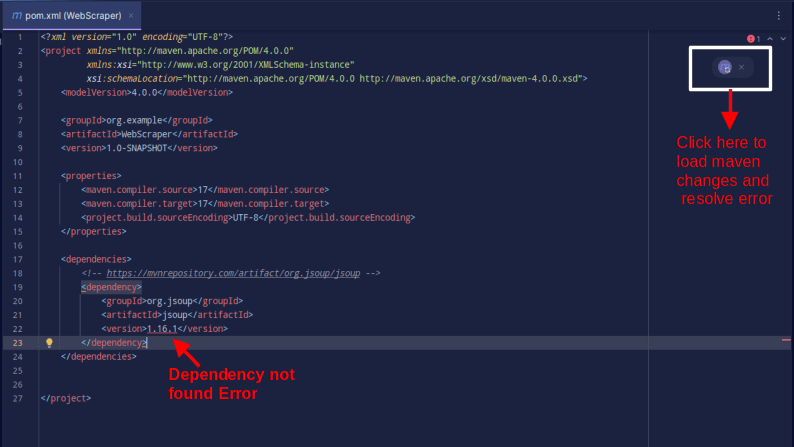
En caso de que encuentre un error que indique que no se puede encontrar la dependencia, haga clic en el icono indicado para que Maven cargue los cambios realizados, cargue la dependencia y elimine el error.
Con eso, tu entorno está completamente configurado.
Raspado web con Java
Para el web scraping, vamos a extraer datos de Raspe este sitioque proporciona una zona de pruebas donde los desarrolladores pueden practicar el web scraping sin encontrarse con problemas legales.
Para raspar un sitio web usando Java
1. En la barra de menú de la izquierda de IntelliJ, abra el directorio src y luego el directorio principal, que se encuentra dentro del directorio src. El directorio principal contiene un directorio llamado java; haga clic derecho sobre él y seleccione Nuevo, luego Clase Java
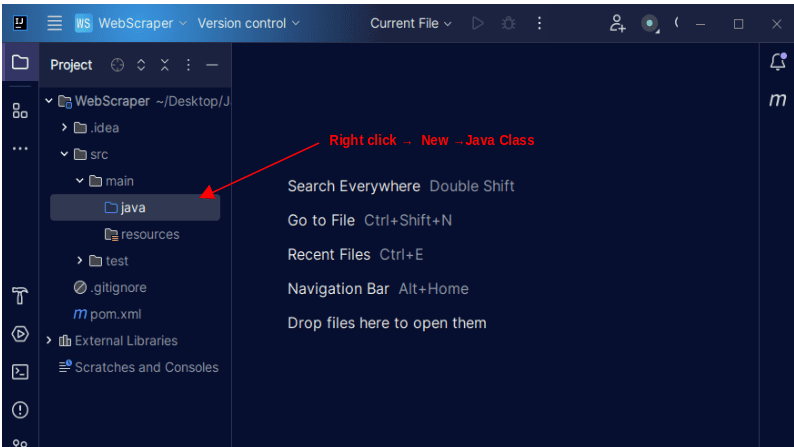
Asigne a la clase el nombre que desee, como WebScraper, luego presione Entrar para crear una nueva clase Java.
Abra el archivo recién creado que contiene las clases Java que acaba de crear.
2. El web scraping implica obtener datos de sitios web. Por lo tanto, debemos especificar la URL de la que queremos extraer datos. Una vez que especificamos la URL, debemos conectarnos a la URL y realizar una solicitud GET para recuperar el contenido HTML de la página.
El código que hace esto se muestra a continuación:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Producción:
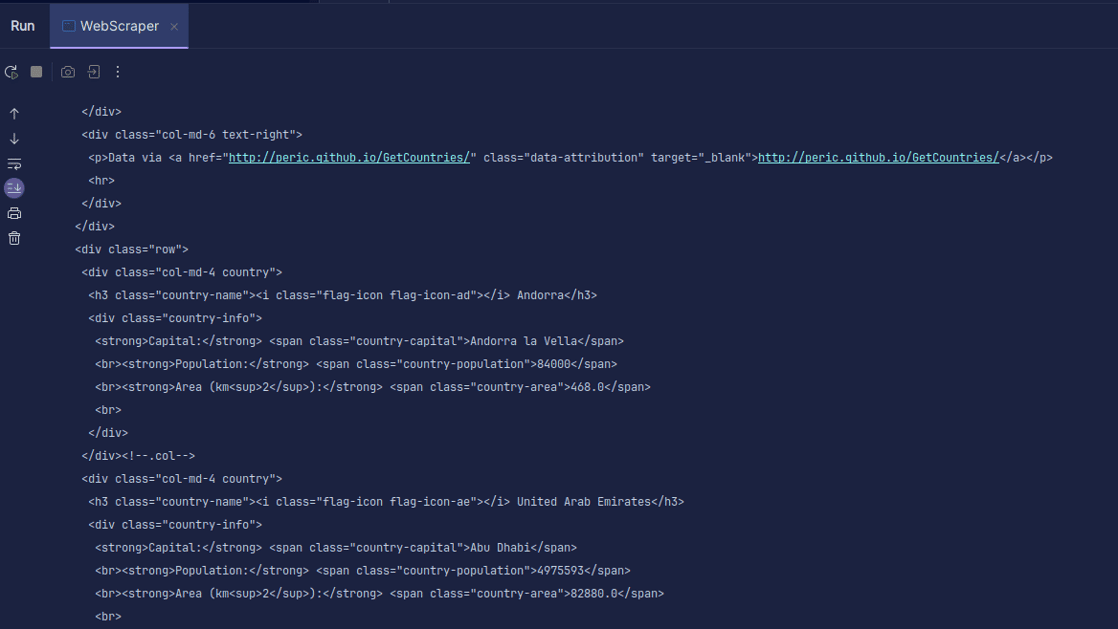
Como puede ver, se devuelve el HTML de la página y es lo que estamos imprimiendo. Al realizar el scraping, la URL que especifique puede tener un error y es posible que el recurso que está intentando extraer no exista en absoluto. Por eso es importante envolver nuestro código en una declaración try-catch.
La línea:
Document doc = Jsoup.connect(url).get();
Se utiliza para conectarse a la URL que desea extraer. El método get() se utiliza para realizar una solicitud GET y recuperar el HTML de la página. El resultado devuelto luego se almacena en un objeto de documento JSOUP, denominado doc. Almacenar el resultado en un documento JSOUP le permite utilizar la API JSOUP para manipular el HTML devuelto.
3. Ir a Raspe este sitio e inspeccionar la página. En el HTML, debería ver la estructura que se muestra a continuación:
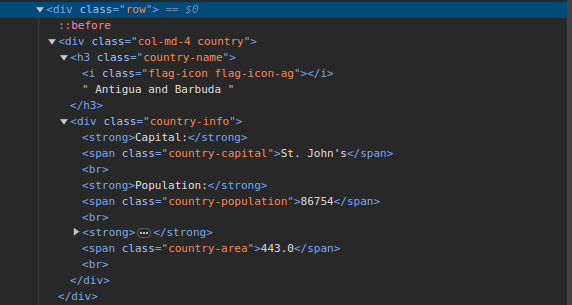
Observe que todos los países de la página se almacenan bajo una estructura similar. Hay un div con una clase llamada país con un elemento h3 con una clase de nombre-país que contiene el nombre de cada país en la página.
Dentro del div principal, hay otro div con una clase de información del país y contiene información como capital, población y área del país. Podemos usar estos nombres de clases para seleccionar los elementos HTML y extraer información de ellos.
4. Extraiga contenido específico del HTML de la página utilizando las siguientes líneas:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Estamos usando el método select() para seleccionar elementos del HTML de la página que coincidan con el selector CSS específico que pasamos. En nuestro caso, pasamos los nombres de las clases. Al inspeccionar la página, vimos que toda la información del país en la página está almacenada en un div con una clase de país.
Cada país tiene su propio div con una clase de país y el div contiene información como el nombre del país, la ciudad capital y la población.
Por lo tanto, primero seleccionamos todos los países de la página usando la clase .country. Luego almacenamos esto en una variable llamada países de tipo Elementos, que funciona como una lista. Luego usamos un bucle for para recorrer los países y extraer el nombre del país, la ciudad capital y la población e imprimir lo que se encuentra.
Toda nuestra base de código se muestra a continuación:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Producción:
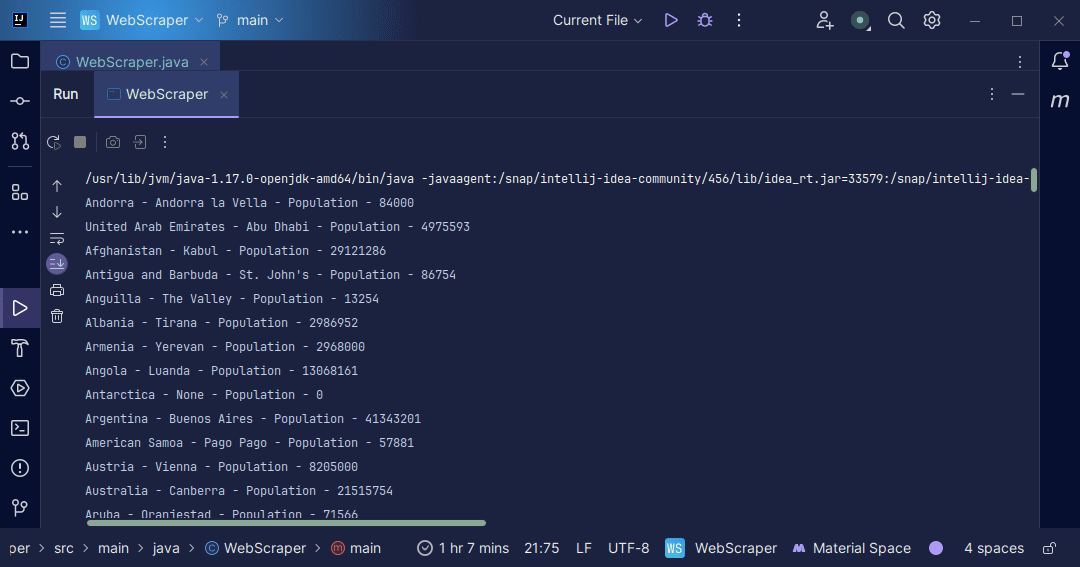
Con la información que obtenemos de la página, podemos hacer una variedad de cosas, como imprimirla como acabamos de hacerlo o almacenarla en un archivo en caso de que queramos realizar más procesamiento de datos.
Conclusión
El web scraping es una excelente manera de extraer datos no estructurados de sitios web, almacenar los datos de forma estructurada y procesarlos para extraer información significativa. Sin embargo, es importante tener cuidado al realizar web scraping, ya que ciertos sitios web no permiten el web scraping.
Para estar seguro, utilice sitios web que proporcionen zonas de pruebas para practicar el desguace. De lo contrario, siempre inspeccione el archivo robots.txt de cada sitio web que desee eliminar para averiguar si el sitio web permite la eliminación.
Al escribir web scrapper, Java es un lenguaje excelente, ya que proporciona bibliotecas que hacen que el web scraping sea más fácil y eficiente. Como desarrollador de Java, crear un web scraper le ayudará a desarrollar aún más sus habilidades de programación. Así que continúa y escribe tu propio scrapper web o modifica el usado en el artículo para extraer diferentes tipos de información. ¡Feliz codificación!
También puede explorar algunas soluciones populares de web scraping basadas en la nube.